Software Configuration Management
Status: Done accept for one minor part which is marked WRITEME.
Last changed: Saturday 2015-01-10 18:32 UTC
Abstract:
SCM (Source Code Management) can be understood as being a subset of SCM (Software Configuration Management) which in turn is part of CM (Configuration Management). Note that from now on, when the acronym SCM is used on this page, it refers to Software Configuration Management rather than Source Code Management. SCM concerns itself with answering the question: somebody did something, how can we reproduce it? Often the problem involves not reproducing "it" identically, but with controlled, incremental changes. Answering the question will thus become a matter of comparing different results and analyzing their differences. SCM is a "set of activities designed to control change by identifying the work products that are likely to change, establishing relationships among them, defining mechanisms for managing different versions of these work products, controlling the changes imposed, and auditing and reporting on the changes made." In other words, SCM is a methodology to control and manage a software development process.
|
Table of Contents
|
A few introducing words...
- Well, as I always start out with the FAQ whenever I enter new
ground, the reader might do that too. Since this page is mainly
about GIT (= a random three-letter combination), it also links to
GIT's FAQs simply because providing them here again would make no
sense.
- A lot of people seem to dislike/mistrust GIT before they get
converted — happened to me too. Now I am convinced by GIT and
rightly so (see rationale below). I see things as they are and one
thing where GIT critics are right is, there is pretty much no
quickstart documentation when it comes to How do I get my local
repository changes published? As of now (February
2009) we still have to first create a so-called bare repository
locally and then use tools like e.g.
scp, rsync, sftp, etc. in
order to move it to some remote server. More on that here. From my
point of view this really is the only weak spot GIT has. For all
the rest... well, see below...
- One thing that I am really, really, REALLY tired of reading all
over the Internet is that GIT's documentation is so utterly bad and
circular because it talks of bare repositories, refs, reflogs and
refspecs all the time but never explains it. GIT's documentation is
outstanding and it is not circular and the reason why things like
refspecs are referenced all the time is because those are part of
the core concept of GIT. So, those who are moaning and chatter
nonsense, please take your time and simply read.
- Those who are looking for how to publish a GIT repository i.e. put
a repository on some server so folks can push/pull to/from it
should go here.
- Since this page provides a lot of information, those who are
looking for a quickstart should follow me down the rabbit hole.
My Notions on the Matter
For those who want to know what SCM systems are out there and how they
compare — there is a list of SCM systems as well as a comparison
available. There is also a comparison among SVN and GIT available.
As of now (August 2008), I mainly use GIT (= a random three-letter
combination) to manage code and to do all kinds of work related to
software/data on my computer systems. Before that, my main code
revision and management system for about two years or so had been SVN
(Subversion). And even before that I used a greater variety of SCM
(Software Configuration Management) systems including CVS (Concurrent
Versions System), GNU Arch and Darcs.
The situation now is that I use mainly GIT and SVN and a little bit of
CVS and GNU Arch every now and then. GIT is used for my own projects
and those I actively contribute to. I also contribute to projects
using SVN but for the most part SVN usage is limited to get the SVN
HEAD from the remote repository to my local working copy. CVS and GNU
Arch is only used for updating the local working copies only — I do
not use them for active development anymore.
Roughly speaking, the reason why I ended up only using two (one to be
more precisely) SCM systems actively now is that, for some time now, I
try to consolidate pretty much everything. Also, I abandoned every
redundancy I could identify because I do not need/want two or more
things providing the same functionality. The gain from doing so is
that one frees up a lot of time for other things plus one gets to know
those things that are left in more detail and thus he is able to work
more efficient.
Why GIT?
It is important to note that GIT is very different from most SCM
systems that we may be familiar with. Subversion, CVS, Perforce,
Mercurial and the like all use Delta Storage systems — they store the
differences between one commit and the next. GIT does not do this —
it stores a snapshot of what all the data in our project looks like in
the tree structure each time we commit. This is a very important
concept to understand when using GIT. Some of the reasons why I
finally favor GIT over all other SCM systems can be told in brief:

- Repository: GIT is a distributed SCM system (as in contrast to e.g.
SVN, also known as Subversion, which is a centralized SCM. Although
one might use SVK on top of SVN, I find that to complicated and
cumbersome plus it still cannot do things GIT can do out of the
box). With Subversion, for each project there is a single
repository at some detached central place where all the history is
and which we checkout and commit into. GIT works differently, each
copy of the project tree (we call that the working copy) carries
its own repository around (in the
.git subdirectory in the project
trees root). So we can have local and remote branches. We can also
have a so-called bare repository which is not attached to a working
copy — that is useful especially when we want to
publish our repository.
- GIT's ability to quickly import and merge patches allows a single
maintainer to process incoming changes even at very high rates.
And when that becomes too much,
git pull provides an easy way for
that maintainer to delegate this job to other maintainers while
still allowing optional review of incoming changes.
- Because of the distributed nature, loosing data because of some
disaster with the central repository is not possible. If there
are n repositories, then there is n-fold redundancy.
- Since every developer's repository has the same complete copy of
the project history, no repository is special, and it is trivial
for another developer to take over maintenance of a project,
either by mutual agreement, or because a maintainer becomes
unresponsive or difficult to work with.
- Another way that GIT (and every other distributed system) helps
to avoid conflicts is a social change that comes out of the
distributed nature of the repositories. Because we are constantly
pulling in from multiple sources, having atomic commits becomes a
requirement to participation. If someone is a nutter and only
makes massive sprawling commits, then we are simply not going to
pull from him. It is not like a centralized system where we are
forced to take all the changes out there.
- The lack of a central group of committers means there is less
need for formal decisions about who is in and who is out.
- Metadata: One thing that is very annoying with SVN is that is
stores its metadata all over the place. GIT on the other hand
stores it in a single
.git folder at the root of the working copy.
Everything is there, we do not have .git folders all over the place
like with SVN and its .svn folders.
- URLs: In Subversion the URL identifies the location of the
repository and the path inside the repository, so we organize the
layout of the repository and its meaning. Normally we would have
../trunk/, ../branches/ and ../tags/ directories. In GIT the URL is
just the location of the repository, and it always contains
branches and tags. One of the branches is the default (normally
named master).
- Revisions: Subversion identifies revisions with IDs (Identifiers)
of decimal numbers growing monotonically which are typically small
(although they can get quickly to hundreds or thousands for large
projects). That is impractical in distributed systems like GIT. GIT
identifies revisions with SHA1 IDs, which are long 160-bit numbers
written in hexadecimal. It may look scary at first, but in practice
it is not a big hurdle — one can refer to the latest revision by
HEAD, its parent as HEAD^ and its grandparent as HEAD^^ or HEAD~2
(we can go on adding carrets), cut and paste helps a lot and we can
write only the few leading digits of a revision (as long as it is
unique), GIT will guess the rest. We can do even more advanced
stuff with revision specifiers, see the git rev-parse manpage for
details.
- Commands: The GIT commands are in the form
git <command>. In the
past, one could interchangeably use the git-<command> form as well.
This is now deprecated and only git <command> is supported anymore
(starting with v1.6). CLI folks on Unix like systems feel intimate
familiarity with GIT as compared to other bloated UIs (User
Interfaces) that come with some SCM systems — with GIT it is easy
to get things going in a short amount of time.
- Commits: Each commit has an author and a committer field, which
record who and when created the change and who committed it (GIT is
designed to work well with patches coming by mail — in that case,
the author and the committer will be different).
- Net: With centralized SCM systems (e.g. SVN), main developers have
to constantly have a high-speed Internet connection in order to do
any useful development. Also, if they want to do fun things like
tracking a function that has moved across several different files,
they are completely out of luck since they have to hit the network
for that information. With GIT we just need the net when we
push/pull to/from a remote branch.
- Speed/Resources: Compared to other SCM systems, GIT is so damn fast
and just needs a fraction of diskspace compared to SCMs I used
before.
- Community: GIT has a very strong and huge community (so has SVN),
thus development and support is excellent whether one tries the IRC
(Internet Relay Chat) channel or the ML (Mailing List) or attends a
sprint.
There are other reasons as well but those are the main reasons why I
find GIT the best solution for me and what I do on a daily basis. It
is even so that I import code from other SCMs into GIT, work on the
code and when I am done, I push the code from GIT back to whatever
upstream SCM system a particular project uses. I cover this further
down...
GIT Glossary and Principles
I decided to intentionally put this not to the end of the page put
here. Best would be to skim over it once, then go read the reminder of
the page and finally read it a second time in-depth.
Glossary
- alternate object database
-
Via the alternates mechanism, a repository can inherit part of its
object database from another object database, which is called
alternate.
- bare repository
-
A bare repository is normally an appropriately named directory with a
.git suffix that does not have a locally checked-out copy of any of
the files under revision control. That is, all of the git
administrative and control files that would normally be present in the
hidden .git sub-directory are directly present in the repository.git
directory instead, and no other files are present and checked out i.e.
no working directory etc. Usually publishers of public repositories
make bare repositories available.
- blob object
-
Untyped object, e.g. the contents of a file.
- branch
-
A non-cyclical graph of revisions, i.e. the complete history of a
particular revision, which is called the branch head. The branch heads
are stored in
$GIT_DIR/refs/heads/.
-
A branch is an active line of development. The most recent commit on a
branch is referred to as the tip of that branch. The tip of the branch
is referenced by a branch head, which moves forward as additional
development is done on the branch. A single git repository can track
an arbitrary number of branches, but your working tree is associated
with just one of them (the current or checked out branch), and
HEAD
points to that branch.
- cache
-
Obsolete for index.
- chain
-
A list of objects, where each object in the list contains a reference
to its successor (for example, the successor of a commit could be one
of its parents).
- changeset
-
BitKeeper/cvsps speak for commit. Since git does not store changes,
but states, it really does not make sense to use the term changesets
with git.
- checkout
-
The action of updating the working tree to a revision which was stored
in the object database.
- cherry-picking
-
In SCM jargon, cherry pick means to choose a subset of changes out
of a series of changes (typically commits) and record them as a new
series of changes on top of different codebase. In GIT, this is
performed by
git cherry-pick command to extract the change
introduced by an existing commit and to record it based on the tip of
the current branch as a new commit.
- clean
-
A working tree is clean, if it corresponds to the revision referenced
by the current head. Also see dirty.
- commit
-
As a noun: A single point in the git history; the entire history of a
project is represented as a set of interrelated commits. The word
commit is often used by git in the same places other revision
control systems use the words revision or version. Also used as a
short hand for commit object.
-
As a verb: The action of storing a new snapshot of the project's state
in the git history, by creating a new commit representing the current
state of the index and advancing
HEAD to point at the new commit.
- commit object
-
An object which contains the information about a particular revision,
such as parents, committer, author, date and the tree object which
corresponds to the top directory of the stored revision.
- core git
-
Fundamental data structures and utilities of git. Exposes only limited
source code management tools.
- DAG
-
Directed acyclic graph. The commit objects form a directed acyclic
graph, because they have parents (directed), and the graph of commit
objects is acyclic (there is no chain which begins and ends with the
same object).
- dangling object
-
An unreachable object which is not reachable even from other
unreachable objects; a dangling object has no references to it from
any reference or object in the repository. See here for more
information.
- detached
HEAD -
Normally the
HEAD stores the name of a branch. However, git also
allows you to check out an arbitrary commit that is not necessarily the
tip of any particular branch. In this case HEAD is said to be
detached.
- dircache
-
See index.
- directory
-
The list you get with
ls.
- dirty
-
A working tree is said to be dirty if it contains modifications
which have not been committed to the current branch.
- ent
-
Favorite synonym to tree-ish by some total geeks. Avoid this term, in
order to not to confuse people.
- evil merge
-
An evil merge is a merge that introduces changes that do not appear in
any parent.
- fast forward
-
A fast-forward is a special type of merge where you have a revision
and you are merging another branch's changes that happen to be a
descendant of what you have. In such these cases, you do not make a
new merge commit but instead just update to his revision. This will
happen frequently on a tracking branch of a remote repository.
- fetch
-
Fetching a branch means to get the branch's head ref from a remote
repository, to find out which objects are missing from the local
object database, and to get them, too. See also
man 1 git-fetch.
- file system
-
Linus Torvalds originally designed git to be a user space file system,
i.e. the infrastructure to hold files and directories. That ensured the
efficiency and speed of git.
- git archive
-
Synonym for repository (for arch people).
- grafts
-
Grafts enables two otherwise different lines of development to be
joined together by recording fake ancestry information for
commits. This way you can make git pretend the set of parents a commit
has is different from what was recorded when the commit was
created. Configured via the
.git/info/grafts file.
- hash
-
In GIT's context, synonym to object name.
- head
-
A named reference to the commit at the tip of a branch. Heads are
stored in
$GIT_DIR/refs/heads/, except when using packed refs. (See
man 1 git-pack-refs.)
- HEAD
-
The current branch. In more detail: Your working tree is normally
derived from the state of the tree referred to by HEAD.
HEAD is a
reference to one of the heads in your repository, except when using a
detached HEAD, in which case it may reference an arbitrary commit.
- head ref
-
A synonym for head.
- hook
-
During the normal execution of several GIT commands, call-outs are
made to optional scripts that allow a developer to add functionality
or checking. Typically, the hooks allow for a command to be
pre-verified and potentially aborted, and allow for a
post-notification after the operation is done. The hook scripts are
found in the
$GIT_DIR/hooks/ directory, and are enabled by simply
removing the .sample suffix. More information can be found with man 5
githooks.
- index
-
A collection of files with stat information, whose contents are stored
as objects. The index is a stored version of your working tree. Truth
be told, it can also contain a second, and even a third version of a
working tree, which are used when merging.
- index entry
-
The information regarding a particular file, stored in the index. An
index entry can be unmerged, if a merge was started, but not yet
finished (i.e. if the index contains multiple versions of that file).
- master
-
The default development branch. Whenever we create a git repository,
a branch named master is created, and becomes the active branch. In
most cases, this contains the local development, though that is purely
by convention and is not required.
- merge
-
As a verb: To bring the contents of another branch (possibly from an
external repository) into the current branch. In the case where the
merged-in branch is from a different repository, this is done by first
fetching the remote branch and then merging the result into the
current branch. This combination of fetch and merge operations is
called a pull. Merging is performed by an automatic process that
identifies changes made since the branches diverged, and then applies
all those changes together. In cases where changes conflict, manual
intervention may be required to complete the merge.
-
As a noun: unless it is a fast forward, a successful merge results in
the creation of a new commit representing the result of the merge, and
having as parents the tips of the merged branches. This commit is
referred to as a merge commit, or sometimes just a merge.
- merge base
-
The common ancestor of two or more commits.
- object
-
The unit of storage in git. It is uniquely identified by the SHA1 of
its contents. Consequently, an object can not be changed without
changing its SHA1 hash.
- object database
-
Stores a set of objects, and an individual object is identified by
its object name. The objects usually live in
$GIT_DIR/objects/.
- object identifier
-
Synonym for object name.
- object name
-
The unique identifier of an object. The hash of the object's contents
using the SHA1 (Secure Hash Algorithm 1) and usually represented by
the 40 character hexadecimal encoding of the hash of the object
(possibly followed by a white space).
- object type
-
One of the identifiers commit, tree, tag or blob describing the type
of an object.
- octopus
-
To merge more than two branches (tentacles) into one resulting branch
(head) — thus the octopus metaphor.
- origin
-
The default upstream repository. Most projects have at least one
upstream project which they track. By default origin is used for that
purpose. New upstream updates will be fetched into remote tracking
branches named
origin/name-of-upstream-branch, which you can see using
git branch -r.
- pack
-
A set of objects which have been compressed into one file (to save
space or to transmit them efficiently).
- pack index
-
The list of identifiers, and other information, of the objects in a
pack to assist in efficiently accessing the contents of a pack.
- parent
-
A commit object contains a (possibly empty) list of the logical
predecessor(s) in the line of development, i.e. its parents.
- pickaxe
-
The term pickaxe refers to an option to the diffcore routines that
help select changes that add or delete a given text string. With the
—pickaxe-all option, it can be used to view the full changeset that
introduced or removed, say, a particular line of text. See
man 1 git-diff.
- plumbing
-
Cute name for core git.
- porcelain
-
Cute name for programs and program suites depending on core git,
presenting a high level access to core git. Porcelains expose more of
a SCM interface than the plumbing.
- pull
-
Pulling a branch means to fetch it and merge it. See also
man 1 git-pull.
- push
-
Pushing a branch means to get the branch's head ref from a remote
repository, find out if it is an ancestor to the branch's local head
ref is a direct, and in that case, putting all objects, which are
reachable from the local head ref, and which are missing from the
remote repository, into the remote object database, and updating the
remote head ref. If the remote head is not an ancestor to the local
head, the push fails.
- reachable
-
All of the ancestors of a given commit are said to be reachable from
that commit. More generally, one object is reachable from another if
we can reach the one from the other by a chain that follows tags to
whatever they tag, commits to their parents or trees, and trees to the
trees or blobs that they contain.
- rebase
-
To reapply a series of changes from a branch to a different base, and
reset the head of that branch to the result.
- ref
-
A 40-byte hex representation of a SHA1 or a name that denotes a
particular object. These may be stored in
$GIT_DIR/refs/.
- reflog
-
A reflog shows the local history of a ref. It is a mechanism to record
when the tip of branches are updated. In other words, it can tell you
things like what the 3rd last revision in this repository was, and
what was the current state in this repository, yesterday 9:14pm. See
man 1 git-reflog for details. See here for when a reflog might turn
out to be useful.
- refspec
-
A refspec is used by
git fetch and git push to describe the mapping
between remote refs and local refs. They are combined with a colon in
the format <src>:<dst>, preceded by an optional plus sign, +. For
example: git fetch $URL refs/heads/master:refs/heads/origin means grab
the master branch head from the $URL and store it as my origin branch
head. And git push $URL refs/heads/master:refs/heads/to-upstream means
publish my master branch head as to-upstream branch at $URL. See also
man 1 git-push.
- repository
-
A collection of refs together with an object database containing all
objects which are reachable from the refs, possibly accompanied by
meta data from one or more porcelains. A repository can share an
object database with other repositories via alternates mechanism.
- resolve
-
The action of fixing up manually what a failed automatic merge left
behind.
- revision
-
A particular state of files and directories which was stored in the
object database. It is referenced by a commit object.
- rewind
-
To throw away part of the development, i.e. to assign the head to an
earlier revision.
- SCM
-
Software Configuration Management. As a noun, it mostly describes a
particular tool or set of tools. As a verb it is understood as
literally doing software configuration and along with various
management tasks.
- SHA1 (Secure Hash Algorithm 1)
-
SHA1 hash. And in GIT context a synonym for object name.
- shallow repository
-
A shallow repository has an incomplete history some of whose commits
have parents cauterized away (in other words, git is told to pretend
that these commits do not have the parents, even though they are
recorded in the commit object). This is sometimes useful when you are
interested only in the recent history of a project even though the
real history recorded in the upstream is much larger. A shallow
repository is created by giving the
—depth option to git-clone(1), and
its history can be later deepened with git-fetch(1).
- symref
-
Symbolic reference: instead of containing the SHA1 id itself, it is of
the format
ref: refs/some/thing and when referenced, it recursively
dereferences to this reference. HEAD is a prime example of a symref.
Symbolic references are manipulated with the git-symbolic-ref(1)
command.
- tag
-
A ref pointing to a tag or commit object. In contrast to a head, a tag
is not changed by a commit. Tags (not tag objects) are stored in
$GIT_DIR/refs/tags/. A git tag has nothing to do with a Lisp tag
(which would be called an object type in GIT's context). A tag is most
typically used to mark a particular point in the commit ancestry
chain.
- tag object
-
An object containing a ref pointing to another object, which can
contain a message just like a commit object. It can also contain a
(GPG/PGP) signature, in which case it is called a signed tag object.
- topic branch
-
A regular git branch that is used by a developer to identify a
conceptual line of development. Since branches are very easy and
inexpensive, it is often desirable to have several small branches that
each contain very well defined concepts or small incremental yet
related changes.
- tracking branch
-
A regular git branch that is used to follow changes from another
repository. A tracking branch should not contain direct modifications
or have local commits made to it. A tracking branch can usually be
identified as the right-hand-side ref in a Pull: refspec.
- tree
-
Either a working tree, or a tree object together with the dependent
blob and tree objects (i.e. a stored representation of a working
tree).
- tree object
-
An object containing a list of file names and modes along with refs to
the associated blob and/or tree objects. A tree is equivalent to a
directory.
- tree-ish
-
A ref pointing to either a commit object, a tree object, or a tag
object.
- unmerged index
-
An index which contains unmerged index entries.
- unreachable object
-
An object which is not reachable from a branch, tag, or any other
reference.
- working tree
-
The tree of actual checked out files. The working tree is normally
equal to the
HEAD plus any local changes that you have made but not
yet committed.
Principles
Aside from all the terms used with GIT, it is important to understand
the core principles how GIT works in order to use it successfully.
The nature of a DSCM System
Of course, there are fundamental differences in how centralized and
decentralized SCM systems build and work. This subsection names two
major differences and, from my point of view, advantages of DSCM
systems.
Everything is Local
This is basically true of all the distributed SCM systems, but in my
experience even more so with GIT. There is very little outside of git
fetch, git pull and git push that communicates in any way with
anything other than ones HDD (Hard Disk Drive). This not only makes
most operations much faster than one may be used to, but it also
allows us to work on stuff offline.
That may not sound like a big deal, but many of us often work offline.
Being able to branch, merge, commit and browse history of a project
while on the plane, train or riding with the AEP (Autonomous
Expedition Platform) vehicle trough the Outback while your buddy is
driving, is a big plus that comes with a DSCM system as is GIT.

Even in Mercurial, common commands like hg incoming and hg outgoing
hit the server, whereas with GIT we can fetch all the servers data
before going offline and do comparisons, merges and logs of data that
is on the server but not in wer local branches yet.
This means that it is very easy to have copies of not only our
branches, but also of everyone else's branches that we are working
with in our GIT repository without having to mess up their stuff.
No Single Point of Failure
I already mentioned that above but it is actually so great that I am
talking about it again. One of the coolest features of any of the
Distributed SCMs, GIT included, is that it is distributed. This means
that instead of doing a checkout of the current tip of the source
code, we do a clone of the entire repository.
This means that even if we are using a centralized workflow, every
user has what is essentially a full backup of the main repository,
each of which could be pushed up to replace the main repository in the
event of a hardware failure or software triggered corruption. There is
basically no single point of failure with GIT unless there is only a
single point e.g. a repository that has not been mirrored/cloned by
someone else.
Repository Layout
It is quite interesting and helpful to grasp the big picture about GIT
aside from the daily usage of GIT. Understanding the layout of a GIT
repository and its meaning and implications on daily usage can be very
helpful in avoiding misuse of GIT that may badly affect ones work. man
5 gitrepository-layout is the place to go and read in order to get
informed.
Tree vs. Commit
A tree is a particular object type. It represents a particular
directory state of a working directory whereas a commit represents
that state in time, and explains how we got there.
We create a commit object by giving it the tree that describes the
state at the time of the commit, and a list of parent trees (those
tree states that lead up to the current one).
When we have a piece of code/data under GIT's control and make changes
to it (e.g. editing some text file, removing/adding/altering a bitmap,
etc.), the journey those changes take are in essence like this:
working tree ---> Index ---> HEAD.
I will go into more detail later when we talk about GIT's workflow.
Anyway, there is a number of commands which are useful for keeping
track of what we are about to commit:
git diff: Shows the difference between the working tree and the
index file i.e. changes that would not be included if we ran git
commit now.git diff --cached: Shows the difference between the HEAD and the
index file i.e. what would be committed if we ran git commit now.git diff HEAD: Shows the difference between HEAD and working tree
i.e. what would be committed if we ran git commit -a now.git status: Displays paths that have differences between the index
file and the current HEAD, paths that have differences between the
working tree and the index, and paths in the working tree that are
not tracked by git e.g. because they are matched by a pattern in
some of GIT's ignore files.
Now, the alerted reader might have asked himself already, we can
commit changes all the way from the working tree, over the index,
right into HEAD (repository back end) using git commit -a. We can also
just commit changes which are staged in the index to HEAD using git
commit.
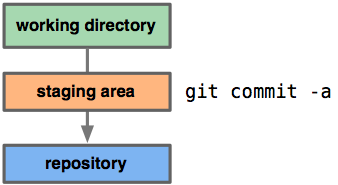
However, how do we get changes from the working tree into the index
without committing them all the way through to HEAD? Why would we need
this one might ask? The reason why we need it can be found here. The
way how to do it is by using git add. This command adds the current
content of new or modified files to the index, thus staging that
content for inclusion in the next commit i.e. by using either one of,
git commit or git commit -a.
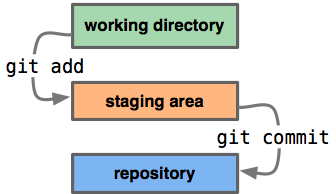
The index holds a snapshot of the content of the working tree, and it
is this snapshot that is taken as the contents of the next commit.
Thus after making any changes to the working directory, and before
running git commit, we must use the git add to add any new/removed or
modified files to/from the index.
Of course, as the best practices example outlined, git add can be
performed multiple times before a commit. It only adds the content of
the specified file(s) at the time git add is run i.e. if we want
subsequent changes included in the next commit, then we must run git
add again to add the new content to the index or use git commit -a.
git add will not add ignored files by default. If any ignored files
were explicitly specified on the command line, git add will fail with
a list of ignored files. Ignored files reached by directory recursion
or filename globbing performed by GIT will be silently ignored.
However, git add -f can be used to add ignored files.
Detailed Look at the Index
Many a times the subject comes up on the mailing list or IRC (Internet
Relay Chat) channel, Why keep the index? or The index is a performance
trick?. The truth is, the index is a staging area. Every SCM system
has it, but GIT explicitly exposes it to us.
A staging area
For those familiar with CVS, SVN or similar archaic stuff, what
happens when we do cvs add our_file followed by cvs commit our_file
is, first command, does not commit the file, right? Where has it gone?
Answer: into the staging area.
With the second command, we can finally commit. But what happens to
the other modified files? Are they committed? The answer is no, the
last revision is updated with the new version of our_file, in the
staging area, and then committed.
So really, it is neither a new concept, nor an intimidating one. The
index comes naturally to us when we issue git add our_file. Now, the
file is in the index.
And here comes the difference to CVS: once we put something into the
index, a simple git diff will only show differences with respect to
the indexed version. Which means that we will not see any differences
to our_file, once we put it into the index. The reason is simple. GIT
assumes that we know what we are doing. If we put something into the
staging area with git add (a porcelain), remove a file with git rm, or
put a modified version of a file into the staging area with git
update-index (a plumbing), GIT assumes that we want to commit this
state, and will not bother us by showing differences we are most
likely not interested in.
One special case exists though. Let us assume we issue git commit
our_file. In this case, GIT assumes that we want to create a
temporary staging area from the tip of the current branch (HEAD),
update our_file, and commit the resulting state. After we committed
that state, the staging area is resurrected as it was before that
commit.
This operation —
save the current staging area, construct a new one,
commit it, and then restore the staging area — seems a bit illogical,
since we would usually expect only one staging area. However, in
practice it happens quite often that we forget to commit something
very important. So, all we have to do is to just edit the respective
files, commit just these, and continue with what we were doing before.
In essence: The index is a staging area for the next commit, but for
convenience, passing filenames explicitely to git commit builds a
temporary staging area from the latest revision and the current
version of the provided files before committing that state.
Merges
Normally, a GIT user will rarely be exposed to the index if he is not
committing a revision. But there is one notable exception: merging.
When we merge the work of others, sometimes conflicts happen. These
are put in the index. Strictly speaking, the whole merge is done
inside the index by inserting the current version, the version of the
branch-to-be-merged, and the merge base into the index, and merging
them using a three-way-diff.
If there are no conflicts, these three entries are collapsed into a
single entry. Otherwise the three entries stay there, with the common
ancestor being replaced by the result of the merge.
Again, GIT is intelligent about what to show us upon a git diff —
those entries which merged cleanly are already updated in the staging
area. It is unlikely that we want to see these differences right now,
because we have to fix up conflicts —if there are any. So, a git diff
will show us a combined diff i.e. a simultaneous diff of the
merged-with-conflicts file against both the current version and the
version in the branch-to-be-merged.
Now we know what the index is good for — as mentioned above, the
index it is neither a new concept, nor an intimidating one. The index
is our friend and companion!
File stages
Assuming two branches contain the same file i.e. my_file — identical
name but different contents. Now we merge these branches (the current
branch and another branch).
Recall that the commit which will be committed after we resolve this
conflict will have two parents instead of the usual one:
- one parent will be
HEAD, the tip of the current branch
- the other will be the tip of the other branch, which is stored
temporarily in
MERGE_HEAD.
During the merge, the index holds three versions of each file. Each of
these three file stages represents a different version of the file:
git show :1:my_file: the file in a common ancestor of both branchesgit show :2:my_file: the version from HEAD, but including any
nonconflicting changes from MERGE_HEADgit show :3:my_file: the version from MERGE_HEAD, but including
any nonconflicting changes from HEAD.
Each time we resolve the conflicts in a file and update the index git
add my_file. The different stages of that file will be collapsed,
after which git diff will (by default) no longer show diffs for that
file.
Installing and Configuring GIT
This section will tell about how to install GIT and how to configure
it afterwards.
Installing GIT
Installing GIT is trivial. Just issue
wks:/home/sa# apt-get install git-core
Reading package lists... Done
Building dependency tree
Reading state information... Done
git-core is already the newest version.
0 upgraded, 0 newly installed, 0 to remove and 2 not upgraded.
wks:/home/sa#
which does the trick and installs GIT. Note, that I already had it
installed.
One might find it a bit strange "Just one package and that is it?
... I do not believe...". This person might take a look at
,----[ apt-file list git-core | grep bin/ ]
| git-core: usr/bin/git
| git-core: usr/bin/git-add
| git-core: usr/bin/git-add--interactive
[skipping a lot of lines...]
| git-core: usr/bin/git-am
| git-core: usr/bin/git-whatchanged
| git-core: usr/bin/git-write-tree
`----
That is the current (Sat Aug 25 16:53:27 UTC 2007) status of the
notable contents of the git-core package. Most folks will not even use
more than 20% of the whole commands available within git-core in their
entire life. I found myself using about twelve commands on a regular
and a few others every now and then.
I strongly recommend to also the package git-doc
sa@wks:~$ acsn git | grep ^git-doc
git-doc - fast, scalable, distributed revision control system (documentation)
sa@wks:~$
For later use you might install more as you need it — DebianGNU/Linux
provides a bunch of GIT related packages
,----[ apt-cache search --names-only git | grep ^git ]
| git - GNU Interactive Tools, a file browser/viewer and process viewer/killer
| git-arch - fast, scalable, distributed revision control system (arch interoperability)
| git-buildpackage - Suite to help with Debian packages in Git repositories
| git-completion - content addressable filesystem (bash completion)
| git-core - fast, scalable, distributed revision control system
| git-cvs - fast, scalable, distributed revision control system (cvs interoperability)
| git-daemon-run - fast, scalable, distributed revision control system (git-daemon service)
| git-doc - fast, scalable, distributed revision control system (documentation)
| git-email - fast, scalable, distributed revision control system (email add-on)
| git-gui - fast, scalable, distributed revision control system (GUI)
| git-load-dirs - Import upstream archives into git
| git-svn - fast, scalable, distributed revision control system (svn interoperability)
| gitk - fast, scalable, distributed revision control system (revision tree visualizer)
| gitweb - fast, scalable, distributed revision control system (web interface)
| git-p4 - fast, scalable, distributed revision control system (p4 interoperability)
`----
Do not get confused about the package git — it has nothing
to do with GIT as you can see
sa@wks:~$ acsn git | grep '^git '
git - GNU Interactive Tools, a file browser/viewer and process viewer/killer
sa@wks:~$
Configure GIT
We will postpone this until we have seen how to carry out basic tasks
with GIT.
Taxonomy
It is so that the GIT community identifies several sets of commands
depending on their abstraction level (high level versus low level) and
if they belong to the core git package or to some ancillary tools. We
name high level (porcelain) commands and low level (plumbing)
commands:
-
Porcelain commands are then further divided into two sets — the main
commands and some ancillary tools. Usually, to work with GIT, the
random user just needs to know the main set within the porcelains —
no ancillary set or some stuff from the plumbing set.
-
Plumbing commands are also further split into subsets — this time
more than just two. Known subsets of plumbings are: Manipulation
commands, Interrogation commands, Synching repositories and Internal
helper commands.
These matters are beyond the scope of this page and will not be
covered since it is only of interest to the power-user or developer.
However, the interested reader might issue man git to dive deeper into
the matter and also actually see what commands are associated with
each of the afore mentioned sets and subsets — of course, categories
and their commands may undergo constant changes as time goes by and
the community works on GIT.
Using GIT
There is lots and lots of information available to all sorts of tasks
one might carry out with GIT. Because of that, I will not provide
another tutorial nor write some documentation. If you are new to GIT
then you might want to take a look at GIT Wikis documentation page
and/or read the GIT user manual. I also strongly recommend to read the
man page i.e. man 7 git and maybe even the documents it refers to
(e.g. repository-layout.html) as needed.
However, I will provide some shortscreen dumps and information on
topics that I needed for myself. This section is split into two
subsections — one covering knowledge that everyone needs on a daily
basis and the second subsection covering some things that look a bit
deeper into what can be done with GIT.
Workflow
This is probably one of the most interesting subsections to read for
folks who are planning on using GIT or maybe have already started
using GIT. Here I will tell about the workflow with regards to GIT
from different angles:
- A low level look at how the local workflow works involving
plumbings. This one can be skipped without missing something.
- Another angle will allow us to look at what is probably a lot more
useful for folks — a high level view on the workflow involving
not just the local repository but also interacting with remote
repositories, this time using GIT's high-level commands also known
as porcelains.
- Last but not least, how GIT can be used for several approaches a
group of people might choose — use GIT in a centralized manner
e.g. as is enforced by SVN or use it in a distributed manner with
intermediate integrate managers which are reviewing and presorting
changes submitted to them before passing on changes to a central
group of folks who finally integrate changes into a central
repository, etc.

Low-level Look a the Local Workflow
Generally, all GIT operations work on the index file. Some operations
work purely on the index file (showing the current state of the
index), but most operations move data to and from the index
file. Either from the database or from the working directory. Thus
there are four main combinations:
- moving data from the working directory to the index
- moving data from the index to the object database
- moving data from the object database to the index
- moving data from the index to the working directory
Below we will look at all of those four combinations, but before we do
so, there is a sketch picturing the local workflow right below:
This piece of ASCII art illustrates how various pieces fit together.
It features the current states (boxes) and the commands to make the
transition from one state to another with the name of the objects at
the current states. Please note that all the commands mentioned below
are not intended to be used by the end user i.e. instead of
git-commit-tree, an end user would use git commit; behind the curtain
though git-commit-tree would be used by GIT.
git-commit-tree
commit obj
+----+
| |
| |
V V
+-----------+
| Object DB |
| Backing |
| Store |
+-----------+
^
git-write-tree | |
tree obj | |
| | git-read-tree
| | tree obj
V
+------------------+
| Index |
+------------------+
^
git-update-index |
blob obj | |
| |
git-checkout-index -u | | git-checkout-index
stat | | blob obj
V
+-----------+
| Working |
| Directory |
+-----------+
Working Directory to Index
We update the index with information from the working directory with
the git-update-index command. We generally update the index
information by just specifying the filename we want to update, like
so: git-update-index filename.
However, to avoid common mistakes with filename globbing etc., the
command will not normally add totally new entries or remove old
entries, i.e. it will normally just update existing cache entries.
To tell git that yes, we really do realize that certain files no
longer exist, or that new files should be added, we should use the
--remove and --add flags respectively.
- Note:
-
A
--remove flag does not mean that subsequent filenames will
necessarily be removed — if the files still exist in our directory
structure, the index will be updated with their new status, not
removed. The only thing --remove means is that git-update-index will
be considering a removed file to be a valid thing, and if the file
really does not exist any more, it will update the index accordingly.
As a special case, we can also do git-update-index --refresh, which
will refresh the stat information of each index to match the current
stat information. It will not update the object status itself, and it
will only update the fields that are used to quickly test whether an
object still matches its old backing store object.
Index to Object Database
We write our current index file to a tree object with git-write-tree.
That does not come with any options — it will just write out the
current index into the set of tree objects that describe that state,
and it will return the name of the resulting top-level tree. We can
then use that tree to re-generate the index at any time by going in
the other direction (object database --> index).
Object Database to Index
We read a tree file from the object database (also known as GIT back
end), and use that to populate (and overwrite i.e. we should not do
this if our index contains any unsaved state that we might want to
restore later!) our current index.
The low-level operation to accomplish this would be git-read-tree
<SHA1_of_tree_object> and our index file will afterwards be equivalent
to the tree that we saved earlier. However, that is only our index
file, our working directory contents have not been modified so far.
Index to Working Directory
We update our working directory from the index by checking out files.
This is not a very common operation, since normally we would just keep
our files updated rather than write to our working directory, we would
tell the index files about the changes in our working directory (i.e.
working-directory --> index respectively git-update-index).
However, if we decide to jump to a new version, or check out somebody
else's version, or just restore a previous tree, we would populate our
index file with git-read-tree, and then we need to check out the
result with git-checkout-index filename or, if we want to check out
all of the index, use also add the -a switch.
- Note:
-
git-checkout-index normally refuses to overwrite old files, so if we
have an old version of the tree already checked out, we will need to
use the -f flag (before the -a flag or the filename) to force the
checkout.
High-Level Look at the Workflow
I suppose this is probably the most interesting subsection within the
workflow section — a high level view on the workflow, involving not
just the local repository but also interacting with remote
repositories, this time using GIT's high-level commands also known as
porcelains.
Instead of going to explain things with words, I opted to have one
picture that pretty much tells us all there is about ones every day
workflow with GIT.
- The image below contains the most commonly used GIT commands. We
can think of it as a cheat sheet with the notion of built-in
workflow information.
- Second to the commands there is graph, depicting the workflow in
chronological order (times goes left to right). This graph shows
the different stages in the workflow, and for each stage lists the
commands specific to a particular stage.
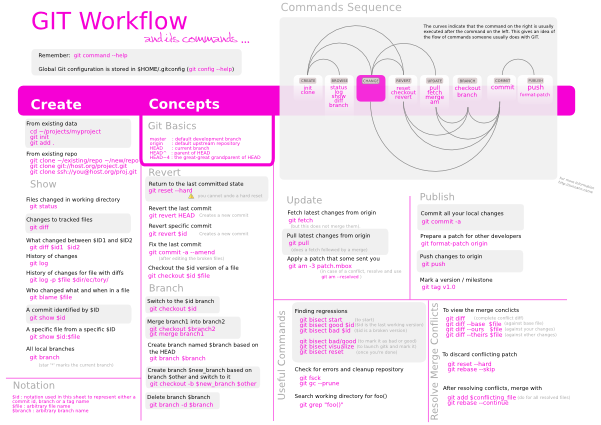
I used Inkscape to create this work. I got asked a lot if I could
provide a PDF — here it is, optimized for DIN A4 for those who would
like to print it. However, the PDF export scrambles the fonts a bit
and so I would recommend to stick with the bitmap.
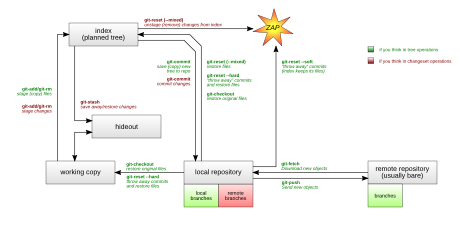
Update: I also found another nice imagery on the net depicting GIT's
high-level workflow
Workflow Models
One of the amazing things about GIT is that because of its distributed
nature and super branching system, we can easily implement pretty
much any workflow we can think of.
Subversion-Style Workflow
A very common GIT workflow, especially from people transitioning from
a centralized system, is a centralized workflow. GIT will not allow us
to push if someone has pushed since the last time we fetched, so a
centralized model where all developers push to the same server works
just fine.
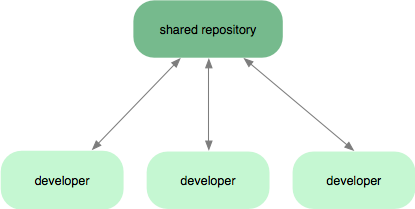
Integration Manager Workflow
Another common GIT workflow is where there is an integration manager
— a single person who commits to the blessed repository, and then a
number of developers who clone from that repository, push to their own
independent repositories and ask the integrator to pull in their
changes. This is the type of development model we often see with open
source repositories.
I also use this model to maintain and further develop this
website/platform i.e. I am the integration manager who solely
maintains the blessed repository where all contributors pull/fetch
from. They make changes, I then fetch from their independent
repositories and so forth.
Of course I am also a contributor aside from being the integration
manager ;-]... Thanks to GIT's mighty branching powers, that is no
problem...
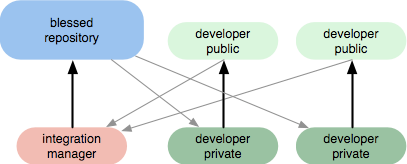
Dictator and Lieutenants Workflow
For more massive projects, we can setup our developers similar to the
way the Linux kernel is run, where people are in charge of a specific
subsystem of the project (the lieutenants) and merge in all changes
that have to do with that subsystem. Then another integrator (the
dictator) can pull changes from only his/her lieutenants and then push
to the blessed repository that everyone then clones from again.
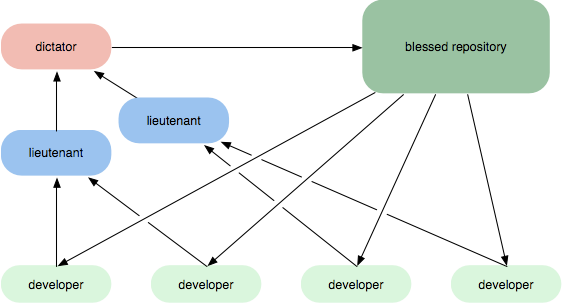
Again, GIT is entirely flexible about this, so we can mix and match
and choose the workflow that is right for us.
Mandatory Knowledge
This subsection is about what I need on a daily basis and thus it is
knowledge that should be known without ever having to look things up.
Getting Help
The best help is what is at our hands at any times. With the git-doc
package installed we have all manual files at our disposal no matter
where we are and what we are doing.
If we have access to the Internet then we might also want to check at
#git at [email protected] (some information how to join IRC) or the
Wiki and probably a hundred other sites on the net including this one.
sa@wks:~$ git --help
usage: git [--version] [--exec-path[=GIT_EXEC_PATH]] [-p|--paginate|--no-pager] [--bare] [--git-dir=GIT_DIR] [--work-tree=GIT_WORK_TREE] [--help] COMMAND [ARGS]
The most commonly used git commands are:
add Add file contents to the index
apply Apply a patch on a git index file and a working tree
archive Create an archive of files from a named tree
bisect Find the change that introduced a bug by binary search
branch List, create, or delete branches
checkout Checkout and switch to a branch
cherry-pick Apply the change introduced by an existing commit
clone Clone a repository into a new directory
commit Record changes to the repository
diff Show changes between commits, commit and working tree, etc
fetch Download objects and refs from another repository
grep Print lines matching a pattern
init Create an empty git repository or reinitialize an existing one
log Show commit logs
merge Join two or more development histories together
mv Move or rename a file, a directory, or a symlink
prune Prune all unreachable objects from the object database
pull Fetch from and merge with another repository or a local branch
push Update remote refs along with associated objects
rebase Forward-port local commits to the updated upstream head
reset Reset current HEAD to the specified state
revert Revert an existing commit
rm Remove files from the working tree and from the index
show Show various types of objects
show-branch Show branches and their commits
status Show the working tree status
tag Create, list, delete or verify a tag object signed with GPG
(use 'git help -a' to get a list of all installed git commands)
sa@wks:~$
The person who knows and understands these commands (the main set from
porcelains) can pretty much do anything he ever wants to do. All the
rest that git offers is thought to be beyond the scope of the
every-day-users needs. If we need anything aside from the above then
we can simply go look it up in the man files or elsewhere.
I know the above commands, use them on a daily basis from the CLI
(Command Line Interface) or even better, I use the emacs frontend and
it is not often that I have to use some other commands except for
maintenance on repositories matters.
In order to get help about a particular command e.g. log one might
issue git --help log which brings up the particular man page for
git log.
Creating A New Repository
With this subsection, I will show how to create a new repository in a
few ways depending on the current situation where we start from.
From a Common Directory:
Usually people have their directory structure already in place when
they start out using GIT — thus they want to bring their file system
or parts of it under version control with GIT.
1 sa@wks:~$ cd /tmp/
2 sa@wks:/tmp$ mkdir commondir
3 sa@wks:/tmp$ cd commondir/
4 sa@wks:/tmp/commondir$ cp /ws/local/scm.muse .
5 sa@wks:/tmp/commondir$ la
6 total 96
7 drwxr-xr-x 2 sa sa 4096 2007-09-13 14:10 .
8 drwxrwxrwt 20 root root 12288 2007-09-13 14:10 ..
9 -rw-r--r-- 1 sa sa 74463 2007-09-13 14:10 scm.muse
10 sa@wks:/tmp/commondir$
Nothing unusual here. All I did was to create a new directory (line 2)
and copy a file into it (line 4). For now the directory contains only
this particular file as we can see in lines 6 to 9. There is no
repository in place so far.
11 sa@wks:/tmp/commondir$ git init
12 Initialized empty git repository in .git/
13 sa@wks:/tmp/commondir$ git add .
14 sa@wks:/tmp/commondir$
line 11. This command creates an empty GIT repository — basically a
.git directory with subdirectories for objects, refs/heads, refs/tags,
and template files. An initial head file that references the head of
the master branch is also created. The command in line 13 adds
(recursively) the current directory contents of new or modified files
in the working tree to the index, thus staging those content for
inclusion in the next commit. Those who do not know what a working
tree, index and commit determines in GIT jargon, go read the glossary
again.
We now have a fully functional GIT repository with content already
under version control. GIT needs to store all information about the
repository in .git as we can see in lines 15 to 28. The contents of
.git are also called repository layout or just layout for short.
15 sa@wks:/tmp/commondir$ la .git/
16 total 44
17 drwxr-xr-x 7 sa sa 4096 2007-09-13 15:09 .
18 drwxr-xr-x 3 sa sa 4096 2007-09-13 15:08 ..
19 drwxr-xr-x 2 sa sa 4096 2007-09-13 15:08 branches
20 -rw-r--r-- 1 sa sa 92 2007-09-13 15:08 config
21 -rw-r--r-- 1 sa sa 58 2007-09-13 15:08 description
22 -rw-r--r-- 1 sa sa 23 2007-09-13 15:08 head
23 drwxr-xr-x 2 sa sa 4096 2007-09-13 15:08 hooks
24 -rw-r--r-- 1 sa sa 104 2007-09-13 15:09 index
25 drwxr-xr-x 2 sa sa 4096 2007-09-13 15:08 info
26 drwxr-xr-x 5 sa sa 4096 2007-09-13 15:09 objects
27 drwxr-xr-x 4 sa sa 4096 2007-09-13 15:08 refs
28 sa@wks:/tmp/commondir$
Time for a short recap. We created a directory, populated it with
content (scm.muse), created a GIT repository and last but not least,
we put the contents of our directory under version control. We did not
make any changes to the contents so far thus the working tree and the
index must be the same. Let us check...
29 sa@wks:/tmp/commondir$ git status
30 # On branch master
31 #
32 # Initial commit
33 #
34 # Changes to be committed:
35 # (use "git rm --cached <file>..." to unstage)
36 #
37 # new file: scm.muse
38 #
39 sa@wks:/tmp/commondir$
As we can see, we are currently on/in the master branch (line 30) of
our repository. As I said above, line 34 tells us that there is
nothing to be committed from the index (formerly known as directory
cache) to GITs back end (which roughly speaking consists of the
references and the object database) since nothing changed in the
working tree — the index and the working tree are the same at this
point in time.
-
The reader might take a look at the workflow as well as here, in order
to better understand the three stages.
40 sa@wks:/tmp/commondir$ git diff
41 sa@wks:/tmp/commondir$ git diff --cached
42 sa@wks:/tmp/commondir$ git diff HEAD
43 sa@wks:/tmp/commondir$
To proof what I said above (all three stages in the repository
(working tree, index, back end) contain the same at this point in time
i.e. the working tree is clean) I issued lines 40 to 43.
Line 40 shows that there are no differences between the working tree
and the index. Line 41 tells us that there are no differences between
the index and the latest commit (if there is no explicit commit
specified — as is here — it points to the current active branch
HEAD). Finally we ask for differences between the working tree and
HEAD — also, there are none. For further information on this matter
one might just issue man 1 git-diff.
- Best Practices
-
A marginal note on
git diff versus git diff --cached: git diff shows
the difference between the working tree and the index file i.e.
changes that would not be included if we ran git commit now. git diff
--cached shows the difference between the HEAD and the index file i.e.
what would be committed if we ran git commit now.
-
We can use that fact to do intermediate validations of our code while
writing a long patch i.e. to make changes in the working tree, check
with
git diff that it is okay, use git add to stage it and continue
until we have finished all intermediate work.
-
I use that when I have several steps and when the intermediate steps
do not deserve to be committed (e.g. regression, uncompilable code,
etc.). For example, this whole website/platform is managed using GIT.
When I am about to fix a bunch of typos, I do not make a commit for
any typo simply because that would create a commit message for any
typo which would be a sick thing to do — for such trivia as for
example typos, I stash away current work, fix the trivia, and return
afterwards.
-
Rather, I fix typos, one after another and add the changes to index
every 10 or so typos. If typos are scattered over several pages, I add
the changes to the index whenever I am done with a particular
page/paragraph/etc.). Finally, when I am done fixing typos for the
day, I make a single commit with one and only one commit message (see
line 44 for an example) by committing from the index to the back end.
This is good practice exactly how anybody should work.
-
In addition to what I just said, one should also take a look at what
general considerations we should obey.
Finally, we have to commit the changes. Of course, we have not made
changes so far but the GIT back end is empty at that point — it does
not know about the index and the repository contents. Running git init
just created the blank GIT repository. For now, the working tree and
the index know about scm.muse (the repository contents) but not the
GIT back end.
Line 44 shows how to commit changes made to the repository. Actually
what we do is using git commit to store the current contents of the
index in a new commit along with a log/commit message describing the
changes we have made to the repository.
44 sa@wks:/tmp/commondir$ git commit -m "This is the inital commit."
45 Created initial commit a4325c8: This is the inital commit.
46 1 files changed, 2235 insertions(+), 0 deletions(-)
47 create mode 100644 scm.muse
48 sa@wks:/tmp/commondir$
Note the -m switch in line 44. This switch is used to provide the log
message from the CLI (Command Line Interface) instead of using an
editor which is started by default. Here the commit message is just a
one liner and does not describe anything special but please keep in
mind how a decent log/commit message should look like.
Line 45 shows the SHA1 hash (a4325c8) which, from now on uniquely
identifies this particular commit along with the commit message. Line
46 just gives a summary of the commit — one file (scm.muse) which
currently has 2235 lines has been committed. Line 47 tells about the
type and permissions on scm.muse, something we can verify with a
little helper command of mine:
sa@wks:/tmp/commondir$ lsO scm.muse
name
file type
octal permissions
human readable permissions
group name owner
user name owner
size in bytes
scm.muse
regular file
644
-rw-r--r--
sa
sa
81330
sa@wks:/tmp/commondir$
lsO is an alias in my ~/.bashrc. As can be seen, scm.muse is a regular
file with octal permissions 644 thus line 47 above. The reason why it
finally ends up as 100644 is #define __S_IFREG 0100000 /* Regular
file. */ — those who are deeply interested might just walk the
GIT source at this point — I am not going to cover this since it is
out of scope for this page.
Last but not least, we check the last commit we did. Line 49 issues
the command. Line 50 shows the commit's unique identifier and line 51
who committed changes. Line 52 is a time stamp and in line 54 we can
see the commit/log message supplied in line 44.
49 sa@wks:/tmp/commondir$ git log
50 commit a4325c8a50f4b277fbc3b255b8d77ceb17e5daad
51 Author: markus gattol <sa@wks>
52 Date: Sat Sep 15 10:31:41 2007 +0100
53
54 This is the inital commit.
55 sa@wks:/tmp/commondir$
From a tarball:
Aside from extracting the tarball, this the same as the former example.
1 sa@wks:/tmp$ mkdir test
2 sa@wks:/tmp$ mv my_tarball.tar.bz2 test/
3 sa@wks:/tmp$ cd test/
4 sa@wks:/tmp/test$ la
5 total 1552
6 drwxr-xr-x 2 sa sa 4096 2007-09-15 18:23 .
7 drwxrwxrwt 21 root root 12288 2007-09-15 18:23 ..
8 -rw-r--r-- 1 sa sa 1568674 2007-09-15 18:22 my_tarball.tar.bz2
9 sa@wks:/tmp/test$ tar -xjf my_tarball.tar.bz2
10 sa@wks:/tmp/test$ la
11 total 1556
12 drwxr-xr-x 3 sa sa 4096 2007-09-15 18:24 .
13 drwxrwxrwt 21 root root 12288 2007-09-15 18:23 ..
14 -rw-r--r-- 1 sa sa 1568674 2007-09-15 18:22 my_tarball.tar.bz2
15 drwxr-xr-x 2 sa sa 4096 2007-09-15 18:22 nose
16 sa@wks:/tmp/test$ cd nose/
17 sa@wks:/tmp/test/nose$ la
18 total 9236
19 drwxr-xr-x 2 sa sa 4096 2007-09-15 18:22 .
20 drwxr-xr-x 3 sa sa 4096 2007-09-15 18:24 ..
21 -rw-r--r-- 1 sa sa 732731 2007-09-15 18:20 bashref.html
22 -rw-r--r-- 1 sa sa 24071 2007-09-15 18:20 crypto.html
23 -rw-r--r-- 1 sa sa 3581730 2007-09-15 18:20 elisp.html
24 -rw-r--r-- 1 sa sa 3035824 2007-09-15 18:20 emacs.html
25 -rw-r--r-- 1 sa sa 823905 2007-09-15 18:20 emacs-lisp-intro.html
26 -rw-r--r-- 1 sa sa 1159227 2007-09-15 18:20 texinfo.html
27 -rw-r--r-- 1 sa sa 52965 2007-09-15 18:20 vserver_configuration.html
28 sa@wks:/tmp/test/nose$ git init
29 Initialized empty Git repository in .git/
30 sa@wks:/tmp/test/nose$ git add .
31 sa@wks:/tmp/test/nose$ git commit -m "Intial commit from just extracted tarball."
32 Created initial commit 2b36f4f: Intial commit from just extracted tarball.
33 7 files changed, 166507 insertions(+), 0 deletions(-)
34 create mode 100644 bashref.html
35 create mode 100644 crypto.html
36 create mode 100644 elisp.html
37 create mode 100644 emacs-lisp-intro.html
38 create mode 100644 emacs.html
39 create mode 100644 texinfo.html
40 create mode 100644 vserver_configuration.html
41 sa@wks:/tmp/test/nose$ git log HEAD
42 commit 2b36f4f83dc95d0e05a23f974415f9bd6b55fa66
43 Author: markus gattol <sa@wks>
44 Date: Sat Sep 15 18:25:34 2007 +0100
45
46 Intial commit from just extracted tarball.
47 sa@wks:/tmp/test/nose$
In line 9 we extract the tarball. The was nothing but the tarball in
the ../test directory as we can see in lines 5 to 8. After extracting
in line 9 we got a new directory (../nose) as we can see in line 15.
The contents of it can be seen in lines 18 to 27. The reminder is the
same as we already did above.
From a remote repository:
There is just one command we need to know. In line 1 we are issuing
git clone with the URL (Uniform Resource Locator) that points to the
official GIT repository itself.
1 sa@wks:/tmp$ git clone git://git.kernel.org/pub/scm/git/git.git
2 Initialized empty Git repository in /tmp/git/.git/
3 remote: Counting objects: 92034, done.
4 remote: Compressing objects: 100% (24736/24736), done.
5 remote: Total 92034 (delta 67243), reused 90062 (delta 65711)
6 Receiving objects: 100% (92034/92034), 19.30 MiB | 1743 KiB/s, done.
7 Resolving deltas: 100% (67243/67243), done.
8 sa@wks:/tmp$ du -sh git/
9 36M git/
10 sa@wks:/tmp$
As of now (February 2009) the whole GIT source tree has a size of
about 36 MiB as line 9 shows. Note, that there is no need to run git
init in case we cloned from a remote repository. After git clone the
repository is ready to work with as is.
Importing/Exporting data from/to SVN
Before we actually start, folks familiar to SVN but not GIT might read
the this. Also, I am not going to explicitly cover grafts here.
Install git-svn
Now, in order to import from SVN to GIT we need
sa@wks:~$ dpl git-svn* | grep ^ii
ii git-svn 1:1.6.1.3-1 fast, scalable, distributed revision control
sa@wks:~$
installed. After that, what is the usual case, one creates a GIT
repository by importing from an SVN branch (git-svnimport).
Subsequently one can do bidirectional operations between the
subversion branch and GIT via git-svn.
Importing from SVN to GIT
git-svnimport imports a SVN repository into GIT. It will either create
a new repository, or incrementally import into an existing one. SVN
access is done by the SVN::Perl module. We can check this
sa@wks:~$ which git-svnimport | xargs file
/usr/bin/git-svnimport: perl script text executable
sa@wks:~$
git-svnimport assumes that SVN repositories are organized into one
trunk directory where the main development happens, branches/FOO
directories for branches, and /tags/FOO directories for tags — this
is the default and recommended layout for SVN repositories. Other
subdirectories are ignored. Finally, git-svnimport also creates a file
called .git/svn2git, which is required for incremental SVN imports
into GIT.
There are a bunch of options to git-svnimport. Some of which I think
are more interesting than others are -C <target-dir>, -P
<path_from_trunk> , -s <start_rev>, -T <trunk_subdir>, -t <tag_subdir>
and -b <branch_subdir>.
I am now going to demonstrate how to import code within a remote SVN
repository into a local GIT repository. Therefore I am going to use
rsync to first mirror the repository locally and then do the
checkout from the mirrored local SVN repository into GIT since that is
way faster than using git-svnimport directly against the remote SVN
repository.
1 sa@wks:/tmp/free_nas$ time rsync -avz rsync://freenas.svn.sourceforge.net/svn/freenas/* freenas_svn
2
3 receiving file list... done
4 created directory freenas_svn
5 README.txt
6 format
7 conf/
8 conf/authz
9 conf/passwd
10 conf/svnserve.conf
11 dav/
12
13 [skipping a lot of lines...]
14
15 locks/
16 locks/db-logs.lock
17 locks/db.lock
18
19 sent 82622 bytes received 12498149 bytes 178450.65 bytes/sec
20 total size is 28174045 speedup is 2.24
21
22 real 1m10.264s
23 user 0m0.496s
24 sys 0m0.524s
25 sa@wks:/tmp/free_nas$ du -sh freenas_svn/
26 39M freenas_svn/
27 sa@wks:/tmp/free_nas$
As can be seen in line 1, I issued rsync in conjunction with time
since I wanted to see how long it takes to finish (line 22). Lines 2
to 25 just show the whole downloading process (note the statement in
line 13 — I skipped the majority of the output). Line 26 shows that
we downloaded 39 MiB in ~70 seconds.
Then I tried to directly use git-svnimport on the same remote SVN
repository
sa@wks:/tmp/test$ time git-svnimport -C freenas_git -v https://freenas.svn.sourceforge.net/svnroot/freenas
Initialized empty Git repository in /tmp/test/freenas_git/.git/
Processing from 1 to 1856...
Fetching from 1 to 1001...
1: Unrecognized path: /docs
Tree ID 4b825dc642cb6eb9a060e54bf8d69288fbee4904
Committed change 1:/ 2006-06-13 18:35:33)
Commit ID 0b322615b786db60612b02003af741c3d313ada8
Writing to refs/heads/origin
[skipping a lot of lines...]
... 26 /trunk/www/disks_raid_gvinum.php...
... 26 /trunk/www/disks_raid_gvinum_edit.php...
... 26 /trunk/www/disks_raid_gvinum_info.php...
real 9m22.255s
user 0m1.660s
sys 0m1.404s
sa@wks:/tmp/test$ du -sh freenas_git/
2.3M freenas_git/
sa@wks:/tmp/test$
I did not let it finish since after ~9 minutes I became impatient and
simply used C-c to cancel the ongoing process. As we can see, it took
around 9 minutes to download ~2 MiB. In case this whole thing scales
linear, downloading the 39 MiB would have taken around
sa@wks:/tmp/test/freenas_git$ python
Python 2.4.4 (#2, Aug 16 2007, 02:03:40)
[GCC 4.1.3 20070812 (prerelease) (Debian 4.1.2-15)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> ((9/2)*39)
156
>>>
sa@wks:/tmp/test/freenas_git$
minutes which is totally unacceptable.
The next thing I wanted to try is to just checkout some revisions and
not the whole history — in other words, I am just interested in the
current state.
1 sa@wks:/tmp/free_nas$ svnlook history freenas_svn | head -n3
2 REVISION PATH
3 -------- ----
4 1853 /
5 sa@wks:/tmp/free_nas$ git-svnimport -s 1850 -C freenas_git file:///tmp/free_nas/freenas_svn
6 Initialized empty Git repository in /tmp/free_nas/freenas_git/.git/
7 fatal: Needed a single revision
8 1852: cannot find commit '0.685'!
9 Generating pack...
10 Done counting 16 objects.
11 Deltifying 16 objects...
12 100% (16/16) done
13 Writing 16 objects...
14 100% (16/16) done
15 Total 16 (delta 1), reused 0 (delta 0)
16 Pack pack-eb83e4e47346935a574558bfb8cd7cd4d6a464dc created.
17 Removing unused objects 100%...
18 Done.
19 sa@wks:/tmp/free_nas$ du -sh freenas_git/
20 212K freenas_git/
21 sa@wks:/tmp/free_nas$ cd freenas_git/
22 sa@wks:/tmp/free_nas/freenas_git$ la
23 total 24
24 drwxr-xr-x 6 sa sa 4096 2007-09-17 11:50 .
25 drwxr-xr-x 4 sa sa 4096 2007-09-17 11:50 ..
26 drwxr-xr-x 3 sa sa 4096 2007-09-17 11:50 build
27 drwxr-xr-x 3 sa sa 4096 2007-09-17 11:50 etc
28 drwxr-xr-x 7 sa sa 4096 2007-09-17 11:50 .git
29 drwxr-xr-x 2 sa sa 4096 2007-09-17 11:50 www
30 sa@wks:/tmp/free_nas/freenas_git$
As we can see in line 4 there are 1853 revisions. In line 5 I intended
to check out the last three revisions but this time from the mirrored
SVN repository. Of course, as one might think because of not
retrieving the whole history we run into problems (line 7 and 8).
- Bottom Line on
git-svnimport: -
Since
git svn clone allows to do the same (redundancy) as
git-svnimport, is more capable and I have to use it anyway for
bidirectional operations between SVN and GET, I decided to go entirely
with git-svn and just forget about git-svnimport. However, I also
decided to keep the git-svnimport part on this page since it covers
three nice examples
- Using
rsync to mirror a SVN repository
- Using
git-svnimport against a remote SVN repository
- Using
git-svnimport against a local repository which was mirrored
with rsync
From now on I am doing anything with git-svn instead of git-svnimport...
git-svn allows for bidirectional operations between a single SVN
(Subversion) branch and GIT. git-svn is a simple conduit for
changesets between SVN and GIT. It is not to be confused with
git-svnimport, which is unidirectional (read-only).
git-svn was originally designed for an individual developer who wants
a bidirectional flow of changesets between a single SVN branch and an
arbitrary number of branches in GIT. Since its inception, git-svn has
gained the ability to track multiple branches in a manner similar to
git-svnimport.
git svn clone runs git svn init and git svn fetch at once. It will
automatically create a directory based on the basename of the URL
passed to it or if a second argument is passed along with the URL then
it will create a directory and work within that. One might read the
man page to git-svn at this point (man 1 git-svn).
- Important notes on using
git-svn:
- For the sake of simplicity and interoperating with SVN, it is
recommended that all
git-svn users clone, fetch and dcommit
directly from the SVN server (the remote SVN repository that is),
and avoid all git-clone/pull/merge/push operations between git
repositories and branches which are either retrieved via git svn
clone and which are also used to push back changesets into the
remote SVN repository.
- The recommended method of exchanging code between git branches and
users is
git format-patch and git am, or just git svn dcommit to
the SVN repository.
- Since
git svn dcommit uses git svn rebase internally, any git
branches we git push to before git svn dcommit on them will
require forcing an overwrite of the existing ref on the remote
repository. This is generally considered bad practice, see the
git-push documentation for details.
- Running
git merge or git pull is not recommended on a branch we
plan to git svn dcommit from. SVN does not represent merges in any
reasonable or useful fashion so users using SVN cannot see any
merges we have made. Furthermore, if we git merge or git pull from
a git branch that is a mirror of an SVN branch, git svn dcommit may
commit to the wrong branch.
git clone does not clone branches under the refs/remotes/ hierarchy
or any git-svn metadata, or config. So repositories created and
managed with using git-svn should use rsync for cloning, if cloning
is to be done at all.- We should not use the
--amend option of git commit on a change we
have already dcommitted. It is considered bad practice to --amend
commits we have already pushed to a remote repository for other
users, and dcommit with SVN is analogous to that. More information
on this can be found at Modifying a single commit and
Problems with rewriting history.
The reminder of this subsection is now going to show how to checkout
(full as well as partial checkout) an SVN repository using git-svn.
Afterwards, in the subsection called
Bidirectional Operations between SVN and GIT, I am going to show how
to do all the bidirectional operations between SVN and GIT using
git-svn.
Common SVN Checkout:
Since some time now, I wanted to have the FAI (Fully Automatic
Installation) code in a GIT repository so I am going to do that now
but first I am demonstrating the usual SVN case:
1 sa@wks:/tmp$ svn co svn://svn.debian.org/svn/fai/
2 A trunk/utils
3 A trunk/utils/create-nfsroot-tar
4 A trunk/utils/tlink
5
6 [skipping a lot of lines...]
7
8 A fai/tags/2.8.4sarge1/examples/etc/bootptab
9 A fai/tags/2.8.4sarge1/examples/etc/sources.list
10 Checked out revision 4599.
11
12 real 5m18.425s
13 user 0m17.533s
14 sys 0m14.873s
15 sa@wks:/tmp$ du -sh fai/
16 461M fai/
17 sa@wks:/tmp$ date -u
18 Tue Sep 18 12:31:51 UTC 2007
19 sa@wks:/tmp$
In line 1 shows how to checkout the SVN repository of FAI into a local
working copy. Line 6 indicates that there is a bunch of lines skipped
from the actual checkout since they are of no further interest here.
We can see, there are 4599 revisions so far (line 10) and the whole
working copy has a size of about 461 MiB (line 16) as of now (line
18).
- One major downside of SVN compared to GIT:
-
Of course, because of the nature of SVN — it is a centralized SCM
(Software Configuration Management) — the working copy contains no
history. The history is within the central place on the server hosting
the SVN repository. Using
git svn clone, we get a local GIT
repository with all the history so we can work offline while we are
on the go as we are living on the go.
Full git svn clone Checkout:
1 sa@wks:~/work/git$ time git svn clone svn://svn.debian.org/svn/fai/
2 Initialized empty Git repository in .git/
3 W: +empty_dir: branches
4 W: +empty_dir: tags
5 W: +empty_dir: trunk
6 r1 = d274ebe781031609a12ea15a226c5189adb0bbfe (git-svn)
7 A trunk/kernel/config-2.2.15
8 A trunk/kernel/emptydosdisk.gz
9 A trunk/kernel/imagegen_firstblock
10 A trunk/debian/control
11
12 [skipping a lot of lines...]
13
14 D people/h01ger/faicd/templates/syslinux/pxelinux.cfg
15 D people/h01ger/faicd/templates/syslinux/splash.rle
16 D people/h01ger/faicd/
17 W: -empty_dir: people/h01ger/faicd
18 r4599 = 542524e653ccb051d055034d2f2211001dfc3f2a (git-svn)
19 Checking 14424 files out...
20 100% (14424/14424) done
21 Checked out HEAD:
22 svn://svn.debian.org/svn/fai r4599
23
24 real 52m38.281s
25 user 10m27.819s
26 sys 6m15.283s
27 sa@wks:~/work/git$
Line 1 is how to create (clone) a local GIT repository from a remote
SVN repository. Again, I issued time so that we can see how long it
took (line 24) — note, that compared to the svn co above this takes
longer since we are also retrieving the history plus everything has to
be translated to GIT internals. However, once this is done GIT users
may make fun at SVN folks since there is a difference in speed and
size of repositories which is around one order of magnitude.
I indicated the usual exclusion of output in line 12. If we compare
the revision number in line 18 to the example above (line 10) we can
see they perfectly match.
28 sa@wks:~/work/git$ du -sh fai/
29 274M fai/
30 sa@wks:~/work/git$ ll
31 total 4.0K
32 drwxr-xr-x 7 sa sa 4.0K 2007-09-19 13:00 fai
33 sa@wks:~/work/git$ cd fai/
34 sa@wks:~/work/git/fai$ la
35 total 28
36 drwxr-xr-x 7 sa sa 4096 2007-09-19 13:00 .
37 drwxr-xr-x 3 sa sa 4096 2007-09-19 12:07 ..
38 drwxr-xr-x 3 sa sa 4096 2007-09-19 12:59 branches
39 drwxr-xr-x 9 sa sa 4096 2007-09-19 13:00 .git
40 drwxr-xr-x 9 sa sa 4096 2007-09-19 12:59 people
41 drwxr-xr-x 65 sa sa 4096 2007-09-19 13:00 tags
42 drwxr-xr-x 11 sa sa 4096 2007-09-19 13:00 trunk
43 sa@wks:~/work/git/fai$ time git-gc
44 Generating pack...
45 Counting objects: 4560
46 Done counting 27583 objects.
47 Deltifying 27583 objects...
48 100% (27583/27583) done
49 Writing 27583 objects...
50 100% (27583/27583) done
51 Total 27583 (delta 19160), reused 0 (delta 0)
52 Pack pack-4be8a9921b4eaff77f2b8bf57c8a280941c5bb6b created.
53 Removing unused objects 100%...
54 Done.
55
56 real 2m12.321s
57 user 0m8.353s
58 sys 0m3.288s
59 sa@wks:~/work/git/fai$ cd ..
60 sa@wks:~/work/git$ du -sh fai/
61 146M fai/
62 sa@wks:~/work/git$
In lines 28 and 29, we check the size of our just created GIT
repository. In line 30 I am just using an alias in my ~/.bashrc. After
changing into the local fai repository (line 33) I am looking at its
contents (lines 34 to 42). In line 43 I decided to run some
optimizations — check out man 1 git-gc or what I say below, for
further information. Running git gc took ~2 minutes as wee can see in
line 56. Then, big surprise in line 61 — GIT is smart! GIT is so
smart that we do not need 461MiB (svn checkout above) on our HDD but
just 146MiB. No commit, no history, not a bit of information got lost
... again, GIT is smart!
Partial git svn clone Checkout:
This is pretty much the same as with the full checkout above.
1 sa@wks:/tmp/pco$ time git svn clone svn://svn.debian.org/svn/fai -r HEAD
2 Initialized empty Git repository in .git/
3 A trunk/utils/create-nfsroot-tar
4 A trunk/utils/tlink
5 A trunk/utils/prtnetgr
6
7 [skipping a lot of lines...]
8
9 A tags/2.8.4sarge1/examples/etc/hosts
10 A tags/2.8.4sarge1/examples/etc/netgroup
11 A tags/2.8.4sarge1/examples/etc/dhcpd.conf
12 A tags/2.8.4sarge1/examples/etc/bootptab
13 A tags/2.8.4sarge1/examples/etc/sources.list
14 W: +empty_dir: people/Mrfai
15 W: +empty_dir: people/eartoast/bugfix
16 W: +empty_dir: people/lazyboy/rhel-install-fixes_3.1.8/examples/rhel-install-d
17 emo/basefiles
18 W: +empty_dir: people/lazyboy/rhel-install-fixes_3.1.8/examples/rhel-install-d
19 emo/files/opt/apache-tomcat-6.0.13/conf/tomcat-users.xml
20 W: +empty_dir: people/mugwump/vserver/examples/simple/files/etc/resolv.conf
21 r4599 = 63f8800b68f22ef70ed3cce056cb42bec8e8ea8f (git-svn)
22 Checking 14424 files out...
23 100% (14424/14424) done
24 Checked out HEAD:
25 svn://svn.debian.org/svn/fai r4599
26
27 real 6m35.551s
28 user 0m32.238s
29 sys 1m9.244s
As we can see, pretty much the same as the full checkout. Note the -r
HEAD in line 1. Also note how long it took (line 27) compared to the
example of the full checkout before (that was around 52 minutes).
30 sa@wks:/tmp/pco$ ll
31 total 4.0K
32 drwxr-xr-x 7 sa sa 4.0K 2007-09-19 19:43 fai
33 sa@wks:/tmp/pco$ du -sh fai/
34 165M fai/
35 sa@wks:/tmp/pco$ cd fai && time git gc && cd .. && du -sh fai
36 Generating pack...
37 Done counting 3946 objects.
38 Deltifying 3946 objects...
39 100% (3946/3946) done
40 Writing 3946 objects...
41 100% (3946/3946) done
42 Total 3946 (delta 2096), reused 0 (delta 0)
43 Pack pack-7b471078885463ecd28262260bfe0b715f04f8a0 created.
44 Removing unused objects 100%...
45 Done.
46
47 real 0m10.908s
48 user 0m3.856s
49 sys 0m0.588s
50 142M fai
51 sa@wks:/tmp/pco$
Of course, since we just checked out the up-to-date SVN repository (-r
HEAD in line 1), we got a much smaller GIT repository (line 34) which
we where able to further condense (lines 35 to 51).
Screenshot
For no specific reason I just decided to take a sceenshot and put it
here — as can be seen, I use
GNU Emacs with several windows. The
current one is the one with the green mode line.
The reason why I put this screenshot here is because I think the
reader might find it pretty interesting to actually see how the work
he is looking at had been made. However, if that is not the case for
you then just ignore it ;-)
Bidirectional Operations between SVN and GIT
Assuming we have used git svn clone to import some SVN repository, we
can now start to actually work i.e. edit/add/remove etc. code and when
done, commit it back to the SVN repository. When done, import the
updates others made to our local repository, do some work, commit...
business as usual...
Importing and Updating the local GIT repository
1 sa@wks:/tmp$ mkdir demo_import
2 sa@wks:/tmp$ cd demo_import/
3 sa@wks:/tmp/demo_import$ la
4 total 4
5 drwxr-xr-x 2 sa sa 6 2009-02-23 14:30 .
6 drwxrwxrwt 12 root root 4096 2009-02-23 14:30 ..
7 sa@wks:/tmp/demo_import$ git svn clone http://tracker.trollfot.org/svn/projects/sd.app
8 Initialized empty Git repository in /tmp/demo_import/sd.app/.git/
9 W: Ignoring error from SVN, path probably does not exist: (175007): HTTP Path Not Found: '/svn/!svn/bc/100/projects/sd.app' path not found
10 W: Do not be alarmed at the above message git-svn is just searching aggressively for old history.
11 This may take a while on large repositories
12 r156 = dab9d194c4af04e2dca36c517e5edbdf9bad6cb3 (git-svn)
13 W: +empty_dir: trunk
14 r157 = a15a95575de0c116fba937afa09c9f6af7426286 (git-svn)
15
16
17 [skipping a lot of lines...]
18
19
20 D branches/sd.app-2.5-simplification/setup.py
21 D branches/sd.app-2.5-simplification/
22 W: -empty_dir: branches/sd.app-2.5-simplification
23 r430 = a265c628d2a766a04678e48762a026cbf6272ded (git-svn)
24 M trunk/sd/app/contents/browser/nextprevious.py
25 r651 = 2cfa3de1e9ebc3678841803e51b221323a3f9864 (git-svn)
26 Checked out HEAD:
27 http://tracker.trollfot.org/svn/projects/sd.app r651
28 sa@wks:/tmp/demo_import$ cd sd.app/ && gllol | head -n3
29 2cfa3de1e9ebc3678841803e51b221323a3f9864 4 weeks ago CN: trollfot AN: trollfot S: Corrected silly assertion that SD is an AT object.
30 a265c628d2a766a04678e48762a026cbf6272ded 9 weeks ago CN: trollfot AN: trollfot S: Moving branch to new trunk.
31 2ee9ea6b44b9e215392713fb21c04c743f59d77f 9 weeks ago CN: trollfot AN: trollfot S: removing tagged trunk.
There is nothing really worth mentioning here — we did git svn clone
above already. What we are more interested in right now is the
workflow we are going to choose. A major part of it, is of course to
update our local GIT repository from the remote SVN repository. We can
see from lines 28 to 31 that we have all the history available the way
we did this import (for more info see above).
Another concern most folks have when doing bidirectional work amongst
their local GIT repository and a remote SVN repository is the
repository layout i.e. do I get/need the exact same layout the SVN
repository has within my GIT repository? No, we do not need it and it
must not mirror the SVN repository layout but when it does, then it is
fine too. In other words, from my point of view it is best practice to
have the local GIT repository layout look like this (looking from the
repository root down)
32 sa@wks:/tmp/demo_import/sd.app$ la
33 total 0
34 drwxr-xr-x 6 sa sa 55 2009-02-23 14:35 .
35 drwxr-xr-x 3 sa sa 19 2009-02-23 14:41 ..
36 drwxr-xr-x 3 sa sa 28 2009-02-23 14:35 branches
37 drwxr-xr-x 9 sa sa 144 2009-02-23 14:35 .git
38 drwxr-xr-x 3 sa sa 18 2009-02-23 14:35 tags
39 drwxr-xr-x 4 sa sa 58 2009-02-23 14:35 trunk
40 sa@wks:/tmp/demo_import/sd.app$ git svn rebase
41 Current branch master is up to date.
As we can see from lines 33 to 39, the local GIT repository we just
cloned with the command in line 7 looks exactly the same as the remote
SVN repository does (except for the metadata of course i.e. .git and
.svn respectively).
Line 40 is the most important one until now — it updates the local
GIT repository with all the changes that have been made to the remote
SVN repository. In short, it is the equivalent to git pull in case we
were only dealing with GIT repositories on all ends of the table. Of
course, since we just cloned, there are no updates to fetch as can be
seen in line 41.
Merging and rebasing are two major concepts of GIT, which in the end,
both lead to the same result but get there on different paths. A
repository history made up of merges (and maybe also rebase actions)
has a non-linear history (first screenshot below; upper-left corner)
whereas a repository where git pull respectively git merge has never
been used on, has a linear history (second screenshot). Both
screenshots show the use of gitk, once on our current code and once on
the GIT source code itself (first screenshot).
Now, those who are interested in more details can go read man 1
git-rebase, or if not, just remember that when dealing only with GIT
repositories, we can merge and rebase as we feel lucky whereas, when
there is some SVN repositories involved, we stick to rebasing. In the
end, both cater for the same result anyway...
The rebasing concept might be a bit tricky to understand — even more
so if one gets a notion what else can be done with it except of what
we just tried in line 40. However, from my point of view, rebasing is
probably the most powerful thing one can do with GIT if he understands
its full potential.
Creating a new Topic Branch used to carry out our Work
42 sa@wks:/tmp/demo_import/sd.app$ git checkout -b topic_branch_implementing_something
43 Switched to a new branch "topic_branch_implementing_something"
44 sa@wks:/tmp/demo_import/sd.app$ git branch
45 master
46 * topic_branch_implementing_something
47 sa@wks:/tmp/demo_import/sd.app$ echo "my comments blabla" >> trunk/README.txt
48 sa@wks:/tmp/demo_import/sd.app$ git dwi
49 diff --git a/trunk/README.txt b/trunk/README.txt
50 index e69de29..7c399ee 100644
51 --- a/trunk/README.txt
52 +++ b/trunk/README.txt
53 @@ -0,0 +1 @@
54 +my comments blabla
Now that we have imported a SVN repository and updated it (line 40),
we are going to do some work. We do not use the currently active
branch master to work on but create a topic branch called
topic_branch_implementing_something in line 42. There we can
experiment and toy around without affecting the real branch — all
local changes we do are always carried out on some topic branch which
is then deleted after we merged/rebased our changes back into master.
From master we then use git svn dcommit to export our changes back
into the remote SVN repository.
In line 47 we did our first change to our currently active branch
topic_branch_implementing_something. The command used in line 48 is an
GIT alias, showing us the differences between the working tree and the
index. Note that we have not committed those changes to the HEAD of
our current branch yet.
55 sa@wks:/tmp/demo_import/sd.app$ git cwh -m 'added some additional comments'
56 [topic_branch_implementing_something]: created e160df1: "added some additional comments"
57 1 files changed, 1 insertions(+), 0 deletions(-)
58 sa@wks:/tmp/demo_import/sd.app$ gllol | head -3
59 e160df17cd4061664a200d27b40ebeb72426205a 76 seconds ago CN: Markus Gattol AN: Markus Gattol S: added some additional comments
60 2cfa3de1e9ebc3678841803e51b221323a3f9864 4 weeks ago CN: trollfot AN: trollfot S: Corrected silly assertion that SD is an AT object.
61 a265c628d2a766a04678e48762a026cbf6272ded 9 weeks ago CN: trollfot AN: trollfot S: Moving branch to new trunk.
62 sa@wks:/tmp/demo_import/sd.app$ git diff master
63 diff --git a/trunk/README.txt b/trunk/README.txt
64 index e69de29..7c399ee 100644
65 --- a/trunk/README.txt
66 +++ b/trunk/README.txt
67 @@ -0,0 +1 @@
68 +my comments blabla
In line 55 we commit those changes and then take a look at the last
three commits logs in line 58, using a somewhat fancy command of mine.
What is also very interesting is to take a look at the differences
amongst branches which we do in lines 62 to 68 — remember, we are
currently on branch topic_branch_implementing_something, and so the
command from line 62 shows us the differences between branch master
and branch topic_branch_implementing_something.
At this point, branch master and branch
topic_branch_implementing_something are different already because we
issued line 55. However, before we merge/rebase those changes back
into master and then out to the remote SVN repository, we shall do
some more changes on branch topic_branch_implementing_something.
69 sa@wks:/tmp/demo_import/sd.app$ touch trunk/new_file
70 sa@wks:/tmp/demo_import/sd.app$ git add .
71 sa@wks:/tmp/demo_import/sd.app$ git dwh
72 diff --git a/trunk/new_file b/trunk/new_file
73 new file mode 100644
74 index 0000000..e69de29
75 sa@wks:/tmp/demo_import/sd.app$ git dih
76 diff --git a/trunk/new_file b/trunk/new_file
77 new file mode 100644
78 index 0000000..e69de29
79 sa@wks:/tmp/demo_import/sd.app$ git cwh -m 'added a new file'
80 [topic_branch_implementing_something]: created d34621c: "added a new file"
81 0 files changed, 0 insertions(+), 0 deletions(-)
82 create mode 100644 trunk/new_file
83 sa@wks:/tmp/demo_import/sd.app$ gllol | head -n3
84 d34621c1941d9e0e97b7fab25a8fce7bfa5c780e 3 minutes ago CN: Markus Gattol AN: Markus Gattol S: added a new file
85 e160df17cd4061664a200d27b40ebeb72426205a 36 minutes ago CN: Markus Gattol AN: Markus Gattol S: added some additional comments
86 2cfa3de1e9ebc3678841803e51b221323a3f9864 4 weeks ago CN: trollfot AN: trollfot S: Corrected silly assertion that SD is an AT object.
87 sa@wks:/tmp/demo_import/sd.app$ git diff master
88 diff --git a/trunk/README.txt b/trunk/README.txt
89 index e69de29..7c399ee 100644
90 --- a/trunk/README.txt
91 +++ b/trunk/README.txt
92 @@ -0,0 +1 @@
93 +my comments blabla
94 diff --git a/trunk/README.txt b/trunk/new_file
95 similarity index 100%
96 copy from trunk/README.txt
97 copy to trunk/new_file
In line 69 we create a new file (new_file) which we add to the index
in line 70. Note, that if we had used git add trunk/new_file it would
have been added/committed all the way back into the repository back
end also known as HEAD and not just staged into the index for future
committing.
Line 71 is also a GIT alias, showing us the differences between the
working tree and HEAD. Of course that are the same differences as
between the index and HEAD in our current situation (nothing else has
been changed in the working tree) as we figure after issuing line 75.
We commit those changes in line 79 and issue another gllol in line 83
just to find out that we made 2 commits on branch
topic_branch_implementing_something until we created this branch. If
we check now, we should the all changes introduced with those commits
when we look at the differences between branch master and our current
branch, branch topic_branch_implementing_something — which is true as
we can see from lines 87 to 97.
Assuming we are done making our changes, now is the time to get our
changes back from topic_branch_implementing_something into master.
Getting Changes back from a Topic Branch into Master
Once we are done working on the topic branch we need to get our
changes back into master — right now, we are still on branch
topic_branch_implementing_something. There are basically two
possibilities in order to get our changes back into branch master:
- rebasing: getting the changes from
topic_branch_implementing_something into master by rebasing master
onto topic_branch_implementing_something and thereby assuring a
linear history. I always opt for rebasing for the afore mentioned
reasons (i.e. mixed setup of GIT and SVN repositories).
- merging: getting changes back into
master with git merge should
also work fine at this point but it may happen that for some
reason master got updated while we were still hacking away on
topic_branch_implementing_something. In this case there might then
be a real merge happening if we use git merge, creating a
non-linear history.
98 sa@wks:/tmp/demo_import/sd.app$ git rebase topic_branch_implementing_something master
99 First, rewinding head to replay your work on top of it...
100 Fast-forwarded master to topic_branch_implementing_something.
101 sa@wks:/tmp/demo_import/sd.app$ git branch
102 * master
103 topic_branch_implementing_something
104 sa@wks:/tmp/demo_import/sd.app$ git diff topic_branch_implementing_something
105 sa@wks:/tmp/demo_import/sd.app$ gitk
In line 98 we rebase the branch master onto branch
topic_branch_implementing_something and thereby get the changes back
into master plus, ensure a linear repository history. git rebase, like
git svn rebase requires that the working tree be clean and have no
uncommitted changes. The command from line 98 does not just that but
also checks out master as we can see from line 102.
Line 104 does not produce any results simply because, at this point,
there are no more differences between branch master and branch
topic_branch_implementing_something. The result of the command issued
in line 105 can be seen below. It shows master with the changes we
just rebased it on. What we also see is that we still have a linear
history.
106 sa@wks:/tmp/demo_import/sd.app$ git checkout topic_branch_implementing_something
107 Switched to branch "topic_branch_implementing_something"
108 sa@wks:/tmp/demo_import/sd.app$ gitk
With line 106 we switch back to branch
topic_branch_implementing_something and again, issue gitk in line 108
just to see that this branch is exactly the same as is master right
now — same history plus it is linear.
Committing Changes to remote SVN Repository
Getting our changes from master back into the remote SVN repository is
done with git svn dcommit.
WRITEME
Trust
Again, take a look at the GIT glossary and read about the definition
of object and object name in order to easily understand the following.
- Integrity
-
First off, since everything is hashed with SHA1, we can trust that an
object is intact and has not been messed with by external sources. So
the name of an object uniquely identifies a known state — just not a
state that we may want to trust.
-
Furthermore, since the SHA1 signature of a commit refers to the SHA1
signatures of the tree it is associated with, and the signatures of the
parent, a single named commit specifies uniquely a whole set of
history, with full contents. We cannot later fake/change any step of
the way once we have the name of a commit without changing the SHA1
hash (immutability of the history of commits that is).
- Authentication
-
If we receive the SHA1 name of a blob from one source, and its
contents from another (possibly untrusted) source, we can still trust
that those contents are correct as long as the SHA1 name agrees. This
is because the SHA1 is designed so that it is infeasible to find
different contents that produce the same hash.
-
Similarly, we need to only trust the SHA1 name of a top-level tree
object to trust the contents of the entire directory that it refers
to, and if we receive the SHA1 name of a commit from a trusted
source, then we can easily verify the entire history of commits
reachable through parents of that commit, and all of those contents of
the trees referred to by those commits.
So, to introduce some real trust in the system, the only thing we need
to do is to digitally sign just one special note, which includes the
name of a top-level commit. Our digital signature shows others that we
trust that commit, and the immutability of the history of commits
tells others that they can therefore also trust the whole history.
In other words, we can easily validate a whole archive by just sending
out a single email that tells the people the name (SHA1 hash) of the
top commit, and digitally sign that email using something like
GPG/PGP. To assist in this, GIT also provides the tag object.
Note that despite the tag features, GIT itself only handles content
integrity —
the trust framework (i.e. signature provision and
verification) has to come from the outside (e.g. GPG (GNU Privacy
Guard)).
Cryptographically signing a Commit
So, GIT takes care about integrity, the rest is up to the user. We
need to have GPG (GNU Privacy Guard) installed
sa@wks:~$ dpl gnupg | grep ^ii
ii gnupg 1.4.9-3 GNU privacy guard - a free PGP replacement
sa@wks:~$
As we can see, I have already installed it. If one has not then
aptitude install gnupg or apt-get install gnupg does the tick. Sure,
one might also install from source but I would strongly recommend to
not bypass the package management system since that will lead to a
unusable system in the long term besides the fact that using Debian's
APT (Advanced Packaging Tool) is much more comfortable and many times
faster.
Create a GPG keypair
Let us start with some comic ;-]
Update: This key (the one that is created below, fingerprint/key ID
F6F78566432A78A90D39CDAE48E94AC6C0EC7E38) has been created in February
2009 when DSA still were the default choice. From now on (June 2009)
GPG is using RSA as default for primary keys. Because of that, lines 7
to 9 below might look a bit different for those who create a new
keypair after June 2009.
However, there is nothing to worry about this change since it is just
an internal change in GPG and no change to how it is used or behaves.
From the users point of view there is actually no difference at all!
After we have installed GPG we need to create a keypair which is then
used by git tag to digitally sign a commit. However, let us assume we
have no keypair yet or if maybe we just want to create another one
then we can easily do so.
Issuing gpg --gen-key is an interactive command which means, once
issued, it will prompt us for various things e.g. email address, what
kind of cipher to use, how long until the key should expire if at all,
etc.
1 sa@wks:~$ gpg --gen-key
2 gpg (GnuPG) 1.4.9; Copyright (C) 2008 Free Software Foundation, Inc.
3 This is free software: you are free to change and redistribute it.
4 There is NO WARRANTY, to the extent permitted by law.
5
6 Please select what kind of key you want:
7 (1) DSA and Elgamal (default)
8 (2) DSA (sign only)
9 (5) RSA (sign only)
10 Your selection?
11 DSA keypair will have 1024 bits.
12 ELG-E keys may be between 1024 and 4096 bits long.
13 What keysize do you want? (2048) 4096
14 Requested keysize is 4096 bits
15 Please specify how long the key should be valid.
16 0 = key does not expire
17 <n> = key expires in n days
18 <n>w = key expires in n weeks
19 <n>m = key expires in n months
20 <n>y = key expires in n years
21 Key is valid for? (0)
22 Key does not expire at all
23 Is this correct? (y/N) y
24
In line 1 we can see that I am issuing the command in order to create
a new key. From line 6 to 10 I got prompted for a particular type of
key — I opted for the default — just hitting RET that is. In line 13
we can see that I did not chose the default length but 4096. Then in
line 21 respectively 23 I determined that the key might never expire
which is the default anyway so just hitting RET again did the trick.
25 You need a user ID to identify your key; the software constructs the user ID
26 from the Real Name, Comment and Email Address in this form:
27 "Heinrich Heine (Der Dichter) <[email protected]>"
28
29 Real name: Markus Gattol
30 Email address: foo[at]bar.org
31 Comment:
32 You selected this USER-ID:
33 "Markus Gattol () <foo[at]bar.org>"
34
35 Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? O
36 You need a Passphrase to protect your secret key.
37
From line 29 to 31 I am prompted for my real name and the like which I
entered and confirmed in line 35 (using O RET). Finally note line 36.
We are prompted for a passphrase (we should use a strong passphrase)
which we need for various actions later on e.g. signing stuff with
this particular key, editing the key parameters like the email address
(e.g. from foo[at]bar.org to something else) for example and the like.
One might consult man 1 pgp for more information.
38 We need to generate a lot of random bytes. It is a good idea to perform
39 some other action (type on the keyboard, move the mouse, utilize the
40 disks) during the prime generation; this gives the random number
41 generator a better chance to gain enough entropy.
42 ..++++++++++++++++++++.+++++++++++++++.+++++.+++++++++++++++++++++++++++++++++
43
44 Not enough random bytes available. Please do some other work to give
45 the OS a chance to collect more entropy! (Need 10 more bytes)
46 We need to generate a lot of random bytes. It is a good idea to perform
47 some other action (type on the keyboard, move the mouse, utilize the
48 disks) during the prime generation; this gives the random number
49 generator a better chance to gain enough entropy.
50 .+++++.+++++++++++++++.+++++.+++++....+++++.+++++.+++++++++++++++
51 gpg: key C0EC7E38 marked as ultimately trusted
52 public and secret key created and signed.
53
54 gpg: checking the trustdb
55 gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model
56 gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
57 pub 1024D/C0EC7E38 2009-02-06
58 Key fingerprint = F6F7 8566 432A 78A9 0D39 CDAE 48E9 4AC6 C0EC 7E38
59 uid Markus Gattol () <foo[at]bar.org>
60 sub 4096g/34233DEF 2009-02-06
61
62 sa@wks:~$
In lines 38 to 50, all that happens is, the OS (Operating System)
tries to actually create the key and thus needs random data — (this
might take a couple of minutes depending on the amount of randomness
available to the OS at this point).
Then in lines 51 to 60, what we get is a lot of status report on the
newly created key. We are now ready to use the key. Caution: this is
beyond the scope of this page but as we see in lines 54 to 56, the
actual degree of trust is low — one wants to get his key signed by
others in order to elevate the trust level. Doing so is easy by
joining key signing parties.
When we are done creating a new key respectively also in case we
already had one issuing gpg --list-keys outputs all keys to stdout.
sa@wks:~$ gpg --list-keys | egrep -{A,B}1 www.markus-gattol.name
pub 1024D/C0EC7E38 2009-02-06
uid Markus Gattol () <foo[at]bar.org>
sub 4096g/34233DEF 2009-02-06
sa@wks:~$
In this example we can see the just created key. I only wanted to show
this one so I used egrep to filter the output.
Signing:
Now that we have the key we can go ahead and actually do what we
intended to do from the beginning — we are going to digitally sign a
commit. Signing a commit works by signing a tag object. Do not confuse
tag with tag object — the latter one is referenced by the former one.
A tag object usually points to another object (see also object type.
In case a tag object gets signed as well it is called a signed tag
object, containing not just an optional message and a ref to another
object but also a digital signature.
So, all we need to do is to create a tag object and sign it. Easy said,
easy done...
1 sa@wks:~$ cd /tmp/ && mkdir test_signing && cd test_signing
2 sa@wks:/tmp/test_signing$ touch my_file && echo "some text..." > my_file
3 sa@wks:/tmp/test_signing$ git init
4 Initialized empty Git repository in /tmp/test_signing/.git/
5 sa@wks:/tmp/test_signing$ git add .
6 sa@wks:/tmp/test_signing$ git commit -a -m "initial commit"
7 Created initial commit 8aaf01a: initial commit
8 1 files changed, 1 insertions(+), 0 deletions(-)
9 create mode 100644 my_file
10 sa@wks:/tmp/test_signing$ echo "some changes" >> my_file
11 sa@wks:/tmp/test_signing$ git diff
12 diff --git a/my_file b/my_file
13 index 9d75b34..30331e4 100644
14 --- a/my_file
15 +++ b/my_file
16 @@ -1 +1,2 @@
17 some text...
18 +some changes
Nothing special in lines 1 to 18... those are just provided for the
sake of completeness.
19 sa@wks:/tmp/test_signing$ git commit -a -m "We made some changes."
20 Created commit 216b0d2: We made some changes.
21 1 files changed, 1 insertions(+), 0 deletions(-)
22 sa@wks:/tmp/test_signing$ git tag -u Markus -m "Creating a signed tag object." first_tag
23
24 You need a passphrase to unlock the secret key for
25 user: "Markus Gattol () <foo[at]bar.org>"
26 1024-bit DSA key, ID C0EC7E38, created 2009-02-06
27
28 sa@wks:/tmp/test_signing$ type la && la .git/refs/tags/
29 la is aliased to `ls -la'
30 total 4
31 drwxr-xr-x 2 sa sa 22 2009-02-07 01:38 .
32 drwxr-xr-x 4 sa sa 29 2009-02-07 01:30 ..
33 -rw-r--r-- 1 sa sa 41 2009-02-07 01:38 first_tag
In line 19 we do another commit since we did some changes in line 10.
Line 22 is what it is all about. I am determining to use the former
created key by providing the argument -u Markus whereas Markus is the key
ID (Identifier) (could be anything that uniquely identifies a key).
With -m, I am able to provide a tag message directly on the CLI
(Command Line Interface) instead of being prompted. first_tag is the
name of the tag object created by issuing line 22.
Note line 24. We are prompted for a passphrase. It is the one that we
needed to provide while we created the key with gpg --gen-key above.
In lines 28 to 33 we can see that we just got a new tag — note the
path .git/refs/tags/.
34 sa@wks:/tmp/test_signing$ git rev-parse --tags
35 7c2557f9fe84df13db8e4ebf29791e6b3eaa51f8
36 sa@wks:/tmp/test_signing$ git rev-parse --tags | xargs git cat-file -t
37 tag
38 sa@wks:/tmp/test_signing$ git rev-parse --tags | xargs git cat-file -p
39 object 216b0d2c95da8fb8813b51b915acd82367660bb6
40 type commit
41 tag first_tag
42 tagger markus gattol <sa@wks.(none)> Sat Feb 7 01:38:41 2009 +0100
43
44 Creating a signed tag object.
45 -----BEGIN PGP SIGNATURE-----
46 Version: GnuPG v1.4.9 (GNU/Linux)
47
48 iEYEABECAAYFAkmM2BEACgkQSOlKxsDsfjjd1gCZAaREGDPSFrrtSkNF1drl3B/m
49 SEQAn3QlNTUcku03KLCL4L9nKwOwAVd5
50 =ZoCW
51 -----END PGP SIGNATURE-----
52 sa@wks:/tmp/test_signing$ git tag -v first_tag
53 object 216b0d2c95da8fb8813b51b915acd82367660bb6
54 type commit
55 tag first_tag
56 tagger markus gattol <sa@wks.(none)> 1233967121 +0100
57
58 Creating a signed tag object.
59 gpg: Signature made Sat 07 Feb 2009 01:38:41 AM CET using DSA key ID C0EC7E38
60 gpg: Good signature from "Markus Gattol () <foo[at]bar.org>"
61 sa@wks:/tmp/test_signing$
In line 34, we are using an ancillary GIT command to figure which tag
refs we have so far — in our case there can be just one since we did
not create more than one so far. The ref from line 35 can then be used
to gather more information about an object since the ref can be passed
to other GIT commands e.g. git cat-file (provides content or type
information on objects in the repository). Line 36 and 37 shows how we
can check for the object type.
Note, that line 35 and 39 are not the same although they belong to the
same object in some way — line 35 is the tag ref and line 39 is the
object name (the objects unique SHA1 hash value).
Lines 38 to 51 are pretty much the same as lines 52 to 60 — only
difference is that we used two different possibilities to show the
content information of our signed tag object. I prefer the command in
line 38 over the one in line 52 simply because I find the output
easier to read plus it nicely shows the digital signature on the tag
object.
Managing Branches
Well, before we manage something we should understand it. What is a
branch? What are they good for and why is branching so easy done and
popular amongst GIT folks? A lot of questions... Let us try to look
at them one by one.
Introducing Branches
Probably GIT's most compelling feature that really makes it stand
apart from nearly every other SCM system out there is its branching
model. When it comes to branching, GIT is completely different from
any of the SCM systems out there — most of which recommend that the
best approach at branching is basically to clone/copy the repository
to a new directory below the repository root.
GIT does not work like that. GIT will allow us to have multiple local
branches that can be entirely independent of each other and the
creation, merging and deletion of those lines of development take
mostly only fractions of seconds. In practical terms this means that
we can do things like:
- Create a branch to try out an idea, commit a few times, switch back
to where we branched from, apply a patch, switch back to where we
are experimenting, then merge the patch in our experimenting/toying
branch.
- Have a branch that always contains only what goes to production,
another one that we merge work into for testing and several smaller
ones for day to day work.
- Create new branches for each new feature we are working on, so we
can seamlessly switch back and forth between them, then delete each
branch when that feature gets merged into our mainline branch.
- Create a branch to experiment in, realize it is not going to work
and just delete it, abandoning the work, with nobody else ever
seeing it (even if we have pushed out other branches in the
meantime).

Importantly, when we push to a remote repository, we do not have to
push all of our branches. We can only share one or a few of our
branches and not all of them.
This tends to free people to try new ideas without worrying about
having to plan how and when they are going to merge it in or share it
with others. We can find ways to do some of this with other systems,
but the work involved is much more difficult and error-prone. GIT
makes this process incredibly easy and it changes the way most
developers work when they learn it.
Detailed Look at Branches?
If we take a quick look at the glossary we will see that there is not
just a branch but different types of branches. Next to the common term
of a branch, there is also a topic branch and a tracking branch.
Branches can be local or remote (not on ones local computer but
somewhere else) which, in practice, is related to what type of branch
someone declares a branch by simply using it in a dedicated way.
A general description of Branches in GIT:
A project history is born by recording a particular state (also known
as revision) as a root commit, and built up by recording subsequent
states (revisions) on top of the previous commits. Thus, a group of
commits connected by their parent fields form a DAG (Directed Acyclic
Graph).
Often this linkage between commits by their parent fields is called
ancestry chain, and a commit that has another commit in its parent
field is called a child commit of the latter. There can be multiple
root commits in the history of a project. In other words, projects
born independently can later be glued together to become a single
project.
The history is grown by building on top of previous commits, and by
the nature of distributed development, many lineages of histories are
grown simultaneously. Each lineage is called a branch.
A commit, that can be reached by following the ancestry chain from a
commit that is on the branch, is also on the branch. A commit that
cannot be reached by following the ancestry chain from any commit that
is on the branch is not on the branch.
The commit that bootstraps this recursive definition of on the branch,
is called its branch head, the tip of the branch, or the top commit.
In other words, it is topologically the latest commit on the branch.
The above does not mean the top commit of a branch does not have any
child commit in the global project histories. It just means that these
children are not on the branch; they may be on some other branches,
forked from it.
To create a branch whose on the branch commits are a strict superset
of on the branch commits of another branch is called forking the
branch.
Different points of view on branches:
- From the history point of view, a branch is lineage of branch
heads (branch tips chronologically chained together) i.e.
parent-connected graph of all the ancestors of the head.
- From the commit point of view, branch heads are automatically
moving pointers to the tip of branch, the place where we commit
changes.
- From the reflog (see also here) point of view, a branch is a set
of previous branch heads, starting from the root or fork/branching
point.
- From the implementation point of view, a branch is a remote branch
if it is in the
../refs/remotes namespace instead of the
../refs/heads namespace.
Why GIT folks like branching so much
One cannot discuss branching without also discuss merging. The
branching and merging thing with GIT is pretty straightforward.
Compared to doing branching and merging with SVN, doing it with GIT is
like heaven opens up and angels start singing — I hated it back then
with SVN. With SVN one gets no merge tracking but he has to do it
manually — I leave it to the readers imagination to conceive at what
folks look at after a few weeks or so. One might use SVK on top of SVN
but it still is not comparable to what we get with GIT out of the box.
The basic question is if the maintenance costs of managing branches
outweigh the potential benefits? If the answer is no, then we should
branch. With GIT the maintenance cost for branches is in fact not
existent and that is why GIT folks use branching almost on a regular
and for various things.
With other SCM (Software Configuration Management) systems, where
there is a high cost of maintaining branches, folks do rarely enjoy
the benefit of branching simply because they are shy of all the
maintenance labor that comes with it.
When should we create a Branch?
As I said, with GIT we might create a branch for almost anything, work
on that branch and when done merge it back into a branch that we
declared our main branch (some particular topic branch) but that we
never touch directly — we just merge into our main branch when we are
sure the branch we are merging from is sane.
Such short-lived branches are often called lightweight branches or
topic branches in which we carry out a potentially disruptive task
that would otherwise break the main branch (or some other important
release branch). Once the task is complete, the changes are merged all
at once back to the main branch (from one topic branch where we did
our changes into another topic branch, our main branch), hopefully
without breakage and minimizing disruption. A lightweight branches
life effectively comes to an end at this point and we delete it again,
creating a new lightweight branch and so forth.
Reasons for creating lightweight branches might be:
- Working on a bug fix (e.g. when I fix a series of typos for this
website, I create a new topic branch just for that task, do all the
fixes, merge them back into my local main branch and finally delete
the topic branch used for the current task of fixing a bunch of
typos).
- Implementing a new feature
- Carrying out experimental work
- etc.
Creating and Toying with local Branches
Most folks think the definition for local branch determines that the
branch is located on their local computer (no remote working via SSH
and such). While that is mostly true it actually determines that, when
speaking of a local branch, we refer to a branch in the currently
active repository. Mostly that repository happens to be on the local
machine so... See remote branch to get the big picture...
1 sa@wks:~/work/git/test$ git branch
2 * master
3 sa@wks:~/work/git/test$ git branch my_first_branch
4 sa@wks:~/work/git/test$ git branch
5 * master
6 my_first_branch
7 sa@wks:~/work/git/test$ git checkout my_first_branch
8 Switched to branch "my_first_branch"
9 sa@wks:~/work/git/test$ git branch
10 master
11 * my_first_branch
12 sa@wks:~/work/git/test$ git checkout -b my_second_branch && git branch
13 Switched to a new branch "my_second_branch"
14 master
15 my_first_branch
16 * my_second_branch
17 sa@wks:~/work/git/test$ git branch -d my_first_branch
18 Deleted branch my_first_branch.
19 sa@wks:~/work/git/test$ git branch
20 master
21 * my_second_branch
We are issuing git branch in line 1 without any arguments which means
it defaults to showing a list of existing local branches — the
current branch is highlighted with an asterisk.
We are creating a new branch in line 3 which is called
my_first_branch. From that point on in time, my_first_branch is a
distinct lineage of development, directly descended from the branch
called master. To be more precise, it is a descendant from HEAD of
master (the tip of the master branch that is). As we can see in lines
4 to 6, we now have two branches with master still being the active
one.
In line 7 we are switching to another branch (my_first_branch).
Switching branches is done by updating the index and the working tree
to reflect the specified branch. In line 11, we can see that the
asterisk went from master to my_first_branch. Line 12 shows how to
create a new branch (my_second_branch) and switch to it in one step —
asterisk is now on my_second_branch (line 16). Line 17 shows how to
delete a branch.
22 sa@wks:~/work/git/test$ git branch -v
23 master e973aea Initial commmit.
24 * my_second_branch e973aea Initial commmit.
25 sa@wks:~/work/git/test$ ll
26 total 4.0K
27 -rw-r--r-- 1 sa sa 10 2007-09-23 08:50 my_file
28 sa@wks:~/work/git/test$ echo "more text" >> my_file
29 sa@wks:~/work/git/test$ git diff
30 diff --git a/my_file b/my_file
31 index 7b57bd2..4bfbf30 100644
32 --- a/my_file
33 +++ b/my_file
34 @@ -1 +1,2 @@
35 some text
36 +more text
37 sa@wks:~/work/git/test$ git commit -a -m "Some changes on this branch head"
38 Created commit bb34607: Some changes on this branch head
39 1 files changed, 1 insertions(+), 0 deletions(-)
40 sa@wks:~/work/git/test$ git branch -v
41 master e973aea Initial commmit.
42 * my_second_branch bb34607 Some changes on this branch head
43 sa@wks:~/work/git/test$ git checkout master
44 Switched to branch "master"
45 sa@wks:~/work/git/test$ git diff
46 sa@wks:~/work/git/test$
Line 22 triggers the verbose version of git branch, it also shows the
SHA1 hash (part of) with the commit message subject line for each
head. We are on branch my_second_branch (line 24). Actually, as we can
see in line 23 and 24 they are the same. We are now going to change
that (line 28). After committing (line 37) we can see that line 40
creates a different output compared to what we get from line 22.
After switching back to master in line 43 and issuing line 45, we can
see that nothing changed on branch master. Finally, branch master and
branch my_second_branch are different from each another — as
pronounced above, my_second_branch now has changes as can be seen in
lines 29 to 36.
Non-default basing of Branches:
Until now, we always based newly created branches on HEAD of the
current branch. However, there is more to branching...
In fact, when creating a new branch it can be made descendant from any
branch (local or remote) and any commit that took ever place on a
particular branch. For now, we just scratched the surface of what can
be done. However, upcoming things are as simple as were those we
already looked into before.
Basing on a Branch other than the current One
1 sa@wks:~$ git branch
2 fatal: Not a git repository
3 sa@wks:~$ cd work/git/test/
4 sa@wks:~/work/git/test$ git branch
5 * master
6 my_second_branch
7 sa@wks:~/work/git/test$ git branch new_branch_based_on my_second_branch
8 sa@wks:~/work/git/test$ git branch -v
9 * master e973aea Initial commmit.
10 my_second_branch bb34607 Some changes on this branch head
11 new_branch_based_on bb34607 Some changes on this branch head
I am not perfect as can be seen — meanwhile I did something else and
thus was not inside my GIT repository (line 1 and 2). Line 4 issues
git branch which we already know shows us all local branches. We are
currently on branch master as we can see in line 5.
In line 7, we are issuing a command to create a new branch
(new_branch_based_on) which starts as an descendant from HEAD of
branch my_second_branch although our currently active branch is
master. We can see how that all plays out in lines 9 to 11 — note the
matching commit ID (Identifier) in line 10 and 11.
Basing on a Tag
12 sa@wks:~/work/git/test$ git rev-parse --tags
13 sa@wks:~/work/git/test$ git tag -m "This is a random tag." first_tag
14 sa@wks:~/work/git/test$ git tag
15 first_tag
16 sa@wks:~/work/git/test$ git rev-parse --tags
17 8b3f6ba8e7b6b53d2d77a069742bcf983183cd83
18 sa@wks:~/work/git/test$ git tag -v first_tag
19 object e973aea29c60b1d8031ab661a1f466b7e95821bf
20 type commit
21 tag first_tag
22 tagger markus gattol <sa@wks.(none)> 1234023501 +0100
23
24 This is a random tag.
25 gpg: no valid OpenPGP data found.
26 gpg: the signature could not be verified.
27 Please remember that the signature file (.sig or .asc)
28 should be the first file given on the command line.
29 error: could not verify the tag 'first_tag'
30 sa@wks:~/work/git/test$ git tag
31 first_tag
32 sa@wks:~/work/git/test$ git branch based_on_first_tag first_tag
33 sa@wks:~/work/git/test$ git branch -v
34 based_on_first_tag e973aea Initial commmit.
35 * master e973aea Initial commmit.
36 my_second_branch bb34607 Some changes on this branch head
37 new_branch_based_on bb34607 Some changes on this branch head
38 sa@wks:~/work/git/test$
In line 12, I tried to figure what tags are in place if any — the
command git rev-parse --tags has been chosen for no particular reason
i.e. line 14 would have worked as well. In line 13, we are creating a
new tag object with a tag (first_tag) referring to it. We also provide
a tag message via the CLI (Command Line Interface). Again, those who
still struggle with the exact terms (tag, tag object, etc.) and their
meaning, please go and read the glossary again.
Then, in line 14, we check again if there is a tag around now... of
course there is now that we created one. Line 16 is the same as line
12 but this time, because we have created a tag, we also get the tag
ref (a tag basically is a ref) in line 17.
Note, that line 17 and 19 are not the same although they belong to the
same object in some way — line 17 is the tag ref and line 19 is the
object name (the objects unique SHA1 hash value).
What we actually wanted to do is to create a new branch as an
descendant from a tag. This is done in line 32. As we can see in lines
19 and 34 to 37, the tag (first_tag), the branch master and the branch
based_on_first_tag are actually the same object as of now. Just
compare their names — the tag in line 19, branch based_on_first_tag
in line 34 and branch master in line 35.
Basing on non-HEAD Commits
1 sa@wks:~/work/git/test$ git checkout my_second_branch
2 Switched to branch "my_second_branch"
3 sa@wks:~/work/git/test$ git branch -v
4 based_on_first_tag e973aea Initial commmit.
5 master e973aea Initial commmit.
6 * my_second_branch bb34607 Some changes on this branch head
7 new_branch_based_on bb34607 Some changes on this branch head
8 sa@wks:~/work/git/test$ git log --pretty=oneline
9 bb3460772fd9a287b26c89d8752da8d7038c8056 Some changes on this branch head
10 e973aea29c60b1d8031ab661a1f466b7e95821bf Initial commmit.
Nothing unusual in line 1 to 7. Line 8 shows how to take a lock at the
currents branch (my_second_branch) commit logs in a compact way. Each
commits information is on one line, starting with the object name
followed by the log/commit message that was been given at commit time.
11 sa@wks:~/work/git/test$ git branch based_on_non-HEAD HEAD^
12 sa@wks:~/work/git/test$ git branch -v
13 based_on_first_tag e973aea Initial commmit.
14 based_on_non-HEAD e973aea Initial commmit.
15 master e973aea Initial commmit.
16 * my_second_branch bb34607 Some changes on this branch head
17 new_branch_based_on bb34607 Some changes on this branch head
18 sa@wks:~/work/git/test$
Line 11 is the important one with this example. HEAD^ determines the
commit before the current tip of the branch (the parent). As lines 13
to 17 show, the newly created branch based_on_non-HEAD has the object
name that is the same as the one which master has (e97...). Had we
created a new branch as a descendant from HEAD it would have had the
same name as branch my_second_branch currently has (bb3...). In other
words, we did not leave the current branch, we just went back in time
on the same branch.
In fact, we could do numerous examples like the one before because a
new branch can be created with a HEAD equal to whatever commit we
specify. The ancestor of the new branch we want to create may be given
as a branch name, a commit ID (also known as object name also known as
objects SHA1 hash), or as tag. However, as default, the current
branches HEAD is made the news branch ancestor.
All the following would work since GIT deals with object names
internally which it either receives directly from the user or it maps
stuff like HEAD or my_second_branch^^^ or based_on_first_tag~18 etc.
to commit IDs
git branch my_new_branch HEAD^^ # two commits before HEAD i.e. grandparent of HEAD
git branch my_new_branch some_existing_branch~3 # three commits before tip of branch some_existing_branch
git branch my_new_branch v1.3 # based on a tag named v1.3
And a more interesting example which creates a branch based on what
our current branch was one day before the current one (take a look
here and here).
sa@wks:~/work/git/test$ git show my_second_branch@{1} --pretty=oneline | head -n1 | cut -d ' ' -f1
e973aea29c60b1d8031ab661a1f466b7e95821bf
sa@wks:~/work/git/test$ git-branch my_new_branch `git-show my_second_branch@{1} --pretty=oneline | head -n1 | cut -d ' ' -f1`
All that is needed is a way provide the desired ID like for example
git show master@{one.week.ago} --pretty=oneline | head -n1 | cut -d ' ' -f1
As I said above ... may be given as a branch name, a commit ID, a
reflog, or as a tag... the fact that one can supply commit IDs makes
the whole branching thing the Wild West... there are no limits... go
wild!
Remote Branches
From the implementation point of view, a branch is a remote branch if
it is in the ../refs/remotes namespace instead of the ../refs/heads
namespace. Probably less abstract is the following explanation.
A branch is considered a remote branch if it gets fetched (git fetch,
git pull) from a repository other than the current one. For example,
we might fetch a remote branch from a machine miles away or from the
local machine but either ways, a remote branch is not located within
the currently active repository.
- Question:
-
How do we get a remote branch?
- Answer:
-
One gets remote branches if he either clones (
git clone) from a remote
repository or if he adds remote branches (git remote, git fetch) to an
existing repository.
-
With this subsection we will always grab an entire remote repository
and not just one or more particular branches from a remote repository.
In case we just need a particular branch and not the entire
repository, we might do so as well.
If we take a look at
sa@wks:~/work/git/test$ git branch -r && git remote
sa@wks:~/work/git/test$
we can see that there is currently no remote branch in this particular
repository that I used to demonstrate things so far. This is simply
because I created the repository local, added a file, did some changes
to the file (repository contents), committed them and so on. We do
have branches
sa@wks:~/work/git/test$ git branch
based_on_first_tag
based_on_non-HEAD
master
* my_second_branch
new_branch_based_on
sa@wks:~/work/git/test$
but these are local ones. I created them earlier (see above).
A remote Branch by cloning a remote Repository:
We simply clone the GIT repository itself
1 sa@wks:~/work/git$ git clone git://git.kernel.org/pub/scm/git/git.git
2 Initialized empty Git repository in /home/sa/work/git/git/.git/
3 remote: Counting objects: 92034, done.
4 remote: Compressing objects: 100% (24736/24736), done.
5 remote: Total 92034 (delta 67243), reused 90062 (delta 65711)
6 Receiving objects: 100% (92034/92034), 19.30 MiB | 1739 KiB/s, done.
7 Resolving deltas: 100% (67243/67243), done.
8 sa@wks:~/work/git$ du -sh git/
9 36M git/
Line 1, the clone command creates a new directory named after the
project i.e. git. We just downloaded ~36MiB as can be seen in line 9.
Generally, git clone clones a repository into a newly created
directory, creates remote-tracking branches for each branch in the
cloned repository (visible using git branch -r), and creates and
checks out an initial branch equal to the cloned repository's
currently active branch. After the clone, a plain git fetch without
arguments will update all the remote-tracking branches, and a git pull
without arguments will in addition merge the remote master branch into
the currently active local branch.
10 sa@wks:~/work/git$ cd git/ && git remote
11 origin
12 sa@wks:~/work/git/git$ grep -A3 "\[remote" .git/config
13 [remote "origin"]
14 url = git://git.kernel.org/pub/scm/git/git.git
15 fetch = +refs/heads/*:refs/remotes/origin/*
16 [branch "master"]
17 sa@wks:~/work/git/git$ git remote show origin
18 * remote origin
19 URL: git://git.kernel.org/pub/scm/git/git.git
20 Remote branch merged with 'git pull' while on branch master
21 master
22 Tracked remote branches
23 html maint man master next pu todo
24 sa@wks:~/work/git/git$ git branch
25 * master
26 sa@wks:~/work/git/git$ git branch -r
27 origin/HEAD
28 origin/html
29 origin/maint
30 origin/man
31 origin/master
32 origin/next
33 origin/pu
34 origin/todo
35 sa@wks:~/work/git/git$ la .git/refs/remotes/origin/
36 total 32
37 drwxr-xr-x 2 sa sa 94 2009-02-07 20:44 .
38 drwxr-xr-x 3 sa sa 19 2009-02-07 20:44 ..
39 -rw-r--r-- 1 sa sa 32 2009-02-07 20:44 HEAD
40 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 html
41 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 maint
42 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 man
43 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 master
44 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 next
45 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 pu
46 -rw-r--r-- 1 sa sa 41 2009-02-07 20:44 todo
47 sa@wks:~/work/git/git$
Line 10 shows, next to changing into the currently cloned repository,
that we issue git remote which, without arguments given, shows a list
of existing remote branches (lines 39 to 46). We then decided to take
a look behind the curtain in lines 12 to 16. What we see there is
basically where we fetch from and what we fetch.
Lines 17 to 23 pretty much show the same as lines 12 to 16 but in a
more human/novice readable format. Lines 24 to 46 are to check for the
current local branch (line 25), respectively to check for all current
remote tracking branches with git branch -r (lines 26 to 34) and to
take a look at the ../remotes/ namespace (lines 35 to 46) in order to
check for all remote branches i.e. checked out ones plus tracking
branches.
A remote Branch by adding to an existing local Repository:
This is done via git remote, git fetch respectively git branch
--track. Basically, what we do is to add (to our currently existing
repository) a remote branch from a remote repository which we did not
clone the current repository from.
1 sa@wks:~/work/git/git$ git remote
2 origin
3 sa@wks:~/work/git/git$ git peek-remote git://linux-nfs.org/pub/linux/nfs-2.6.git
4 ae1a25da8448271a99745da03100d5299575a269 HEAD
5 ae1a25da8448271a99745da03100d5299575a269 refs/heads/bugfixes
6
7 [skipping a lot of lines...]
8
9 18e352e4a73465349711a9324767e1b2453383e2 refs/tags/v2.6.29-rc3^{}
10 sa@wks:~/work/git/git$ git remote add linux_nfs git://linux-nfs.org/pub/linux/nfs-2.6.git
11 sa@wks:~/work/git/git$ git remote
12 linux_nfs
13 origin
14 sa@wks:~/work/git/git$ git fetch linux_nfs
15 warning: no common commits
16 remote: Counting objects: 1066646, done.
17 remote: Compressing objects: 100% (188545/188545), done.
18 remote: Total 1066646 (delta 874040), reused 1065276 (delta 873215)
19 Receiving objects: 100% (1066646/1066646), 259.86 MiB | 1744 KiB/s, done.
20 Resolving deltas: 100% (874040/874040), done.
21 From git://linux-nfs.org/pub/linux/nfs-2.6
22 * [new branch] bugfixes -> linux_nfs/bugfixes
23
24 [skipping a lot of lines...]
25
26 * [new tag] v2.6.29-rc2 -> v2.6.29-rc2
27 * [new tag] v2.6.29-rc3 -> v2.6.29-rc3
The command issued in line 1 shows us how much and what remote
branches we are currently tracking. As we can see in line 3, we can
use git peek-remote to list the references in a remote repository. By
doing so, we would also figure if the repository is available, or if
there are any issues (server down, outgoing firewall issues, etc.).
Then, in line 14, we issue git fetch to actually fetch the remote
branch (this might take a while, both, to respond and download).
28 sa@wks:~/work/git/git$ git remote
29 linux_nfs
30 origin
31 sa@wks:~/work/git/git$ git branch -r
32 linux_nfs/bugfixes
33 linux_nfs/devel
34 linux_nfs/linux-mm
35 linux_nfs/linux-next
36 linux_nfs/master
37 origin/HEAD
38 origin/html
39 origin/maint
40 origin/man
41 origin/master
42 origin/next
43 origin/pu
44 origin/todo
45 sa@wks:~/work/git/git$ git branch
46 * master
47 sa@wks:~/work/git/git$ git checkout -b linux_nfs_devel linux_nfs/devel
48 Checking out files: 100% (28273/28273), done.
49 Branch linux_nfs_devel set up to track remote branch refs/remotes/linux_nfs/devel.
50 Switched to a new branch "linux_nfs_devel"
51 sa@wks:~/work/git/git$ git branch
52 * linux_nfs_devel
53 master
54 sa@wks:~/work/git/git$
Lines 29 and 30 show the list of remotes. Lines 32 to 44 lists the
available remote tracking branches. Line 46 tells us that our
currently active branch is master from the former cloned repository.
Now we want to work on another branch belonging to one of our tracking
branches — we are checking out a branch to become our currently
active branch in line 47. As we can see in line 52, we have made one
of the remote tracking branches our currently active branch that we
might work with.
Fetch a Branch from a remote Repository and give it a new name in our local Repository:
We could also do something more swiftly like the below if we know we
just need one particular branch. The downside is, if we are on the go
and we might need another branch, we could not get it without
connectivity to the Internet... thus, I mostly grab the whole
repository (as shown above).
$ git fetch git://example.com/project.git theirbranch:mybranch
$ git fetch git://example.com/project.git v2.6.15:mybranch
Remote Tracking Branches:
Generally, if we are dealing with remote branches, no matter how we
get them, we might want to track them (git-branch --track) or not
(--no-track). In case we have remote branches that we got from a
projects offical public GIT repository (the one where offical releases
are put to) we might also consider to make those branches remote
tracking branches since we would then get up-to-date changes to our
local copy automatically.
Please note, when we clone from a remote repository or even if we
fetch from a remote repository and we have a default configured GIT
repository, our branches are already set up as being remote tracking
branches. See man 1 git-branch for more information.
Exploring the History of a Repository
Before we start, I would like to mention that reflogs can be very
helpful when it comes to investigating a repositories history. So what
are we talking about? What exactly is a repositories history and how
is this information useful to us?
Well, as we already know from above, GIT remembers states instead of
deltas. A sequence of states within a repository is a repositories
history. Yes, it is as simple as that. The question now is, how can we
get information about it, and further down the road, how can we use
this information to boost productivity? We will see all this answered
shortly but before that, let us recap/clarify a few things:
We will sometimes represent GIT history using diagrams like the one
below. Commits are shown as o, and the links between them with lines
drawn with -, / and \. Time goes left to right:
o--o--o <-- Branch A
/
o--o--o <-- master
\
o--o--o <-- Branch B
If we need to talk about a particular commit, the character o may be
replaced with another letter or number.
When we need to be precise, we will use the word branch to denote a
line of development, and branch head (or just head) to denote a
reference to the most recent commit on a branch. In the example above,
the branch head named A is a pointer to one particular commit, but we
refer to the line of three commits leading up to that point as all
being part of branch A. However, when no confusion will result, we
often just use the term branch, both, for branches and for branch
heads.
GIT is best thought of as a tool for storing the history of a
collection of files. It does this by storing compressed snapshots of
the contents of a file hierarchy, together with commits which show
the relationships between these snapshots.
GIT provides extremely flexible and fast tools for exploring the
history of a project. We start with one specialized tool that is
useful for finding the commit that introduced a bug into a project.
Viewing commit logs with git log
Let us start with something we already used. git log shows the commit
logs. Below I used -n1 to limit the number of shown commit logs to
one. In the following I will be using grep ^commit and wc -l simply
because, in order to demonstrate git log, we do not need the actual
commit messages. However, having their number nicely shows the
differences of several options to git log that we are going to use
subsequently.
sa@wks:~/work/git/git$ git log -n1
commit ae1a25da8448271a99745da03100d5299575a269
Merge: fd9fc84... 42f15d7...
Author: Linus Torvalds <[email protected]>
Date: Fri Feb 6 18:37:22 2009 -0800
Merge git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-unstable
* git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-unstable: (37 commits)
Btrfs: Make sure dir is non-null before doing S_ISGID checks
[skipping a lot of lines...]
Btrfs: Catch missed bios in the async bio submission thread
Btrfs: fix readdir on 32 bit machines
...
git log takes options applicable to
git rev-list to control what is shown and how, and options
applicable togit diff-tree to control how the changes each commit introduces are
shown.
On its own, it shows all commits reachable from the parent commit
within the current branch (line 2).
1 sa@wks:~/work/git/git$ git log | grep ^commit | wc -l
2 131070
3 sa@wks:~/work/git/git$ date
4 Sun Feb 8 14:09:50 CET 2009
A notion of Time
We can of course make more specific requests using the afore mentioned
git rev-list options. If we are interested only in those commits that
happened during the last two days we could issue what I did in line 5.
There is a lot more that we could do instead of 2 days ago but
basically it is all the same i.e. specifying some point in time or a
time span. As I already mentioned above, the ID given can be a branch,
tag or object name (also known as SHA1 respectively commit ID).
5 sa@wks:~/work/git/git$ git log --since="2 days ago" | grep ^commit | wc -l
6 17
7 sa@wks:~/work/git/git$ git tag -l *29*
8 29
9 v2.6.29-rc1
10 v2.6.29-rc2
11 v2.6.29-rc3
12 sa@wks:~/work/git/git$ git log v2.6.29-rc3.. | grep ^commit | wc -l
13 697
Now we want to check for tags carrying 29 in their names (line 7)
which works just fine (lines 9 to 11). Now we want to get all commits
logs that happened after (i.e. not reachable from) the tag v2.6.29-rc3
had been made. We do so by issuing line 12 and see that there have
been 697 commits after the tag v2.6.29-rc3 had been made.
Sets of Commits
If we have several branches, we might want to only take a look at the
commit logs within one branch. Lines 17 and 19 do just that.
14 sa@wks:~/work/git/git$ git branch
15 * linux_nfs_devel
16 master
17 sa@wks:~/work/git/git$ git log master..linux_nfs_devel | grep ^commit | wc -l
18 131070
19 sa@wks:~/work/git/git$ git log linux_nfs_devel..master | grep ^commit | wc -l
20 17473
21 sa@wks:~/work/git/git$ git log linux_nfs_devel...master | grep ^commit | wc -l
22 148543
23 sa@wks:~/work/git/git$ echo "131070 + 17473" | bc
24 148543
In line 18 we get to see all commits reachable from linux_nfs_devel
but not master. In line 20 we can see all commits reachable from
branch master but not from branch linux_nfs_devel.
Line 22 shows the summed up commits, reachable either from branch
master or branch linux_nfs_devel but not from both. Summing up line 18
and 20 does of course equals line 22.
Logs from a particular File/Directory
Sometimes we are just interested in the commit logs of a particular
file (line 30) or any changes made below a particular directory (line
32).
25 sa@wks:~/work/git/git$ type ll
26 ll is aliased to `ls -lh'
27 sa@wks:~/work/git/git$ ll | egrep scripts\|Make
28 -rw-r--r-- 1 sa sa 54K 2009-02-07 22:29 Makefile
29 drwxr-xr-x 12 sa sa 4.0K 2009-02-07 22:29 scripts
30 sa@wks:~/work/git/git$ git log Makefile | grep ^commit | wc -l
31 425
32 sa@wks:~/work/git/git$ git log scripts/ | grep ^commit | wc -l
33 919
A notion of file content
Which commits played a role in adding or removing file data containing
the string googlegroups? The answer is right below. -S is just one of
many options to git diff-tree (see above).
34 sa@wks:~/work/git/git$ git log -S'googlegroups' | grep ^commit | wc -l
35 3
Output formating, Combining Commands, Statistics, Patches
I leave it to the reader to go over the following lines and figure
things out — in essence, we can see how to combine several of the
commands used so far (e.g. line 95). We also use objects names not
just branches or tags. Another thing we are doing is to list the patch
that goes with a particular commit.
Sometimes we are only interested in commits that do not involve
merging. Statistics about what and how much was committed are also
interesting and last but not least we can see how to change to order
of commits listed.
36 sa@wks:~/work/git/git$ git log --pretty=oneline -n2 v2.6.29-rc3..
37 ae1a25da8448271a99745da03100d5299575a269 Merge git://git.kernel.org/pub/scm/linux/kernel/git/maso
38 fd9fc842bbab0cb5560b0d52ce4598c898707863 eCryptfs: Regression in unencrypted filename symlinks
39 sa@wks:~/work/git/git$ git log --stat -n1 fd9fc842bbab0cb5560b0d52ce4598c898707863
40 commit fd9fc842bbab0cb5560b0d52ce4598c898707863
41 Author: Tyler Hicks <[email protected]>
42 Date: Fri Feb 6 18:06:51 2009 -0600
43
44 eCryptfs: Regression in unencrypted filename symlinks
45
46 The addition of filename encryption caused a regression in unencrypted
47
48 [skipping a lot of lines...]
49
50 Signed-off-by: Tyler Hicks <[email protected]>
51 Signed-off-by: Linus Torvalds <[email protected]>
52
53 fs/ecryptfs/crypto.c | 4 ++--
54 1 files changed, 2 insertions(+), 2 deletions(-)
55 sa@wks:~/work/git/git$ git log -p -n1 fd9fc842bbab0cb5560b0d52ce4598c898707863
56 commit fd9fc842bbab0cb5560b0d52ce4598c898707863
57 Author: Tyler Hicks <[email protected]>
58 Date: Fri Feb 6 18:06:51 2009 -0600
59
60 eCryptfs: Regression in unencrypted filename symlinks
61
62 The addition of filename encryption caused a regression in unencrypted
63
64 [skipping a lot of lines...]
65
66 Signed-off-by: Tyler Hicks <[email protected]>
67 Signed-off-by: Linus Torvalds <[email protected]>
68
69 diff --git a/fs/ecryptfs/crypto.c b/fs/ecryptfs/crypto.c
70 index c01e043..f6caeb1 100644
71 --- a/fs/ecryptfs/crypto.c
72 +++ b/fs/ecryptfs/crypto.c
73 @@ -1716,7 +1716,7 @@ static int ecryptfs_copy_filename(char **copied_name, size_t *copied_name_size,
74 {
75 int rc = 0;
76
77 - (*copied_name) = kmalloc((name_size + 2), GFP_KERNEL);
78 + (*copied_name) = kmalloc((name_size + 1), GFP_KERNEL);
79 if (!(*copied_name)) {
80 rc = -ENOMEM;
81 goto out;
82 @@ -1726,7 +1726,7 @@ static int ecryptfs_copy_filename(char **copied_name, size_t *copied_name_size,
83 * in printing out the
84 * string in debug
85 * messages */
86 - (*copied_name_size) = (name_size + 1);
87 + (*copied_name_size) = name_size;
88 out:
89 return rc;
90 }
91 sa@wks:~/work/git/git$ git log scripts/ | grep ^commit | wc -l
92 919
93 sa@wks:~/work/git/git$ git log --no-merges scripts/ | grep ^commit | wc -l
94 854
95 sa@wks:~/work/git/git$ git log --no-merges -S'KBUILD_VERBOSE' scripts/ | grep ^commit | wc -l
96 3
97 sa@wks:~/work/git/git$ git log -n4 --pretty=format:'%h : %s' --date-order --graph
98 * ae1a25d : Merge git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-unstable
99 |\
100 * | fd9fc84 : eCryptfs: Regression in unencrypted filename symlinks
101 * | eeb9485 : Merge branch 'x86/fixes' of git://git.kernel.org/pub/scm/linux/kernel/git/frob/linux-2.6-roland
102 |\ \
103 | * | c09249f : x86-64: fix int $0x80 -ENOSYS return
104 sa@wks:~/work/git/git$
Naming commits with git show
We have seen several ways of specify commits already:
- 40-hexdigit object name: also known as SHA1 also known as
commit ID
- branch name: refers to the commit at the head of the given branch
- tag name: refers to the commit pointed to by the given tag (we have
seen branches and tags are special cases of references).
HEAD: refers to the head of the current branch
sa@wks:~/work/git/git$ git show -n1 ae1a25 | head -n3
commit ae1a25da8448271a99745da03100d5299575a269
Merge: fd9fc84... 42f15d7...
Author: Linus Torvalds <[email protected]>
sa@wks:~/work/git/git$ git show -n1 master | head -n3
commit ba743d1b0ce0b44c797c0de06c9db2781e4d1fdd
Merge: 7b75b33... 441adf0...
Author: Junio C Hamano <[email protected]>
sa@wks:~/work/git/git$ git show -n1 v2.6.29-rc3 | head -n3
tag v2.6.29-rc3
Tagger: Linus Torvalds <[email protected]>
Date: Wed Jan 28 10:49:44 2009 -0800
sa@wks:~/work/git/git$ git show -n1 HEAD | head -n3
commit ae1a25da8448271a99745da03100d5299575a269
Merge: fd9fc84... 42f15d7...
Author: Linus Torvalds <[email protected]>
sa@wks:~/work/git/git$
There are many more ways to specify commits as the specifying
revisions section of the git rev-parse man page shows. Some examples
are:
$ git show fb47ddb2 # the first few characters of the object name are usually enough to specify it uniquely
$ git show HEAD^ # the parent of the HEAD commit
$ git show HEAD^^ # the grandparent
$ git show HEAD~4 # the great-great-grandparent
Merge commits may have more than one parent. By default, ^ and ~
follow the first parent listed in the commit, but we can also choose:
$ git show HEAD^1 # show the first parent of HEAD
$ git show HEAD^2 # show the second parent of HEAD
In addition to HEAD, there are several other special names for
commits. Merges (to be discussed later), as well as operations such as
git reset, which change the currently checked-out commit, generally
set ORIG_HEAD to the value HEAD had before the current operation.
The git fetch operation always stores the head of the last fetched
branch in FETCH_HEAD. For example, if we run git fetch without
specifying a local branch as the target of the operation i.e. $ git
fetch git://example.com/proj.git theirbranch, then the fetched commits
will still be available from FETCH_HEAD.
When we discuss merges later on, we will also see the special name
MERGE_HEAD, which refers to the other branch that we are merging in to
the current branch.
We have used git rev-parse already. As we know, it is an
ancillary GIT command that is occasionally useful for translating some
name for a commit to the object name for that commit:
sa@wks:~/work/git/git$ git rev-parse origin
ba743d1b0ce0b44c797c0de06c9db2781e4d1fdd
sa@wks:~/work/git/git$ git rev-parse linux_nfs_devel
ae1a25da8448271a99745da03100d5299575a269
sa@wks:~/work/git/git$ git rev-parse FETCH_HEAD
ae1a25da8448271a99745da03100d5299575a269
sa@wks:~/work/git/git$ git rev-parse HEAD
ae1a25da8448271a99745da03100d5299575a269
sa@wks:~/work/git/git$
Tags
Now we are going to take a closer look at tags. How can we specify
them, create them and finally use them to explore a repositories
history.
Naming branches, tags, and other references
Branches, remote-tracking branches, and tags are all references to
commits. We already know this. All references are named with a
slash-separated path name starting with refs. The names we have been
using so far are actually shorthand for:
- The branch
test is short for refs/heads/test.
- The tag
v2.6.28 is short for refs/tags/v2.6.28.
origin/master is short for refs/remotes/origin/master.
The full name is occasionally useful if, for example, there ever
exists a tag and a branch with the same name.
Newly created references are actually stored in the .git/refs
directory, under the path given by their name. However, for efficiency
reasons they may also be packed together in a single file (see man 1
git-pack-refs).
As another useful shortcut, the HEAD of a repository can be referred
to just using the name of that repository. So, for example, origin is
usually a shortcut for the branch head in the repository origin.
Creating tags
Above, when talking about branches, we have already seen how to create
a tag. What we did there was to create a tag object. However, we can
also create a so-called lightweight tag — this involves no tag object
and therefore no comment message (-m) and no of a commit (i.e. tag
object).
1 sa@wks:~/work/git/git$ git tag | wc -l
2 387
3 sa@wks:~/work/git/git$ git tag -u Markus -m "A real tag: with messge and signed" my_real_tag
4
5 You need a passphrase to unlock the secret key for
6 user: "Markus Gattol () <foo[at]bar.org>"
7 1024-bit DSA key, ID C0EC7E38, created 2009-02-06
8
9 sa@wks:~/work/git/git$ git tag my_lightweight_tag $(git rev-parse HEAD)
10 sa@wks:~/work/git/git$ git tag | wc -l
11 389
12 sa@wks:~/work/git/git$ git tag -v my_lightweight_tag
13 error: ae1a25da8448271a99745da03100d5299575a269: cannot verify a non-tag object of type commit.
14 error: could not verify the tag 'my_lightweight_tag'
15 sa@wks:~/work/git/git$ git tag -v my_real_tag
16 object ae1a25da8448271a99745da03100d5299575a269
17 type commit
18 tag my_real_tag
19 tagger markus gattol <sa@wks.(none)> 1234186536 +0100
20
21 A real tag: with messge and signed
22 gpg: Signature made Mon 09 Feb 2009 02:35:36 PM CET using DSA key ID C0EC7E38
23 gpg: Good signature from "Markus Gattol () <foo[at]bar.org>"
24 sa@wks:~/work/git/git$
As can be seen from lines 2 and 11, we created two tags, my_real_tag
in line 3 and my_lightweight_tag in line 9 (note the use of git
rev-parse in order to supply an object name). In line 3, I signed and
supplied a comment message but did not supply an object name as I did
in line 9, resulting in the creation of a tag object which we take a
look at in lines 15 to 23.
If we do specify an object name however as we did in line 9, then no
tag object is created — only a reference to some commit. We see proof
of this in lines 12 to 14.
Tags and Repository History
A tag, well, is a tag. Humans put them on the work they do in order to
mark their achievements. For example, we are working on a long therm
goal. On our journey of getting there we pass milestones — projects
states that describe or relate to achieving a high-level intermediary
step on our way towards the final goal.
A good example is the Linux kernel. There we got version numbers like
those which can be seen in lines 2 to 5 below. Those tags reflect
milestones for the Linux kernel. We create those tags on projects as
time progresses which can be seen when we compare the date when tags
have been made (taggerdate) with their tag names (lines 7 to 10).
1 sa@wks:~/work/git/git$ git tag | tail -n4
2 v2.6.29-rc1
3 v2.6.29-rc2
4 v2.6.29-rc3
5 v2.6.29-rc4
6 sa@wks:~/work/git/git$ git-for-each-ref --format="%(refname) %(taggerdate:relative)" --sort=taggerdate refs/tags/v2.6.29*
7 refs/tags/v2.6.29-rc1 4 weeks ago
8 refs/tags/v2.6.29-rc2 3 weeks ago
9 refs/tags/v2.6.29-rc3 12 days ago
10 refs/tags/v2.6.29-rc4 23 hours ago
11 sa@wks:~/work/git/git$ git-for-each-ref --format="%(refname) %(objectname) %(taggerdate:relative)" --sort=taggerdate refs/tags/v2.6.29*
12 refs/tags/v2.6.29-rc1 7a3862d6e9934ffe107fe7ddfbe2c63dba321793 4 weeks ago
13 refs/tags/v2.6.29-rc2 d31ce8060b0e875179ba5ca1d40475dc2a082cc7 3 weeks ago
14 refs/tags/v2.6.29-rc3 8be00154b8e949bf4b89ac198aef9a247532ac2d 12 days ago
15 refs/tags/v2.6.29-rc4 87c16e9e8bb74f14f4504305957e4346e7fc46ea 23 hours ago
In lines 12 to 15 we have the same information as in lines 7 to 10
plus the actual object names (40-hexdigit string that is). So, what
has all this to do with a repositories history?
Let us assume that the commit
16 sa@wks:~/work/git/git$ git rev-parse v2.6.29-rc2^
17 71556b9800fff8bf59075d2c1622acc9d99113ef
fixed a certain problem. Now we would like to find the earliest tagged
release that contains that fix. Of course, there may be more than one
answer — if the history branched after commit
71556b9800fff8bf59075d2c1622acc9d99113ef, then there could be multiple
earliest tagged releases.
We could just visually inspect the commits since
71556b9800fff8bf59075d2c1622acc9d99113ef using gitk as the image below
shows. That works fine but then, well, I assume most folks are more
comfortable with the CLI simply because time matters.
A CLI junkie like me would rather use something like git name-rev,
which will give the commit a name based on any tag it finds pointing
to one of the commit's descendants i.e. in our current case, we can
see that 71556b9800fff8bf59075d2c1622acc9d99113ef is the parent of the
commit referenced by a tag object, which is itself referenced by the
tag v2.6.29-rc2.
18 sa@wks:~/work/git/git$ git name-rev 71556b98
19 71556b98 tags/v2.6.29-rc2~1
git describe does the opposite, naming the most recent tag that is
reachable from a commit. That may sometimes help us guess which tags
might come after the given commit.
20 sa@wks:~/work/git/git$ git describe $(git rev-parse v2.6.29-rc2^)
21 v2.6.29-rc1-611-g71556b9
If we just want to verify whether a given tagged version contains a
given commit, we could use git merge-base:
22 sa@wks:~/work/git/git$ git merge-base $(git rev-parse v2.6.29-rc1) $(git rev-parse v2.6.29-rc2)
23 c59765042f53a79a7a65585042ff463b69cb248c
24 sa@wks:~/work/git/git$ git name-rev c59765042f53a79a7a6
25 c59765042f53a79a7a6 tags/v2.6.29-rc1^0
26 sa@wks:~/work/git/git$
git merge-base finds a common ancestor of the given commits, and
always returns one or the other in the case where one is a descendant
of the other. The above output shows that
c59765042f53a79a7a65585042ff463b69cb248c actually is an ancestor of
v2.6.29-rc2.
Dealing with Regressions
What a regression is can be read here. How do regressions happen?
Suppose version v2.6.28-rc2 of our project worked, but the version at
master crashes. Sometimes the best way to find the cause of such a
regression is to perform a brute-force search through the project's
history to find the particular commit that caused the problem. git
bisect can help us do this:
1 sa@wks:~/work/git/git$ git bisect start
2 sa@wks:~/work/git/git$ git branch
3 linux_nfs_devel
4 * master
5 sa@wks:~/work/git/git$ git bisect good $(git rev-parse v2.6.28-rc2)
6 sa@wks:~/work/git/git$ git bisect bad master
7 Bisecting: 8736 revisions left to test after this
8 [8807d321af394ffb2180d085669337bcd5018c50] Merge branch 'maint'
9 sa@wks:~/work/git/git$ git branch
10 * (no branch)
11 linux_nfs_devel
12 master
If we run git branch at this point, we will see that GIT has
temporarily moved us in (no branch) as can be seen in line 10. HEAD is
now detached from any branch and points directly to the commit
(8807d321af394ffb2180d085669337bcd5018c50) that is reachable from
master but not from v2.6.28-rc2. Since it is obvious that we are
currently dealing with the Linux kernel source code, we compile and
test it, and see whether it crashes. Assuming it does crash, we tell
GIT (line 13).
13 sa@wks:~/work/git/git$ git bisect bad
14 Bisecting: 4367 revisions left to test after this
15 [568907f52051f340dc29a907f67e69260d7d4e7a] Added logged warnings for CVS error returns
16 sa@wks:~/work/git/git$ git rev-parse HEAD
17 568907f52051f340dc29a907f67e69260d7d4e7a
18 sa@wks:~/work/git/git$ git good
19 git: 'good' is not a git-command. See 'git --help'.
20 sa@wks:~/work/git/git$ git bisect good
21 Bisecting: 2183 revisions left to test after this
22 [a153adf683d2b6e22c7e892ed8a161b140156186] gitweb: Fix setting $/ in parse_commit()
23 sa@wks:~/work/git/git$ git bisect bad
24 Bisecting: 1091 revisions left to test after this
25 [65a4e98a22eab9317a05d1485c7c5a9c5befd589] Git.pm: Don't #define around die
26 sa@wks:~/work/git/git$ git rev-parse HEAD
27 65a4e98a22eab9317a05d1485c7c5a9c5befd589
28 sa@wks:~/work/git/git$ git branch
29 * (no branch)
30 linux_nfs_devel
31 master
32 sa@wks:~/work/git/git$ git bisect reset
33 Switched to branch "master"
34 sa@wks:~/work/git/git$ git branch
35 linux_nfs_devel
36 * master
37 sa@wks:~/work/git/git$
In line 14 we can see that we currently have 4367 revisions/commits
left that might turn out to be the culprit. What line 13 actually does
is to check out an older revision, again we compile and see if it
crashes. We continue like this, telling GIT at each stage whether the
revision/commit it gives us is good or bad.
git bisect does not work in a linear manner trough all potential
culprits but rather uses a principle know as divide and conquer. Thus,
notice that the number of revisions/commits left to test is cut
approximately in half each time as lines 14, 21 and 24 show.
After some time, it will output the commit ID of the guilty commit. We
can then examine the commit with git show, find out who wrote it, and
mail them our bug report with the commit ID. Finally, in line 32, we
use git bisect reset to return to the branch we were on before.
Note that the revision which git bisect checks out for us at each
point is just a suggestion, and we are free to try a different version
if we think it would be a good idea. For example, occasionally we may
land on a commit that broke something unrelated. We could then run git
bisect visualize which will run gitk and label the commit it chose
with a marker that says bisect. Then we choose a safe-looking commit
nearby, note its commit ID, and check it out with for example git
reset --hard <safe_looking_commit_ID>. We then test again, run bisect
good or bisect bad as appropriate, and continue.
Instead of git bisect visualize and then git reset --hard..., we
might just want to tell GIT that we want to skip the current commit
(git bisect skip). In this case, though, GIT may not eventually be
able to tell the first bad one between some first skipped commits and
a later bad commit.
There are also ways to automate the bisecting process if we have a
test script that can tell a good from a bad commit. man 1 git-bisect
has a lot more information about this and other git bisect features.
Viewing old Revisions of some File
We can always view an old version of a file by just checking out the
correct revision first. But sometimes it is more convenient to be able
to view an old revision of a single file without checking anything
out. The command in line 28 does just that. The command in line 3 is
just an alias in my ~/.bashrc.
1 sa@wks:~/work/git/git$ type pi
2 pi is aliased to `ls -la | grep'
3 sa@wks:~/work/git/git$ pi READ
4 -rw-r--r-- 1 sa sa 2166 2009-02-10 13:29 README
5 sa@wks:~/work/git/git$ git show $(git log -n1 --no-merges --pretty=oneline README | cut -d' ' -f1)
6 commit 8a124b82a03240b10c83085559e5988bc92ea7e2
7 Author: Joey Hess <[email protected]>
8 Date: Tue Jan 6 23:23:37 2009 -0500
9
10 README: tutorial.txt is now called gittutorial.txt
11
12 Signed-off-by: Joey Hess <[email protected]>
13 Signed-off-by: Junio C Hamano <[email protected]>
14
15 diff --git a/README b/README
16 index 548142c..5fa41b7 100644
17 --- a/README
18 +++ b/README
19 @@ -24,7 +24,7 @@ It was originally written by Linus Torvalds with help of a group of
20 hackers around the net. It is currently maintained by Junio C Hamano.
21
22 Please read the file INSTALL for installation instructions.
23 -See Documentation/tutorial.txt to get started, then see
24 +See Documentation/gittutorial.txt to get started, then see
25 Documentation/everyday.txt for a useful minimum set of commands,
26 and "man git-commandname" for documentation of each command.
27 CVS users may also want to read Documentation/cvs-migration.txt.
28 sa@wks:~/work/git/git$ git show $(git rev-parse v2.6.29-rc1):README | head
29 Linux kernel release 2.6.xx <http://kernel.org/>
30
31 These are the release notes for Linux version 2.6. Read them carefully,
32 as they tell you what this is all about, explain how to install the
33 kernel, and what to do if something goes wrong.
34
35 WHAT IS LINUX?
36
37 Linux is a clone of the operating system Unix, written from scratch by
38 Linus Torvalds with assistance from a loosely-knit team of hackers across
39 sa@wks:~/work/git/git$
The command in line 5 is also interesting, showing us the last commit
that modified README whereas line 28 must not necessarily show a
commit which modifies README — it shows the current revision at that
point in time, nothing more, nothing less.
In line 28, before the colon may be anything that names a commit, and
after it may be any path to a file tracked by GIT, README in our case.
Grep through the entire History
We have git grep. Thing is, it only searches through the current
working tree and index but not through the entire branch history
i.e. if we had the string duckisenteingerman somewhere in a tracked
file in the past and then removed it, did a few commits, git grep
would not find it because it is not present in the current working
tree and/or index.
If we wanted to search through history as well, then we would use git
grep <regexp> $(git rev-list --all) e.g. git grep duckisenteingerman
$(git rev-list --all) would reveal that we indeed had
duckisenteingerman in one of our tracked files at some point.
Repository Maintenance and Efficiency
There are basically two commands to maintain a repository and one
particular with regards to storage capacity:
git fsck: Verifies the connectivity and validity of the objects in the database.git gc: Which we already used, runs a number of housekeeping tasks
within the current repository, such as compressing file revisions
(to reduce diskspace and increase performance) and removing
unreachable objects which may have been created from prior
invocations of git-add. Users are encouraged to run this task on a
regular basis within each repository to maintain good diskspace
utilization and good operating performance.git clone --shared: What happens if we fork some code n times? Do
we need n times the storage space? Does it matter to think about
it? Yes. Imagine we keep 137 different GNOME (GNU Network Object
Model Environment) forks — the are all different but probably 60%
of the code is the same for all of them so why not share that
instead of copying it n times. git clone --shared to the rescue!
When the repository to clone is on the local machine, instead of
using hard links, automatically setup .git/objects/info/alternates
to share the objects with the source repository. The resulting
repository starts out without any object of its own. Note, this is
a possibly dangerous operation; do not use it unless you understand
what it does. If you clone your repository using this option and
then delete branches (or use any other GIT command that makes any
existing commit unreferenced) in the source repository, some
objects may become unreferenced (or dangling). These objects may be
removed by normal GIT operations (such as git-commit) which
automatically call git gc --auto. If these objects are removed and
were referenced by the cloned repository, then the cloned
repository will become corrupt.
Configure GIT
GIT has various things that can be configured. Almost anything can be
done with git config which eases the task of configuring GIT a lot.
Things that can be configured are
git config takes commands from the CLI (Command Line Interface) and
writes them to configuration files.
GIT's Configuration Files
If not set explicitly with --file, there are three files where
git config will search for configuration options:
$GIT_DIR/config: repository specific configuration file. The
filename is of course relative to the repository root, not the
working directory; see below.~/.gitconfig: user-specific configuration file. Also called global
configuration file.$(prefix)/etc/gitconfig: System-wide configuration file.
If no further options are given, all reading options will read all of
these files that are available. If the global or the system-wide
configuration files are not available (which is the default) they will
be ignored. If the repository configuration file is not available or
readable, git config will exit with a non-zero error code. However, in
neither case will an error message be issued.
All writing options will per default write to the repository specific
configuration file. Note that this also affects options like
--replace-all and --unset. git config will only ever change one file
at a time.
We can override these rules either by command line options or by
environment variables — both cases will be shown further down.
The --global and the --system options will limit the file used to the
global or system-wide file respectively.
The GIT_CONFIG environment variable has a similar effect, but we can
specify any filename we want. The GIT_CONFIG_LOCAL environment
variable on the other hand only changes the name used instead of the
repository configuration file. The global and the system-wide
configuration files will still be read — for writing options this
will obviously result in the same behavior as using GIT_CONFIG.
Basic Settings
Let us first create a new playground in lines 1 to 6 and also take a
look at $GIT_DIR/config in lines 8 to 12.
1 sa@wks:/tmp$ mkdir test && cd test && cp /home/sa/.emacs .
2 sa@wks:/tmp/test$ git init && git add . && git commit -a -m "Initial Commit."
3 Initialized empty Git repository in /tmp/test/.git/
4 Created initial commit 8b1a702: Initial Commit.
5 1 files changed, 5609 insertions(+), 0 deletions(-)
6 create mode 100644 .emacs
7 sa@wks:/tmp/test$ cat .git/config
8 [core]
9 repositoryformatversion = 0
10 filemode = true
11 bare = false
12 logallrefupdates = true
13 sa@wks:/tmp/test$ cd
I am not going to talk about the default options listed within the
[core] stanza since the manual file explains it in detail. Those
settings are sane and we should not ever need to change them... at
least I never had/wanted to...
What we are really after right now is putting the some basic
configuration settings into our global GIT configuration file i.e.
~/.gitconfig respectively /home/sa/.gitconfig in my case.
14 sa@wks:~$ pi gitcon
15 sa@wks:~$ git config --global user.name "Markus Gattol"
16 sa@wks:~$ pi gitcon
17 -rw-r--r-- 1 sa sa 24 2009-02-10 18:45 .gitconfig
18 sa@wks:~$ cat .gitconfig
19 [user]
20 name = Markus Gattol
21 sa@wks:~$ git config --global user.email "[email protected]"
22 sa@wks:~$ git config --global user.signingkey "Markus"
In 14 I am just checking (using an alias from my ~/.bashrc) whether or
not a ~/.gitconfig is in place or not. It is has not been created yet.
By issuing line 15 we not just create it but we also but something in
it as can be seen in lines 19 to 20.
One might consult the manual page (man 1 git-config) or other
literature for further information on particular configuration options
like for example user.name respectively study the various
configuration files that can be found on the Internet.
Finally, after issuing line 15, line 21 and 22 are responsible for
putting the last bits and pieces of basic configuration information
into place. Those three basically tell GIT who we are and how to
contact us — enough to work and carry out the most of the tasks GIT
can be used for.
Nice-to-have Settings
Besides the basic configuration information we can put a lot more into
our configuration files as can be seen below.
23 sa@wks:~$ git config --global core.excludesfile ~/.gitignore
24 sa@wks:~$ git config --global alias.lcr "cat-file commit HEAD"
25 sa@wks:~$ git config --global alias.com "commit -a -s"
26 sa@wks:~$ git config --global alias.st "status"
27 sa@wks:~$ git config --global alias.che "checkout"
28 sa@wks:~$ git config --global alias.llnm "log -n6 --no-merges HEAD"
29 sa@wks:~$ git config --global alias.ll "log -n6 HEAD"
Line 23 is used to tell GIT about our ignorefile — a file, filled
with globs, in order to ignore particular files like for example
editor backup files, files ending in .html, etc. (more on that later).
Note that ~/.gitignore is now an ignore file specific to some user
i.e. in our case, it affects all repositories which the user sa works
on. If somebody would clone one of sa repositories then this person
would have to have his own ~/.gitignore.
In order to ignore files in a repository basis and not on a per user
basis, we would put a .gitignore into the top root of the repositories
working tree directory ($GIT_WORK_TREE).
For example, the repository /path/to/repo with its $GIT_DIR at
/path/to/repo/.git would have a /path/to/repo/.gitignore. This ignore
file would then take effect recursively on the whole repository and
for all clones i.e. for anybody who works on this project.
Line 24 to 29 are aliases. Let us take a look at line 24 for example.
When I type git lcr (last commit raw), GIT would expand this to git
cat-file commit HEAD and thus save me some typing. Lines 25 to 27 are
self-explanatory. In line 28 I am looking issuing a command to show me
the last n logs (no merges) and line 29 can be read as last n logs
(including merges).
One might have noticed the -s switch in line 25. This adds a
Signed-off-by line at the end of the commit message (see images
below). Some projects like for example the Linux kernel require this
in order to track the chain of people some code changes moves along
e.g. it allows to trace the path from Linus Torvalds back through any
intermediaries (who committers, reviewers, etc.) involved with some
patch — all the way back to the original author of the patch
actually.
I, as many others, consider this best practices and therefore,
whenever I commit, I sign off the commit. Anybody should do this in
fact. Note, that signing of a commit has noting to do with
digitally signing a commit so do not confuse them.
If the alias expansion is prefixed with an exclamation point, it will
be treated as a shell command. For example, defining alias.new =
!gitk --all --not ORIG_HEAD, the invocation git new is
equivalent to running the shell command gitk --all --not ORIG_HEAD.
What about some colored output? Well, git config --global color.ui
true is our friend in this regard. The first screenshot below features
three vertical windows — the left and right one pretty much show the
same commands issued, once before GIT has been told to colorize output
(left window) and once afterwards (right window).
The fact that I am using GNU Emacs respectively Bash from within Emacs
should not confuse the reader as the same commands produce exactly the
same results from a native Bash CLI (Command Line Interface) as can be
seen in the second screenshot.

Finally, we can take a look at ~/.gitconfig in lines 30 to 47, it
contains all the configuration we issued above plus one more
configuration option in line 47 which has been created with git config
--global diff.renames copy. Again, the manual file explains this
option in detail.
30 sa@wks:~$ cat .gitconfig
31 [user]
32 name = Markus Gattol
33 email = [email protected]
34 signingkey = Markus
35 [core]
36 excludesfile = /home/sa/.gitignore
37 [alias]
38 lcr = cat-file commit HEAD
39 com = commit -a -s
40 st = status
41 che = checkout
42 llnm = log -n4 --no-merges HEAD
43 ll = log -n6 HEAD
44 [color]
45 ui = true
46 [diff]
47 renames = copy
48 sa@wks:~$ cat .gitignore
49 *\.~[[:digit:]]*
50 *.elc
51 *.[oa]
52 *.html
53 sa@wks:~$ alias | grep gllol
54 alias gllol='/usr/local/bin/git/my_show_recent_logs.sh'
55 sa@wks:~$ alias | grep gllol | cut -d \' -f2 | xargs cat
56 #! /bin/sh
57 git log -n15 --date=relative --pretty=format:'%H %cr CN: %cn AN: %an S: %s' | perl -lpe 's/\s+(.*?)(\s)\s/sprintf "%-20s", " $1"/eg'
58 sa@wks:~$
Above, in line 23, we told GIT where to find our ignore file.
Meanwhile I have created this file and filled with some sane ignore
patterns (lines 49 to 52). Line 49 will make GIT ignore backup files
created by GNU Emacs. Line 50 will ignore bytecompiled GNU Emacs
files. Line 51 will GIT make ignore object files (.o) as well as
archive files (.a). I also do not need GIT to track HTML files which I
tell it in line 52. One thing to note about ignore patterns with GIT
is, those patterns are not regular expressions but just globs...
The second screenshot above also shows a command which is an alias too
(gllol git last logs one line). Not one that can be found in
~/.gitconfig though but it is an alias in my ~/.bashrc, pointing to a
file (line 54) which contents can be seen in lines 56 and 57.
We could of course chose to put it directly into /usr/local/bin (which
certainly is the smarter thing to do) and thus effectively bypassing
~/.bashrc altogether. Of course we need to rename it from
my_show_recent_logs.sh to gllol so it becomes /usr/local/bin/gllol.
Also, the PATH environment variable must contain the absolute path to
it which it already does by default in Debian:
sa@wks:~$ echo $PATH
/usr/local/bin:/usr/bin:/bin:/usr/games
sa@wks:~$
Last but not least, and most importantly, what exactly does this
script (some may call it one-liner) do? Well, what it does is showing
me the last 15 commits, one per line, each with the commit name,
relative commit time, committer name, author name and the subject line
of the commit message.
Environment Variables
Aside from GIT_CONFIG and GIT_CONFIG_LOCAL from above, there are more
environment variables. Some like __git_commandlist for example which
we will not need and others, which can be seen below, which may come
in handy every now and then (more environment variables can be found
reading man 1 git-config).
The user's name and email address should be defined in the
configuration file (~/.gitconfig most likely). But sometimes it may be
useful to override this information for a short period of time. That
can be done with some environment variables:
$ export GIT_AUTHOR_NAME="Jenna Haze"
$ export GIT_COMMITTER_NAME="Jenna Haze"
$ export GIT_AUTHOR_EMAIL="[email protected]"
Merging
In this subsection we are going to take a look at merging. What
merging does is to join two or more development histories together.
With regards to merging, when we speak of histories, what we actually
referring to are branches. We can merge branches i.e. we are joining
development histories together.
We know three different types of merging:
- The merged commit is already contained in
HEAD. This is the
simplest case, called Already up-to-date.
HEAD is already contained in the merged commit. This is the most
common case especially when invoked from git pull — we are
tracking an upstream repository, have committed no local changes
and now you want to update to a newer upstream revision. Our HEAD
(and the index) is updated to point at the merged commit, without
creating an extra merge commit. This is called Fast-forward merge.- Both the merged commit and
HEAD are independent and must be tied
together by a merge commit that has both of them as its parents.
The rest of this section describes this True merge case.
Merge Tracking
Merge tracking is a facility offered by some SCM (Software
Configuration Management) systems. It is the ability to remember which
changes have been merged from one line of development (also known as
branch) to another and act accordingly. GIT records this information,
along with other information, in its commit objects.
Other systems not initially build with a notion of merge tracking in
mind, have lately started efforts in trying to provide it too. It
works fundamentally different though — compared to what GIT does, the
information needed for mergre tracking is stored on separate metadata
entities and a user has to explicitly flag merge commits manually
(something that GIT does automatically).
The problem with having system without automatic merge tracking is
that it is the responsibility of the user to manually record which
changes have been previously merged and act appropriately (for
example, by not attempting to merge the same change twice). This will
sooner or later lead to problems e.g. when someone flags the wrong
commit or simply forgets to do it entirely.
In all but the simplest cases of merging, merge tracking is a
significant time saver and a real convenience which encourages
developers to use branches in ways that improve their productivity and
the quality of their work.
A lack of merge tracking can actually be a disincentive for branching
at all, and for those that choose to branch anyway it can be a
significant drain on their time. Finally, one can be pretty sure to
mess up sooner or later by manually tracking things which might then
result in a disaster...
No merge Conflicts
Let us start with the most trivial case — merging two branches
whereas no merge conflict will arise.
1 sa@wks:~$ cd work/git/
2 sa@wks:~/work/git$ mkdir t
3 sa@wks:~/work/git$ cd t/
4 sa@wks:~/work/git/t$ touch some_file
5 sa@wks:~/work/git/t$ git init && git cwi
6 Initialized empty Git repository in /home/sa/work/git/t/.git/
7 sa@wks:~/work/git/t$ git st
8 # On branch master
9 #
10 # Initial commit
11 #
12 # Changes to be committed:
13 # (use "git rm --cached <file>..." to unstage)
14 #
15 # new file: some_file
16 #
17 sa@wks:~/work/git/t$ git cwh -m "initial commit"
18 [master (root-commit)]: created f4965fe: "initial commit"
19 0 files changed, 0 insertions(+), 0 deletions(-)
20 create mode 100644 some_file
21 sa@wks:~/work/git/t$ git st
22 # On branch master
23 nothing to commit (working directory clean)
24 sa@wks:~/work/git/t$ git branch
25 * master
There is really nothing special in lines 1 to 25. All we did was to
start a new repository from scratch. However, the commands used in
line 5 (git cwi) and line 17 (git cwh) are aliases (see below).
This has been discussed above already. Right now, this is what my
~/.gitconfig looks like:
sa@wks:~$ pwd
/home/sa
sa@wks:~$ cat .gitconfig
[user]
name = Markus Gattol
email = [email protected]
signingkey = Markus
[core]
excludesfile = /home/sa/.gitignore
[color]
ui = true
[alias]
# status
llnm = log -n6 --no-merges HEAD
ll = log -n6 HEAD
st = status
wc = whatchanged -n1
wcd = whatchanged -n1 -p
#diff
dwi = diff
dih = diff --cached
dwh = diff HEAD
dwt = diff --check
# commit
cwh = commit -a -s
cih = commit -s
cwi = add .
#misc
lcr = cat-file commit HEAD
[diff]
renames = copy
[rerere]
enabled = true
autoupdate = true
[gui]
recentrepo = /tmp/demo_git_source/git
[gc]
reflogexpire = 365
reflogexpireunreachable = 180
[push]
default = matching
sa@wks:~$
26 sa@wks:~/work/git/t$ git checkout -b my_first_branch
27 Switched to a new branch "my_first_branch"
28 sa@wks:~/work/git/t$ git branch
29 master
30 * my_first_branch
31 sa@wks:~/work/git/t$ echo "some text" > some_file
32 sa@wks:~/work/git/t$ git dwi
33 diff --git a/some_file b/some_file
34 index e69de29..7b57bd2 100644
35 --- a/some_file
36 +++ b/some_file
37 @@ -0,0 +1 @@
38 +some text
39 sa@wks:~/work/git/t$ git cwh -m "we made some changes to some_file"
40 [my_first_branch]: created 2667776: "we made some changes to some_file"
41 1 files changed, 1 insertions(+), 0 deletions(-)
Line 26 is where it starts to become interesting when we create and
switch to a new branch which we check issuing line 28. We are at
branch my_first_branch as we can see in line 30. Next we amend the
former created file some_file by putting some text into it.
Line 32 shows us the difference between the working tree and the index
which we then commit in line 39. At this point branch master and our
current branch (my_first_branch) have become different.
42 sa@wks:~/work/git/t$ git checkout master
43 Switched to branch "master"
44 sa@wks:~/work/git/t$ cat some_file
45 sa@wks:~/work/git/t$ git merge my_first_branch
46 Updating f4965fe..2667776
47 Fast forward
48 some_file | 1 +
49 1 files changed, 1 insertions(+), 0 deletions(-)
50 sa@wks:~/work/git/t$ cat some_file
51 some text
In line 42 we switch back from branch my_first_branch to branch
master. In line 44 we take a look at the contents of some_file — it
does not contain any contents since the command from line 31 happened
on branch my_first_branch and not our currently active branch (master)
although it is the same file (some_file).
The actual magic happens after we issued line 45. It tells GIT to
merge branch my_first_branch into our currently active branch. All
went well as can be seen from lines 46 to 49. All of a sudden
some_file contains content — line 51 is the result of line 31 from
above although it happened on another branch than the current one.
52 sa@wks:~/work/git/t$ git diff master my_first_branch
53 sa@wks:~/work/git/t$ echo "more text" >> some_file
54 sa@wks:~/work/git/t$ git diff master my_first_branch
55 sa@wks:~/work/git/t$ git cwh -m "and again, changes to some_file"
56 [master]: created 865e8b4: "and again, changes to some_file"
57 1 files changed, 1 insertions(+), 0 deletions(-)
58 sa@wks:~/work/git/t$ git diff my_first_branch
59 diff --git a/some_file b/some_file
60 index 7b57bd2..4bfbf30 100644
61 --- a/some_file
62 +++ b/some_file
63 @@ -1 +1,2 @@
64 some text
65 +more text
66 sa@wks:~/work/git/t$
Now branch master and branch my_first_branch are exactly the same
which we can see is true because line 52 outputs nothing. Then we add
content to the end of some_file in line 53 and check again in line 54.
Still no output, but why? We just made the branches different again?!
Sure we did but the getting no output at that point is actually
correct. Our changes did not made it into HEAD of our current branch
(master) and so, when line 54 was issued, the heads of both branches
actually still were identical.
After we commit in line 55, we can see that the heads of branch master
and branch my_first_branch actually differ again. We could now merge
the changes from master to my_first_branch, switch to my_first_branch,
do some work, merge back to master, etc.
It is exactly as simple and wild as it sounds. It is exactly as cool
as it sounds. It is exactly as helpful as it sounds. It is exactly
what we have already discussed before.
Encountering merge Conflicts
While the above example did not cause any conflicts while merging two
branches, we are now going to create a textbook case where it will
happen. However, before we start, I would like to take a look at some
goody called git rerere which allows to reuse recorded resolution of
conflicted merges. The reasons why we can use tools like git rerere
has been pointed out above already — without merge tracking this
would not be possible.
Another thing important to understand is that in case of a merge
conflict, until it is resolved, the index contains all versions of a
file:
- ours also known as stage2 i.e. the version in the branch we merge
into
- theirs also known as stage3 i.e. the version in the branch we are
merging from and
- base also known as stage1 i.e. the version in the common ancestor
of the branches and
- a version with conflict markers
Reuse Recorded Resolution
This comes in handy in a workflow that employs relatively long lived
topic branches. With such branches, the developer sometimes needs to
resolve the same conflict over and over again until the topic branches
are done (either merged to the release branch (yet another topic
branch), or sent out and accepted upstream).
So the users benefit is, git rerere helps this process by recording
conflicted automerge results and corresponding hand-resolve results on
the initial manual merge, and later by noticing the same automerge
results and applying the previously recorded hand resolution. Below
can be seen how to enable it in order to save us a lot of tedious
repetitive work.
sa@wks:~$ git config --global rerere.enabled true
sa@wks:~$ git config --global rerere.autoupdate true
sa@wks:~$ git config --get rerere.enabled
true
sa@wks:~$ git config --get rerere.autoupdate
true
sa@wks:~$
The merge Conflict
1 sa@wks:~/work/git/test$ type la && la
2 la is aliased to `ls -la'
3 total 0
4 drwxr-xr-x 2 sa sa 6 2009-02-17 20:15 .
5 drwxr-xr-x 11 sa sa 113 2009-02-17 18:08 ..
6 sa@wks:~/work/git/test$ touch file
7 sa@wks:~/work/git/test$ git init
8 Initialized empty Git repository in /home/sa/work/git/test/.git/
9 sa@wks:~/work/git/test$ git add .
10 sa@wks:~/work/git/test$ git cwh -m "initial commit"
11 [master (root-commit)]: created 623df59: "initial commit"
12 0 files changed, 0 insertions(+), 0 deletions(-)
13 create mode 100644 file
Nothing special in lines 1 to 13. Just a shell alias in line 1 and a
GIT alias in line 10 (cwh = commit -a -s).
14 sa@wks:~/work/git/test$ git checkout -b experimental
15 Switched to a new branch "experimental"
16 sa@wks:~/work/git/test$ echo a > file
17 sa@wks:~/work/git/test$ git cwh -m "altering file on branch experimental"
18 [experimental]: created 0247263: "altering file on branch experimental"
19 1 files changed, 1 insertions(+), 0 deletions(-)
20 sa@wks:~/work/git/test$ git checkout master
21 Switched to branch "master"
22 sa@wks:~/work/git/test$ git branch
23 experimental
24 * master
25 sa@wks:~/work/git/test$ echo b > file
26 sa@wks:~/work/git/test$ git cwh -m "altering file on branch master"
27 [master]: created 5f8d808: "altering file on branch master"
28 1 files changed, 1 insertions(+), 0 deletions(-)
Lines 14 to 28 are also rather unspectacular. All we did is checkout
(and thereby create) the branch experimental in line 14 and 15. In
line 16 we wrote some content into the file file and made a commit in
lines 17 to 19. Then we switched back to branch master and also wrote
some content (not a but b) into file as can be seen in line 25. With
line 26, we commit it from the working tree over the index right back
to the repository back end — doing so, HEAD gets advanced to point to
this commit.
29 sa@wks:~/work/git/test$ git merge experimental
30 Auto-merging file
31 CONFLICT (content): Merge conflict in file
32 Recorded preimage for 'file'
33 Automatic merge failed; fix conflicts and then commit the result.
34 sa@wks:~/work/git/test$ git log --merge
35 commit 5f8d808a4b820e46f9afcec73054c7c62aaafbf0
36 Author: Markus Gattol <[email protected]>
37 Date: Tue Feb 17 18:25:35 2009 +0100
38
39 altering file on branch master
40
41 Signed-off-by: Markus Gattol <[email protected]>
42
43 commit 024726369ba62f9e5f7533b91ff993f2dd14c3d7
44 Author: Markus Gattol <[email protected]>
45 Date: Tue Feb 17 18:25:09 2009 +0100
46
47 altering file on branch experimental
48
49 Signed-off-by: Markus Gattol <[email protected]>
The interesting part is when we try to merge branch experimental into
our currently active branch, branch master (lines 29 to 33). It fails
i.e. we got a merge conflict in file file (line 31).
For now, I just want the reader to recognize line 32 and recap what we
looked at earlier, when we were talking about
reuse recorded resolution, which merge tracking enables us to do. More
on that shortly...
git log --merge in line 34 shows refs that belong to files having a
conflict and do not exist on all heads to merge. If we compare lines
39 and 26 respectively lines 47 and 17, we can see that we are looking
at those commits that provoked the merge conflict. However, it would
also be nice to really see what the conflict is about instead of just
knowing about the involved commits.
50 sa@wks:~/work/git/test$ git diff experimental
51 diff --git a/file b/file
52 index 7898192..d7ef451 100644
53 --- a/file
54 +++ b/file
55 @@ -1 +1,5 @@
56 +<<<<<<< HEAD:file
57 +b
58 +=======
59 a
60 +>>>>>>> experimental:file
Line 50 issues the command that shows us the differences between
branch master and branch experimental. It is all about file file as we
see in line 51 and so forth. While file on branch master in line one
contains b, file on branch experimental in line one contains a — our
merge conflict that is!
61 sa@wks:~/work/git/test$ git ls-files -v -u file
62 M 100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 1 file
63 M 100644 61780798228d17af2d34fce4cfbdf35556832472 2 file
64 M 100644 78981922613b2afb6025042ff6bd878ac1994e85 3 file
65 sa@wks:~/work/git/test$ git show :1:file && echo "branch master, common ancestor"
66 branch master, common ancestor
67 sa@wks:~/work/git/test$ git show :2:file && echo "branch master, HEAD"
68 b
69 branch master, HEAD
70 sa@wks:~/work/git/test$ git show :3:file && echo "branch experimental, HEAD"
71 a
72 branch experimental, HEAD
If we recap, I mentioned something about stage files above. As of now
we have three — well, actually four, including the file with the
conflict markers — files involved with the merge (lines 62 to 64).
The columns are pretty much self-explaining — the last one says it is
about file file, the second to last one shows the stages per commit
i.e. either stage 1, stage 2 or stage 3.
In lines 65 to 72 we take a look at the contents of each, also telling
about what stage represents what file e.g. branch master, common
ancestor etc. For more information, please take a look above.
Stage 2 and 3 are no surprise as they are a result of line 25 and 16
respectively. What I want the reader to note here is that we get no
result from line 65 (except for the echo thingy). Why? Well, at the
time we started branching (line 14), the file file was empty and so
was it when we switched back to branch master in line 20. Then, while
on branch master again, we put b inside file and committed.
So the rationale why line 65 does not show anything is, because there
is nothing to show — the ancestor (line 62, ID e69de29bb2d...) of
commits 61780798... and 7898192261... points to file file at the time
where it had no contents.
73 sa@wks:~/work/git/test$ git branch
74 experimental
75 * master
76 sa@wks:~/work/git/test$ cat file
77 <<<<<<< HEAD:file
78 b
79 =======
80 a
81 >>>>>>> experimental:file
82 sa@wks:~/work/git/test$ echo a > file
83 sa@wks:~/work/git/test$ cat file
84 a
85 sa@wks:~/work/git/test$ git cwh -m "resolving merge conflict on branch master"
86 Recorded resolution for 'file'.
87 [master]: created 595ed02: "resolving merge conflict on branch master"
88 sa@wks:~/work/git/test$ git merge experimental
89 Already up-to-date.
90 sa@wks:~/work/git/test$ cat .git/rr-cache/0630df854874fc5ffb92a197732cce0d8928e898/preimage
91 <<<<<<<
92 a
93 =======
94 b
95 >>>>>>>
96 sa@wks:~/work/git/test$ cat .git/rr-cache/0630df854874fc5ffb92a197732cce0d8928e898/postimage
97 a
98 sa@wks:~/work/git/test$
At this point we know all we need to know. We know we have a merge
conflict and we also know what caused it and how to resolve it. In
order to resolve it, we can work on either one of the stage files 2
or 3. All three are in the index, file currently contains the conflict
markers as we can see in lines 77 to 80. In line 82 I opted to resolve
the conflict on stage file version 1 of file — all we need to do in
our current case is to put the same content on line one as is in stage
file 3 i.e. a in our current case.
Then we commit again and thereby resolve the merge conflict. Line 86
is about the same fabulous thing as is line 32 —
reuse recorded resolution. For it to work, the information how a merge
conflict was resolved needs to be stored somewhere — lines 90 to 97.
Finally I would like to add that the above scenario could have also
involved not just local branches but also remote branches, and even a
mixture of the both. And as always, specifying various commits can be
done in various ways.
Fixing Mistakes
 |
| ... long face after a big *PENG*... |
We all make mistakes all the time. In order for life to evolve we need
mistakes to happen.
Experience is that marvelous thing that enables you recognize a mistake
when you make it again.
— Franklin P. Jones
GIT can ease the pain after a mistake has been made. In most cases,
GIT can make it go away entirely by using one of three commands:
git resetgit revertgit checkout
The Mistake has not been committed yet
In case we messed up the working tree, but have not yet committed our
mistake, we can return the entire working tree as well as the index to
the last committed state with git reset --hard HEAD — aside from
--hard there two other switches to git reset which produce different
results. This is called a hard reset and cannot be undone!
1 sa@wks:/tmp$ mkdir test
2 sa@wks:/tmp$ cd test/
3 sa@wks:/tmp/test$ touch file_{a,b}
4 sa@wks:/tmp/test$ ll
5 total 0
6 -rw-r--r-- 1 sa sa 0 2009-02-18 18:24 file_a
7 -rw-r--r-- 1 sa sa 0 2009-02-18 18:24 file_b
8 sa@wks:/tmp/test$ git add .
9 fatal: Not a git repository (or any of the parent directories): .git
10 sa@wks:/tmp/test$ git init
11 Initialized empty Git repository in /tmp/test/.git/
12 sa@wks:/tmp/test$ git add .
13 sa@wks:/tmp/test$ git cwh -m "initial commit"
14 [master (root-commit)]: created 8eda414: "initial commit"
15 0 files changed, 0 insertions(+), 0 deletions(-)
16 create mode 100644 file_a
17 create mode 100644 file_b
18 sa@wks:/tmp/test$ rm file_b
19 sa@wks:/tmp/test$ echo "I will regret this" > file_a
20 sa@wks:/tmp/test$ ll
21 total 4.0K
22 -rw-r--r-- 1 sa sa 19 2009-02-18 18:25 file_a
23 sa@wks:/tmp/test$ cat file_a
24 I will regret this
25 sa@wks:/tmp/test$ git reset --hard HEAD
26 HEAD is now at 8eda414 initial commit
27 sa@wks:/tmp/test$ ll
28 total 0
29 -rw-r--r-- 1 sa sa 0 2009-02-18 18:25 file_a
30 -rw-r--r-- 1 sa sa 0 2009-02-18 18:25 file_b
31 sa@wks:/tmp/test$ cat file_a
In line 13 a usual commit happens. Then we mess up — line 18 and 19.
No problem, line 25 returns he working tree right to the state it had
been at line 13 i.e. file file_b is still around and file_a is empty.
The above example is trivial because no commit happened which would
already commit a mistake — the mess was contained to the working tree
and had not made it to the index or HEAD. But what if? What if we had
committed a mistake?
The Mistake has already been committed
If we make a commit that we later wish we had not, there are two
fundamentally different ways to fix the problem:
- We can create a new commit that undoes whatever was done by the
old commit. This is the correct thing if our mistake has already
been made public e.g. we used
git push.
- We can go back and modify the old commit. We should never do
this if we have already made the history public — GIT does not
normally expect the history of a project to change, and cannot
correctly perform repeated merges from a branch that has had its
history changed.
Fixing a mistake with a new commit
Creating a new commit that reverts an earlier change is easy. In order
to do so, the working tree must be clean. Then, all we need to do is
to pass a ref of the bad commit to git revert
e.g. to revert the most recent commit with git revert HEAD.
32 sa@wks:/tmp/test$ echo "making a mistake and committing it" > file_b
33 sa@wks:/tmp/test$ git cwh -m 'omg, I am committing a mistake'
34 [master]: created 0708ce3: "omg, I am committing a mistake"
35 1 files changed, 1 insertions(+), 0 deletions(-)
36 sa@wks:/tmp/test$ cat file_b
37 making a mistake and committing it
38 sa@wks:/tmp/test$ git revert HEAD
39
40
41 [ here the default editor opened...]
42
43
44 [master]: created 1bf6c3d: "Revert "omg, I am committing a mistake""
45 1 files changed, 0 insertions(+), 1 deletions(-)
46 sa@wks:/tmp/test$ cat file_b
47 sa@wks:/tmp/test$ gllol
48 1bf6c3d8de2942b9c7dc3c9a6f8dbdeedb39f32b 2 minutes ago CN: Markus Gattol AN: Markus Gattol S: Revert "omg, I am committing a mistake"
49 0708ce3f00eb4108bc36735641eaae46b948f84b 5 minutes ago CN: Markus Gattol AN: Markus Gattol S: omg, I am committing a mistake
50 8eda414d07791a8a1160a7b4ac5c913b1a06643d 42 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
51 sa@wks:/tmp/test$
As we can see in lines 32 to 51, reverting a change works just fine.
Line 36 and 46 proof it. What can now also be seen from lines 48 to 50
is that the command issued in line 25 did not create any commit but
either one, line 33 and 38 did. Those commits are now part of the
history which is perfectly fine even though they represent a back and
forth action. The point is, prior to it and also after it, the history
is coherent and intact.
Of course, we can also revert an earlier change, for example, the
grandparent git revert HEAD^. In this case GIT will attempt to undo
the old change while leaving intact any changes made since then. If
more recent changes overlap with the changes to be reverted, then we
will be asked to fix conflicts manually, just as in the case of
resolving a merge.
Going back even further is also possible (any ID is possible) but may
become more and more tricky based on the complexity of some project.
However, again, the point is, as long as the history is coherent and
intact, we will not make mistakes we cannot recover from... GIT just
prevents us from doing so as long as we are not explicitly fiddling
with the history on a low level.
Fixing a mistake by editing history
We have used git reset above already by undoing changes that had not
made it into the index and therefore also not into the back end of the
repository (HEAD). However, git reset can do more — we can set the
current head to any specified commit.
Optionally we can also reset the index and working tree to match that
commit if we use the --hard option. --mixed would only reset the index
but not the working tree and --soft would reset neither but only let
HEAD point to the specified commit.
If the problematic commit is the most recent commit, and we have not
yet made that commit public, then we may just destroy it using
git reset.
1 sa@wks:/tmp/test$ la
2 total 4
3 drwxr-xr-x 2 sa sa 6 2009-02-19 11:30 .
4 drwxrwxrwt 14 root root 4096 2009-02-19 11:18 ..
5 sa@wks:/tmp/test$ touch our_file
6 sa@wks:/tmp/test$ git init && git add .
7 Initialized empty Git repository in /tmp/test/.git/
8 sa@wks:/tmp/test$ git cwh -m 'initial commit'
9 [master (root-commit)]: created b076931: "initial commit"
10 0 files changed, 0 insertions(+), 0 deletions(-)
11 create mode 100644 our_file
12 sa@wks:/tmp/test$ echo "this will be corrected using --soft" > our_file
13 sa@wks:/tmp/test$ git cwh -m 'wrote some content into our_file'
14 [master]: created cb565f1: "wrote some content into our_file"
15 1 files changed, 1 insertions(+), 0 deletions(-)
16 sa@wks:/tmp/test$ gllol
17 cb565f167f1f8405edd940159763f79d2aef7f61 7 seconds ago CN: Markus Gattol AN: Markus Gattol S: wrote some content into our_file
18 b07693168359a71b6bb4635de6d62cb6f1119a76 73 seconds ago CN: Markus Gattol AN: Markus Gattol S: initial commit
19 sa@wks:/tmp/test$ cat .git/HEAD
20 ref: refs/heads/master
21 sa@wks:/tmp/test$ cat .git/refs/heads/master
22 cb565f167f1f8405edd940159763f79d2aef7f61
23 sa@wks:/tmp/test$ git reset --soft HEAD^
24 sa@wks:/tmp/test$ cat .git/ORIG_HEAD
25 cb565f167f1f8405edd940159763f79d2aef7f61
26 sa@wks:/tmp/test$
27 sa@wks:/tmp/test$ gllol
28 b07693168359a71b6bb4635de6d62cb6f1119a76 5 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
29 sa@wks:/tmp/test$ cat our_file
30 this will be corrected using --soft
31 sa@wks:/tmp/test$ echo 'editing working tree; --soft did not change the working tree nor the index' > our_file
32 sa@wks:/tmp/test$ git commit -a -c ORIG_HEAD
33
34
35 [ here the default editor opened...]
36
37
38 sa@wks:/tmp/test$ gllol
39 b8c2b79d917608d2ac08597ee8008a862ad47fe1 2 minutes ago CN: Markus Gattol AN: Markus Gattol S: wrote some content into our_file (corrected version)
40 b07693168359a71b6bb4635de6d62cb6f1119a76 9 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
41 sa@wks:/tmp/test$ cat .git/ORIG_HEAD
42 cb565f167f1f8405edd940159763f79d2aef7f61
43 sa@wks:/tmp/test$ cat .git/HEAD
44 ref: refs/heads/master
45 sa@wks:/tmp/test$ cat .git/refs/heads/master
46 b8c2b79d917608d2ac08597ee8008a862ad47fe1
What can be is most often done when we remember that what we just
committed is incomplete, or we misspelled our commit message, or both.
Again, I want to point out that this sort of fixing a mistake is
only recommended as long as the tainted commit/history has not been
made public.
That we really just replaced one commit with another one without
resetting the working tree can be seen from lines 17 and 22
respectively 39 and 46. git reset copies the old head to
.git/ORIG_HEAD so we can redo the commit by starting with its log
message — compare the log message we gave in line 13 to after it had
been edited in lines 33 to 37 i.e. compare lines 17 and 39.
Bottom line here is, we can replace a commit and edit its commit
message without destroying the working tree or the index. This is
different to git revert where we fix a mistake by making another
commit on top of the current history — this is how it should be done
if the repository history including the mistake has already been made
public.
Alternatively, we can edit the working directory and update the index
to fix our mistake, just as if we were going to create a new commit,
then run git commit --amend. The result with git commit --amend is the
same as with git reset --soft HEAD^ above but it can also be used to
amend a merge commit.
The commit git commit --amend we create replaces the current tip — if
it was a merge commit, it will have the parents of the current tip as
parents, the current top commit is discarded.
47 sa@wks:/tmp/test$ git st
48 # On branch master
49 nothing to commit (working directory clean)
50 sa@wks:/tmp/test$ ll
51 total 4.0K
52 -rw-r--r-- 1 sa sa 75 2009-02-19 11:38 our_file
53 sa@wks:/tmp/test$ cat our_file
54 editing working tree; --soft did not change the working tree nor the index
55 sa@wks:/tmp/test$ git commit --amend
56
57
58 [ here the default editor opened...]
59
60
61 [master]: created 12c9cf6: "wrote some content into our_file (corrected version of the corrected version)"
62 1 files changed, 1 insertions(+), 0 deletions(-)
63 sa@wks:/tmp/test$ gllol
64 12c9cf603286326553dcdc10b90086be5f62cd33 2 minutes ago CN: Markus Gattol AN: Markus Gattol S: wrote some content into our_file (corrected version of the corrected version)
65 b07693168359a71b6bb4635de6d62cb6f1119a76 2 hours ago CN: Markus Gattol AN: Markus Gattol S: initial commit
66 sa@wks:/tmp/test$ cat .git/refs/heads/master
67 12c9cf603286326553dcdc10b90086be5f62cd33
68 sa@wks:/tmp/test$ cat our_file
69 a
70 sa@wks:/tmp/test$
Ooops, we did it again ;-]...
We just swapped the old commit for a new one in line 55, just as we
did above in line 23. The new commit message can be seen in line 64
after I issued my well beloved gllol. The cherry on top thing is that,
the author and time stamp is not being altered by all the replacing
games we just did i.e. it is taken/reused from the commit in line 13.
Of course, we can also amend those (see manual files for detailed
information).
So, we swapped the commit again and we also edited the commit message
again and made changes to the working tree (our_file). All that is
possible because we were just toying with HEAD but not with the index
nor the working tree.
Again, we should never do this to a commit that may already have been
merged into another branch i.e. which has been made public — one
should use git revert instead in that case.
Checking out an old version of a file
In the process of undoing a previous bad change, we may find it useful
to check out an older version of a particular file using git checkout.
We have used git checkout before to switch branches, but it has quite
different behavior if it is given a path name.
git checkout HEAD^ path/to/file replaces path/to/file by the contents
it had in the commit HEAD^ (or any other commit ID for that matter),
and also updates the index to match. It does not change branches. In
case we did not want to overw
If we just want to look at an older version of the file, without
modifying the working directory, git show HEAD^:path/to/file is our
friend. Of course, in both cases HEAD^ can be replaced by
anything that names a commit.
1 sa@wks:/tmp$ mkdir git_demo && cd git_demo && touch my_file && git init && git add . && git cwh -m 'initial commit'
2 Initialized empty Git repository in /tmp/git_demo/.git/
3 [master (root-commit)]: created 89f870d: "initial commit"
4 0 files changed, 0 insertions(+), 0 deletions(-)
5 create mode 100644 my_file
6 sa@wks:/tmp/git_demo$ la
7 total 8
8 drwxr-xr-x 3 sa sa 31 2009-02-19 14:16 .
9 drwxrwxrwt 14 root root 4096 2009-02-19 14:16 ..
10 drwxr-xr-x 9 sa sa 4096 2009-02-19 14:16 .git
11 -rw-r--r-- 1 sa sa 0 2009-02-19 14:16 my_file
12 sa@wks:/tmp/git_demo$ git st
13 # On branch master
14 nothing to commit (working directory clean)
15 sa@wks:/tmp/git_demo$ type bani
16 bani is aliased to `banshee --query-{artist,title} >& `tty`'
17 sa@wks:/tmp/git_demo$ bani > my_file
18 sa@wks:/tmp/git_demo$ cat my_file
19 artist: Patricia Barber
20 title: Morpheus
21 sa@wks:/tmp/git_demo$ git cwh -m "Markus\'s current track"
22 [master]: created 83e5cf6: "Markus\'s current track"
23 1 files changed, 2 insertions(+), 0 deletions(-)
24 sa@wks:/tmp/git_demo$ banshee --query-{artist,title} | tee -a my_file && cat my_file
25 artist: Paul Hardcastle
26 title: Rain Forest
27 artist: Patricia Barber
28 title: Morpheus
29 artist: Paul Hardcastle
30 title: Rain Forest
31 sa@wks:/tmp/git_demo$ git cwh -m "last two tracks (including current one)"
32 [master]: created 5a978e9: "last two tracks (including current one)"
33 1 files changed, 2 insertions(+), 0 deletions(-)
Nothing special in lines 1 to 23. In line 24 I basically use the bani
alias (an alias to control banshee from the CLI (Command Line
Interface)) but this time without >& in order to get stdout (see here
and man bash for more information) redirected to the terminal so tee
can grab it and write it to stdout and into the file my_file as can be
seen in lines 25 to 30.
34 sa@wks:/tmp/git_demo$ git show HEAD^:my_file
35 artist: Patricia Barber
36 title: Morpheus
37 sa@wks:/tmp/git_demo$ cat my_file
38 artist: Patricia Barber
39 title: Morpheus
40 artist: Paul Hardcastle
41 title: Rain Forest
42 sa@wks:/tmp/git_demo$ git show HEAD:my_file
43 artist: Patricia Barber
44 title: Morpheus
45 artist: Paul Hardcastle
46 title: Rain Forest
47 sa@wks:/tmp/git_demo$ git checkout HEAD^ my_file
48 sa@wks:/tmp/git_demo$ cat my_file
49 artist: Patricia Barber
50 title: Morpheus
51 sa@wks:/tmp/git_demo$ git st
52 # On branch master
53 # Changes to be committed:
54 # (use "git reset HEAD <file>..." to unstage)
55 #
56 # modified: my_file
57 #
58 sa@wks:/tmp/git_demo$
Line 34 is a perfect example of how to use git show in order to take a
look at former revision of some file without changing it in the
working directory (lines 37 to 41). In line 47 we checkout a former
revision — in contrast to line 34, this amends the file my_file in
the working directory as can be seen in lines 48 to 50.
Sharing our Changes
Now is a good time to revisit the workflow section again. Sharing our
changes with others is one of the most important, if not the most
important purpose why one would want to use a SCM (Software
Configuration Management) system.
General Considerations
Before we start with detailed issues, there are some things we should
consider and keep in mind whenever we make commits and/or prepare
patches.
Suppose we are contributors to a large project, and we want to add a
complicated feature. We want to present it to the other developers in
a way that makes it easy for them to read our changes, verify that
they are correct, and understand why we made each change.
- If we present all of our changes as a single patch/commit, they may
find that it is too much to digest all at once.
- If we present them with the entire history of our work, complete
with mistakes, corrections, and dead ends, they may be overwhelmed.
So the ideal is usually to produce a series of patches/commits such
that the following checklist gets a nod on every item:
- Each patch/commit can be applied in order.
- Check for unnecessary whitespace with
git diff --check before
committing; maybe use a hook to automate it
- We should not check in commits which contain commented out code or
unneeded files.
- Provide a meaningful commit message.
- Add a
Signed-off-by: Your Name <[email protected]> line to the commit
message — use -s when committing or simply create an
alias in ~/.gitconfig. The signed-of-by message confirms that we
agree to the Developer's Certificate of Origin.
- Each patch/commit includes a single logical change (i.e. is
atomic), together with a message explaining the change.
- No patch/commit introduces a regression i.e. after applying any
initial part of the series, the resulting project still (compiles
and) works, and has no bugs that it did not have before.
- The complete series produces the same end result as our own
(probably much messier) development process did.
Below I will introduce some tools that can help us do this, explain
how to use them, and then explain some of the problems that can arise
because we are rewriting history.
Creating good Commit/Log Messages
Though not required, it is a good idea to begin the commit message
with a single short line summarizing the change, followed by a blank
line and then a more thorough description. Tools that turn commits
into email, for example, use the first line on the subject line and
the rest of the commit in the body.
Provide a GIT Repository to the Public
GITosis aims to make hosting GIT repositories easier and safer. It
manages multiple repositories under one user account, using SSH
(Secure Shell) keys to identify users. End users do not need their own
fully fledged user account on the server, they will all talk to one
shared user account that will not let them run arbitrary commands.
GITosis is written in Python which is why we are going to install it
too if not already installed — since we install software via APT
(Advanced Packaging Tool), Python will be installed as a dependency of
GITosis anyway.
There are other ways of providing a public repository as well e.g. not
using SSH for push and pull actions, creating a distinct user
account for any contributor, access via HTTP (Hypertext Transfer
Protocol) etc. All this works but I do not like it because there is
something better... there is GITosis!
I opted to only cover one particular use case which is the most secure
one, the one that scales best, and the one that CLI (Command Line
Interface) folks are most comfortable with i.e. I opted to cover
setting up a public GIT repository using GITosis.
Under the Hood
As we know, GIT does not need to be setup and run in a star topology
setup simply because it is no centralized SCM (Software Configuration
Management) system like for example SVN but, rather, it is a
decentralized SCM system which means, any clone contains the full
history (all commits ever made and the metadata information that goes
with it e.g. who did what and when) and can therefore be
merged/diffed/etc. back and forth with any other clone/branch out
there.
We can think of centralized SCM systems of enforcing the unavoidable
star topology on its usres, and of decentralized systems, well, as
everything from fully connected to star or, even better, anything that
can be seen below.
The point is, decentralized SCM systems, as opposed to centralized
ones, do not enforce silly limits with regards to topology and usage
but rather leave the choice to their users.
However, sometimes it makes sense to even use a decentralized SCM
system like GIT in a star topology — one such use case is with
GITosis, where we have one remote machine running GITosis and
therefore hosting GIT repositories for us. The GITosis machine makes
for the center of the star and we, the users, are all leaves the
central server running GITosis:
As already mentioned above, GITosis uses just a single system user
account for all repositories and users with write/commit/push
permissions to one or several of those repositories on the remote
machine e.g. the server within the datacenter that is going to host
our GIT repositories. This remote machine runs GITosis under the
system user account name gitosis. This system user account is
automatically created when we install the debian package gitosis i.e.
there is no need for us to issue adduser --system gitosis.
GITosis itself is basically just used to manage/control who can
write/commit/push to which repository — GITosis does not, because it
does not need to, be concerned about who can read/pull/fetch since
this can easily be done via GIT-daemon i.e. GIT-daemon can be used to
provide anonymous read/pull/fetch access to our repositories if
needed.
In order to differentiate amongst folks with write/commit/push
permissions, even though we only have one shared system user account
called gitosis, a users public SSH key is used by GITosis to
differentiate amongst users. Everybody who wants to write/commit/push
to a repository on the remote machine running GITosis, has to provide
the GITosis administrator with his public key so the he can place it
onto the remote machine where GITosis can access.
For those who's public key is placed onto the remote machine and
therefore GITosis does recognize them, read and write access, or
rather pull/fetch and push in GIT terms, then happens via SSH (Secure
Shell) i.e. it is secure. Read respectively pull/fetch access via
GIT-daemon, can, but does not have to be set up for SSH — that is
solely in the hands of the administrator of the GITosis server.
The PKA (Public Key Authentication) setup for the system user gitosis
makes use of additional security precautions i.e. even those with
write/commit/push permissions cannot execute arbitrary command on our
remote machine running GITosis.
Because of the fact that a system user account is used for the user
gitosis rather than a normal user account and the fact that the
command=<command_issued_when_public_key_authentication_is_ok>
part is present, on top of the PKA setup (password login is disabled),
GITosis is a rather secure thing to use even for a huge community if
need be.
Also, as for any other way of hosting GIT repositories, firewall
settings in table filter, chain OUTPUT and INPUT respectively FORWARD
in case of OpenVZ, have to allow port 9418. This is necessary for
GIT-daemon for example.
For those who have permissions to write/commit/push, the SSH service
ports are relevant thus the firewall has to allow the SSH port for
inbound and outbound traffic. Of course, we can and we will use a
non-standard listening port for sshd as we will see below. For the
more paranoid, even port knocking might be set up if needed — I leave
it to the particular user group to decide whether or not they might
find it to much of a hassle or not...
Installing and Configuring GITosis
1 sa@wks:~$ ssh dolmen-devel
2
3 / \ _-'
4 _/ \-''- _ /
5 __-' { \
6 / \
7 / "o. |o }
8 | \ ; YOU ARE BEING WATCHED!
9 ',
10 \_ __\
11 ''-_ \.//
12 / '-____'
13 /
14 _'
15 _-'
16
17
18 This computer system is the private property of its owner, whether individual, corporate or government. It is
19 for authorized use only. Users (authorized or unauthorized) have no explicit or implicit expectation of
20 privacy.
21
22 Any or all uses of this system and all files on this system may be intercepted, monitored, recorded, copied,
23 audited, inspected, and disclosed to your employer, to authorized site, government, and law enforcement
24 personnel, as well as authorized officials of government agencies, both domestic and foreign.
25
26 By using this system, the user consents to such interception, monitoring, recording, copying, auditing,
27 inspection, and disclosure at the discretion of such personnel or officials.
28
29
30 UNAUTHORIZED OR IMPROPER USE OF THIS SYSTEM MAY RESULT
31 IN CIVIL AND CRIMINAL PENALTIES AND ADMINISTRATIVE OR
32 DISCIPLINARY ACTION, AS APPROPRIATE !!
33
34
35 By continuing to use this system you indicate your awareness of and consent to these terms and conditions of
36 use. LOG OFF IMMEDIATELY if you do not agree to the conditions stated in this warning. However, if you are
37 authorized personal with no bad intentions please continue. Have a nice day! :-)
38
39 sa@rh0-ve3:~$ su
40 Password:
41 rh0-ve3:/home/sa# type dpl; dpl git* | grep ii
42 dpl is aliased to `dpkg -l'
43 ii git-core 1:1.6.3.3-1 fast, scalable, distributed revision control
44 ii gitosis 0.2+20080825-14 git repository hosting application
45 rh0-ve3:/home/sa# grep git /etc/passwd
46 gitosis:x:105:108:git repository hosting,,,:/srv/gitosis:/bin/sh
47 rh0-ve3:/home/sa# cd /srv/gitosis/
48 rh0-ve3:/srv/gitosis# type la; la
49 la is aliased to `ls -la'
50 total 8
51 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-09 12:53 .
52 drwxr-xr-x 3 root root 4096 2009-07-09 11:33 ..
53 lrwxrwxrwx 1 root root 25 2009-07-09 11:33 git -> /srv/gitosis/repositories
We are going to install GITosis on a remote machine located within a
datacenter. In order to do so, we use SSH (Secure Shell) to leave our
local machine, my workstation with its hostname wks, and log into the
remote machine (rh0-ve3) as can be seen from line 39. What can be seen
in lines 2 to 38 is just the usual banner message. The very short
command from line 1 is possible because all the sshd port information
of the remote machine etc. lives within my ~/.ssh/config.
These days, we make use of some virtualization technology of course.
In the current case we are going to use OpenVZ i.e. our remote machine
is a VE (Virtual Environment) which means it shares a HNs (Hardware
Nodes) resources with other VEs — a VE however behaves and feels no
differently than any non-virtualized Debian machine.
On the remote machine, we start with installing the gitosis package
which I already did as can be seen in line 44. For those who have not
installed it already, aptitude install gitosis will do the trick. dpl
in line 41 is just an aliases in my ~/.bashrc.
By installing gitosis, some work is done for us automatically like for
example setting up the system user account for the system user gitosis
(line 46, see man 5 passwd) and a location (line 53) where our
repositories will live is set up as well.
Next thing to do is to create a public SSH key for PKA (Public Key
Authentication) for the GITosis administrator account on the remote
machine running GITosis. That we need to do on our local machine i.e.
wks in my case and not on rh0-ve3.
-
Note, that theoretically the administrator might have three SSH
keypairs — one to log into the remote machine via PKA as usual. A
second one to administer GITosis and of course, a third SSH keypair in
case he is going to do some programming as well for any project hosted
by GITosis on his remote machine. However, it is better to have just
one SSH keypair per person and use the public key several times —
three times actually in our current case. And no, having three
keypairs is not more secure as compared to just having one (see link
below).
As the above link shows, I already have my SSH keypair and thus a
public SSH key (/home/sa/.ssh/ssh_pka_key_for_user_Markus_Ano.pub) which
we are now going to use for being the GITosis administrator as well —
a single SSH keypair can be used for many services and tasks if needed
i.e. there is no need to have n keypairs for n services that require
SSH PKA.
54 rh0-ve3:/srv/gitosis# exit
55 exit
56 sa@rh0-ve3:~$ exit
57 logout
58 Connection to devel.example.com closed.
59 sa@wks:~$ cd .ssh/keypairs/; type pi; pi Markus
60 pi is aliased to `ls -la | grep'
61 -rw------- 1 sa sa 6431 2009-03-13 11:11 ssh_pka_key_for_user_Markus_Ano
62 -rw-r--r-- 1 sa sa 1501 2009-03-13 11:11 ssh_pka_key_for_user_Markus_Ano.pub
64 sa@wks:~/.ssh/keypairs$ scp -P 58445 ssh_pka_key_for_user_Markus_Ano.pub devel.example.com:/tmp
65
66
67 [skipping a lot of lines...]
68
69
70 ssh_pka_key_for_user_Markus_Ano.pub 100% 1501 1.5KB/s 00:00
71 sa@wks:~/.ssh/keypairs$ ssh dolmen-devel
72
73
74 [skipping a lot of lines...]
75
76
77 sa@rh0-ve3:~$ cd /tmp/
78 sa@rh0-ve3:/tmp$ pi Markus
79 -rw-r--r-- 1 sa sa 1501 2009-07-12 13:48 ssh_pka_key_for_user_Markus_Ano.pub
80 sa@rh0-ve3:/tmp$ su
81 Password:
82 rh0-ve3:/tmp# dpl sudo* | grep ii
83 ii sudo 1.7.0-1 Provide limited super user privileges to specific users
So, as mentioned we need to either create or grab the public SSH key
on our local machine if it already exists there and then transfer it
onto the remote machine running GITosis.
With line 58 we have finally left rh0-ve3 and thus we are back on wks
again in line 59 where we check for my already existing SSH keypair.
As can be seen from line 62, there it is, my public key that we are
going to use for setting up the GITosis administrator account plus,
later on, we are also going to use it in order to provide myself with
write/commit/push permissions to GIT repositories hosted on our remote
machine rh0-ve3.
With line 64 we use SCP (Secure Copy) to copy the public key (the one
with the .pub suffix) from my local machine (wks) onto the remote
machine. In terms of security considerations, it is, as usual, very
important to keep the private key save i.e. to copying the private key
instead of the public key would be a very dangerous thing to do since,
having the private key physically on some remote machine is a huge
security risk. That is true even if the private key is
protected by a passphrase which of course it should be for security
reasons.
The -P switch in line 64 specifies a non-standard sshd listening port
and :/tmp determines the destination directory on the remote machine
i.e. rh0-ve3. devel.example.com is a standard URL (Uniform Resource
Locator) that resolves to an IPv4 address e.g. 123.23.43.118. We could
of course also specify the IP address directly but since we already
have the domain pointer onto the IP address, why not use it.
For both cases, domain name or IP address, the important thing is that
there is an sshd listening on that particular IP and port combination
else our SSH connection/transfer would not succeed. Last but not
least, the devel in devel.example.com denotes/hints that our GITosis
VE is actually used for more than just a fully fledged GIT hosting
platform — later we are going to lay a Trac layer on top the GIT
infrastructure and thus have a ticketing/wiki/project management
system using GIT as its SCM (Software Configuration Management)
backend. Anyway, Trac and GITosis actually have nothing to do with
each other from a technical point of view other than GITosis can
provide SCM backend functionality to Trac i.e. one can set up and use
GITosis without putting an additional Trac layer on top GITosis, there
is no dependency on Trac whatsoever.
The [skipping a lot of lines...] in line 67 and further down just
indicates the missing/skipped banner message — there is no point in
showing it over and over again. Line 70 shows that we successfully
transferred the public key ssh_pka_key_for_user_Markus_Ano.pub to /tmp
on the remote machine — line 79 is just about providing proof that it
is really true, we did not screw up here.
With installing the debian package gitosis, sudo got installed as a
dependency — we will need it now as can be seen below in line 84.
84 rh0-ve3:/tmp# sudo -H -u gitosis gitosis-init < /tmp/ssh_pka_key_for_user_Markus_Ano.pub
85 Initialized empty Git repository in /srv/gitosis/repositories/gitosis-admin.git/
86 Reinitialized existing Git repository in /srv/gitosis/repositories/gitosis-admin.git/
87 rh0-ve3:/tmp# cd /srv/gitosis/repositories/gitosis-admin.git/
88 rh0-ve3:/srv/gitosis/repositories/gitosis-admin.git# type la; la
89 la is aliased to `ls -la'
90 total 52
91 drwxr-x--- 8 gitosis gitosis 4096 2009-07-12 13:52 .
92 drwxr-xr-x 3 gitosis gitosis 4096 2009-07-12 13:52 ..
93 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-12 13:52 branches
94 -rw-r--r-- 1 gitosis gitosis 66 2009-07-12 13:52 config
95 -rw-r--r-- 1 gitosis gitosis 73 2009-07-12 13:52 description
96 -rw-r--r-- 1 gitosis gitosis 90 2009-07-12 13:52 gitosis.conf
97 drwxr-xr-x 3 gitosis gitosis 4096 2009-07-12 13:52 gitosis-export
98 -rw-r--r-- 1 gitosis gitosis 23 2009-07-12 13:52 HEAD
99 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-12 13:52 hooks
100 -rw-r--r-- 1 gitosis gitosis 272 2009-07-12 13:52 index
101 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-12 13:52 info
102 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-12 13:52 objects
103 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-12 13:52 refs
104 rh0-ve3:/srv/gitosis/repositories/gitosis-admin.git# la hooks/post-update
105 lrwxrwxrwx 1 gitosis gitosis 61 2009-07-12 13:52 hooks/post-update -> /usr/share/pyshared/gitosis/templates/admin/hooks/post-update
106 rh0-ve3:/srv/gitosis/repositories/gitosis-admin.git# la /usr/share/pyshared/gitosis/templates/admin/hooks/post-update
107 -rwxr-xr-x 1 root root 69 2009-04-25 14:38 /usr/share/pyshared/gitosis/templates/admin/hooks/post-update
108 rh0-ve3:/srv/gitosis/repositories/gitosis-admin.git# cd ..
109 rh0-ve3:/srv/gitosis/repositories# !!
110 cd ..
We are back on rh0-ve3, became root, and then issue line 84. What this
command sequence does is, sudo is used to run it as system user
gitosis even though we are currently logged in as root.
gitosis-init itself takes our public SSH key and does its magic with
it — in essence, it sprinkles some magic into the home directory of
the gitosis user and puts our public SSH key into the list of
authorized keys. The reason why we use /tmp on the remote machine is
because, for once the key is not needed anymore after issuing line 84
(it will vanish on reboot) plus, by using /tmp we are unlikely going
to run into permission problems like for example the user gitosis is
unable to read the public key.
That we succeed with line 84 can be seen from lines 85 and 86. After
taking a look around in lines 93 to 103, inside our just created
GITosis administrator area, (yes, that is a standard GIT
repository layout — we are using GIT to manage our GIT hosting
platform... how cool is that?! ;-]) we check if our post update hook
has the correct permission i.e. can be executed by others than root
itself or members of group root — it is all good, the permissions are
all right as they are 755 in octal notation and thus allow others, and
therefore the gitosis system user, to execute the hook.
111 rh0-ve3:/srv/gitosis# la
112 total 20
113 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 .
114 drwxr-xr-x 3 root root 4096 2009-07-09 11:33 ..
115 lrwxrwxrwx 1 root root 25 2009-07-09 11:33 git -> /srv/gitosis/repositories
116 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-12 13:52 gitosis
117 lrwxrwxrwx 1 gitosis gitosis 56 2009-07-12 13:52 .gitosis.conf -> /srv/gitosis/repositories/gitosis-admin.git/gitosis.conf
118 drwxr-xr-x 3 gitosis gitosis 4096 2009-07-12 13:52 repositories
119 drwx------ 2 gitosis gitosis 4096 2009-07-12 13:52 .ssh
120 rh0-ve3:/srv/gitosis# la repositories/
121 total 12
122 drwxr-xr-x 3 gitosis gitosis 4096 2009-07-12 13:52 .
123 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
124 drwxr-x--- 8 gitosis gitosis 4096 2009-07-12 13:52 gitosis-admin.git
125 rh0-ve3:/srv/gitosis# cat .gitosis.conf
126 [gitosis]
127
128 [group gitosis-admin]
129 writable = gitosis-admin
130 members = markusgattol
131
132 rh0-ve3:/srv/gitosis# la .ssh/
133 total 12
134 drwx------ 2 gitosis gitosis 4096 2009-07-12 13:52 .
135 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
136 -rw-r--r-- 1 gitosis gitosis 1652 2009-07-12 13:52 authorized_keys
137 rh0-ve3:/srv/gitosis# cat .ssh/authorized_keys
138 ### autogenerated by gitosis, DO NOT EDIT
139 command="gitosis-serve markusgattol",no-port-forwarding,no-X11-forwarding,no-agent-forwarding,no-pty ssh-rsa AAAAB3NzaC [skipping a lot of characters...] TuB4zOt+Ay9dfoq5nMIekW2TNts24F/9k2NQ== PKA (Public Key Authentication) SSH keypair for user Markus Gattol; reach me at markusgattol
If we compare lines 51 to 53 with lines 113 to 119, we can see that
the command from line 84 also created a symmetric link to our
.gitosis.conf file, it created .ssh, the place where the public keys
are kept on the remote machine, and then there is ../repositories, the
place where all GIT repositories will live from now on, including the
one used to administer GITosis itself as can be seen in line 124.
The most important file it includes can be seen in lines 126 to 131 —
in line 129 it says, that the repository git-admin.git is writable and
with line 130 it also says that only markusgattol (that is me) can write to
it i.e. only I can use git push and put new configuration settings for
the GITosis platform running on rh0-ve3 into place. This is true
because of my public SSH key as it can be seen in line 139.
Security is good, as mentioned above already, even I cannot issue
arbitrary commands because of the
command=<command_issued_when_public_key_authentication_is_ok>
part.
140 rh0-ve3:/srv/gitosis# grep AllowUsers /etc/ssh/sshd_config
141 AllowUsers [email protected].* [email protected].* [email protected]
142 rh0-ve3:/srv/gitosis# nano /etc/ssh/sshd_config
143
144
145 [ here we use nano to edit /etc/ssh/sshd_config... ]
146
147
148 rh0-ve3:/srv/gitosis# grep AllowUsers /etc/ssh/sshd_config
149 AllowUsers [email protected].* [email protected].* [email protected] gitosis@*
150 rh0-ve3:/srv/gitosis# /etc/init.d/ssh reload
151 Reloading OpenBSD Secure Shell server's configuration: sshd.
152 rh0-ve3:/srv/gitosis# exit
153 exit
154 sa@rh0-ve3:~$ exit
155 logout
156 Connection to devel.example.com closed.
Since AllowUsers is used for the SSH setup, we have to explicitly
grant our system user gitosis access to rh0-ve3. The before (line 141)
and The after (line 149) can be seen above. Line 150 shows how to
activate the new sshd setting without rebooting the entire VE (Virtual
Environment) or even restarting the sshd — doing so, restarting that
is, would kill our currently active SSH connection to rh0-ve3 as well
...
157 sa@wks:~$ cd 0/
158 sa@wks:~/0$ mkdir -p gitosis_projects/dolmen
159 sa@wks:~/0$ cd gitosis_projects/dolmen/
160 sa@wks:~/0/gitosis_projects/dolmen$ la
161 total 8
162 drwxr-xr-x 2 sa sa 4096 2009-07-12 18:36 .
163 drwxr-xr-x 3 sa sa 4096 2009-07-12 18:36 ..
164 sa@wks:~/0/gitosis_projects/dolmen$ nano /home/sa/.ssh/config
165
166
167 [ here we use nano to edit ~/.ssh/config... ]
168
169
170 sa@wks:~/0/gitosis_projects/dolmen$ grep -C4 gitosis ~/.ssh/config
171 ###_ , devel.example.com
172 # description: just a dummy stanza to make git push/pull work with
173 # devel.example.com
174 Host devel.example.com
175 User gitosis
176 Port 58445
177 Hostname devel.example.com
178 IdentityFile %d/.ssh/keypairs/ssh_pka_key_for_user_Markus_Ano
179 TCPKeepAlive yes
Back on the local machine, I decided to have a dedicated directory to
host all my GITosis administrator related data for several projects
that I am going to migrate to GIT, the first of which is Dolmen.
As I mentioned above already, we are using a non-standard listening
port for the sshd running on rh0-ve3. Because of that, we need to put
a new stanza into ~/.ssh/config that will provide information to the
local SSH client running on wks — that is, for example, the sshd
listening port on rh0-ve3 and which keyfile to use. The important
lines here are those from line 174 to line 178. Line 179 is a
nice-to-have, especially if we want to avoid indefinitely hanging SSH
sessions and the like.
Line 174 is what we specify on the CLI (Command Line Interface) i.e.
ssh devel.example.com. This is how our local SSH client finds this
particular stanza so he knows which URL/IP to use (line 177), which
port to use (line 176) and that he should disguise as user gitosis
when asking for access on the remote machine i.e. the sshd listening
on port 58445 at devel.example.com.
Line 178 is useful if we have several SSH keys loaded into our
SSH-agent (on our local machine, wks in the current case) and, in
addition, MaxAuthTries is set to a low number on the remote system —
in short, line 178 enables our local SSH client to pick the right
private/public keypair combination right away without the need to
iterate a few times until it finds the correct counterpart to the
public key on the remote machine. If MaxAuthTries 1 is set on the
remote machine, we only have one attempt after which the remote
machine's sshd cancels the connection. Therefore, using IdentityFile
is, if not mandatory anyway, good practice.
Note, I do have another stanza of course as well
Host dolmen-devel
User sa
HostName devel.example.com
Port 58445
IdentityFile %d/.ssh/keypairs/ssh_pka_key_for_user_Markus_Ano
TCPKeepAlive yes
which I use for regular SSH access to rh0-ve3. The point is, it is the
same SSH keypair, once I disguise myself as user gitosis and therefore
I am limited by the command= option, and once I am what I
am, sa, and can therefore administer this VE as usual after becoming
root from sa or using sudo for example.
Again... we have two different stanzas in ~/.ssh/config, same VE,
same sshd, but different users and thus permissions because of the two
stanzas:
- The stanza which can be seen in lines 171 to 179 is used when I
manage/configure GITosis (e.g. create new repositories, grant
write/commit/push permissions to users, etc.) and when I am
actively working i.e. coding where I need to have
write/commit/push access to some repository like for example
Dolmen as an active programmer/contributor.
- The second stanza is used when I administer the remote machine
rh0-ve3 (we use a OpenVZ VE (Virtual Environment) but that does
not matter — a non-virtualized box would feel/behave no
different) as usual e.g. login via SSH, become root, issue
aptitude update && aptitude full-upgrade for example
180 sa@wks:~/0/gitosis_projects/dolmen$ git clone [email protected]:gitosis-admin.git
181 Initialized empty Git repository in /home/sa/0/gitosis_projects/dolmen/gitosis-admin/.git/
182
183 / \ _-'
184 _/ \-''- _ /
185 __-' { \
186 / \
187 / "o. |o }
188 | \ ; YOU ARE BEING WATCHED!
189 ',
190 \_ __\
191 ''-_ \.//
192 / '-____'
193 /
194 _'
195 _-'
196
197
198 This computer system is the private property of its owner, whether individual, corporate or government. It is
199 for authorized use only. Users (authorized or unauthorized) have no explicit or implicit expectation of
200 privacy.
201
202 Any or all uses of this system and all files on this system may be intercepted, monitored, recorded, copied,
203 audited, inspected, and disclosed to your employer, to authorized site, government, and law enforcement
204 personnel, as well as authorized officials of government agencies, both domestic and foreign.
205
206 By using this system, the user consents to such interception, monitoring, recording, copying, auditing,
207 inspection, and disclosure at the discretion of such personnel or officials.
208
209
210 UNAUTHORIZED OR IMPROPER USE OF THIS SYSTEM MAY RESULT
211 IN CIVIL AND CRIMINAL PENALTIES AND ADMINISTRATIVE OR
212 DISCIPLINARY ACTION, AS APPROPRIATE !!
213
214
215 By continuing to use this system you indicate your awareness of and consent to these terms and conditions of
216 use. LOG OFF IMMEDIATELY if you do not agree to the conditions stated in this warning. However, if you are
217 authorized personal with no bad intentions please continue. Have a nice day! :-)
218
219 remote: Counting objects: 5, done.
220 remote: Compressing objects: 100% (5/5), done.
221 remote: Total 5 (delta 0), reused 5 (delta 0)
222 Receiving objects: 100% (5/5), done.
223 sa@wks:~/0/gitosis_projects/dolmen$ la
224 total 12
225 drwxr-xr-x 3 sa sa 4096 2009-07-12 18:45 .
226 drwxr-xr-x 3 sa sa 4096 2009-07-12 18:36 ..
227 drwxr-xr-x 4 sa sa 4096 2009-07-12 18:45 gitosis-admin
228 sa@wks:~/0/gitosis_projects/dolmen$ cd gitosis-admin/
229 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ la
230 total 20
231 drwxr-xr-x 4 sa sa 4096 2009-07-12 18:45 .
232 drwxr-xr-x 3 sa sa 4096 2009-07-12 18:45 ..
233 drwxr-xr-x 8 sa sa 4096 2009-07-12 18:45 .git
234 -rw-r--r-- 1 sa sa 90 2009-07-12 18:45 gitosis.conf
235 drwxr-xr-x 2 sa sa 4096 2009-07-12 18:45 keydir
236 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ la keydir/
237 total 12
238 drwxr-xr-x 2 sa sa 4096 2009-07-12 18:45 .
239 drwxr-xr-x 4 sa sa 4096 2009-07-12 18:45 ..
240 -rw-r--r-- 1 sa sa 1501 2009-07-12 18:45 markusgattol.pub
241 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ cat keydir/markusgattol.pub
242 ssh-rsa AAAAB3NzaC1yc [skipping a lot of characters...] q5nMIekW2TNts24F/9k2NQ== PKA (Public Key Authentication) SSH keypair for user Markus Gattol; reach me at markusgattol
243 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ cat gitosis.conf
244 [gitosis]
245
246 [group gitosis-admin]
247 writable = gitosis-admin
248 members = markusgattol
249
With line 180 we transfer those bits and pieces needed for
administering GITosis onto my local machine (wks) — note that
devel.example.com in line 180 triggers all the stuff we put in place
with lines 174 to 179 e.g. we use port 58445 without explicitly
specifying it in line 180.
What follows is the usual banner message and some GIT specific chatter
in lines 219 to 222. From now on, everybody will see this
banner message when cloning/pulling/fetching from one of our GIT
repositories via SSH — of course, one might alter the banner message
to whatever he might think fits better e.g. some message telling those
who clone that this is GITosis they are talking to, company info, some
URL to some website, etc.
The result of line 180 can be seen from lines 227 onwards like for
example ../gitosis-admin/keydir which is used the collect and store
the public SSH keys from anybody who has write/commit/push permissions
to one of our GIT repositories.
As we can see, gitosis.conf is now also present on our local machine
i.e. with GITosis we do not even need to enter rh0-ve3 via SSH and
edit gitosis.conf on the remote machine (lines 126 to 131) but we can
do all management tasks locally and when done, use git push in order
to push them to rh0-ve3 and thereby make the settings active on the
remote machine i.e. our GITosis hosting platform running on rh0-ve3.
That part is pure GIT power — a decentralized SCM system does not
need to be connected to some central instance all in order for us to
get some work done.
We could for example configure a new repository while sitting on some
airplane without connectivity to the Internet and then, once we have
Internet connectivity again, just issue git push and the new
repositories with all its permissions and users will be available
immediately.... that is just plain cool! GIT is just plain cool I
should say. Try this with some centralized SCM like for example SVN
;-]
Adding Users
250 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$
251
252
253 [ here we use nano to edit /home/sa/0/gitosis_projects/dolmen/gitosis-admin/gitosis.conf... ]
254
255
256 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ cat gitosis.conf
257 [gitosis]
258
259 [group gitosis-admin]
260 writable = gitosis-admin
261 members = markusgattol
262
263 [group dolmen]
264 members = markusgattol
265 writable = dolmen
266 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ git dwh
267 diff --git a/gitosis.conf b/gitosis.conf
268 index b8000ed..621dc63 100644
269 --- a/gitosis.conf
270 +++ b/gitosis.conf
271 @@ -4,3 +4,6 @@
272 writable = gitosis-admin
273 members = markusgattol
274
275 +[group dolmen]
276 +members = markusgattol
277 +writable = dolmen
278 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ git cwh -m 'allow Markus Gattol write access to dolmen'
279 [master d939ac7] allow Markus Gattol write access to dolmen
280 1 files changed, 3 insertions(+), 0 deletions(-)
Next we edit our local gitosis.conf in order to provide
write/commit/push permissions to our first user. The entry we make in
line 264 has to be the same name as the name of the public keyfile
(line 240) of this user but without the .pub extension. This is how
permitting write/commit/push for a new user works — collecting their
public key files in ../keydir and adding the name of their keyfile to
the members line in gitosis.conf, that is all, very simple and
straight forward — can be done on any airplane if need be, I know ;-]
With our current setup, we will now also specify the name of a new
project called Dolmen i.e. we will have dolmen.git, a
bare GIT repository, on the remote machine once we are done.
Therefore we create a new group in line 263 — it makes sense to name
the group dolmen as well, same name as the project name in line 265.
However, the group name does not need to be the same as the
repository/project name.
Naming generally works like this: The repository name on the remote
machine rh0-ve3 (dolmen.git) has the suffix .git. The project name
(line 265) comes without the suffix, and the directory on the
filesystem which we create with line 297 and which contains the data
like for example source code for Dolmen, also has the name dolmen.
Starting with line 266 we make use of some of my
aliases in ~/.gitconfig like for example git dwh which is short for
git diff HEAD.
With line 278 we commit the changes to our local clone of
gitosis-admin and with line 281 we push them to rh0-ve3 i.e. our
GITosis hosting platform.
281 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ git push
282
283
284 [skipping a lot of lines...]
285
286
287 Counting objects: 5, done.
288 Delta compression using up to 4 threads.
289 Compressing objects: 100% (3/3), done.
290 Writing objects: 100% (3/3), 393 bytes, done.
291 Total 3 (delta 0), reused 0 (delta 0)
292 To [email protected]:gitosis-admin.git
293 3c86640..d939ac7 master -> master
294 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ gllol
295 d939ac7fa4f9a29e517541f494e00285d18a4b63 10 seconds ago CN: Markus Gattol AN: Markus Gattol S: allow Markus Gattol write access to dolmen
296 3c866407f4fabd7c7afbcf434b76024b1476e58d 24 hours ago CN: Gitosis Admin AN: Gitosis Admin S: Automatic creation of gitosis repository.
That the push was successful can be seen from lines 287 to 293.
Internally, for this push, GITosis checked whether we are in
possession of the private key ssh_pka_key_for_user_Markus_Ano. Also, as
before, the SSH settings in ~/.ssh/config were responsible that GIT
knew were to put its stuff.
gllol in line 294 is a somewhat fancy command which I have come to
like a lot since it shows me what I need to know quite easily and with
not much effort.
Adding Repositories
297 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin$ mkdir dolmen; cd dolmen
298 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git init
299 Initialized empty Git repository in /home/sa/0/gitosis_projects/dolmen/gitosis-admin/dolmen/.git/
300 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git remote add origin [email protected]:dolmen.git
301 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ echo "WRITEME" > README
302 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ la
303 total 16
304 drwxr-xr-x 3 sa sa 4096 2009-07-13 16:11 .
305 drwxr-xr-x 5 sa sa 4096 2009-07-13 16:09 ..
306 drwxr-xr-x 7 sa sa 4096 2009-07-13 16:10 .git
307 -rw-r--r-- 1 sa sa 8 2009-07-13 16:11 README
308 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git add README
309 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git status
310 # On branch master
311 #
312 # Initial commit
313 #
314 # Changes to be committed:
315 # (use "git rm --cached <file>..." to unstage)
316 #
317 # new file: README
318 #
319 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git cwh -m 'initial commit'
320 [master (root-commit) ac84821] initial commit
321 1 files changed, 1 insertions(+), 0 deletions(-)
322 create mode 100644 README
323 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ gllol
324 ac8482172485bc3322ab7e22a189dd320bf666f9 2 seconds ago CN: Markus Gattol AN: Markus Gattol S: initial commit
325 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ cat .git/config
326 [core]
327 repositoryformatversion = 0
328 filemode = true
329 bare = false
330 logallrefupdates = true
331 [remote "origin"]
332 url = [email protected]:dolmen.git
333 fetch = +refs/heads/*:refs/remotes/origin/*
We have already specified a new group above in line 263 and specified
that our new repository will allow write/commit/push actions. That is
very cool but then, it would be even cooler if we actually had that
repository too no? ;-]
With line 297/298 we create it on our local machine, add the remote
information in line 300 and add some file in line 301. Line 300, where
we set the origin, is yet another line which implicitly uses our SSH
settings in ~/.ssh/config.
After looking at the current status with line 309, we commit the
changes with line 319 which works fine as can be seen. Again, git cwh
-m is an aliases in ~/.gitconfig and is just the short version of git
commit -a -s -m.
Now is a good time to take a look at the config file of our just
created repository. As we can see in line 332, we have successfully
added/created a bare repository on rh0-ve3 respectively
devel.example.com i.e. onto our own GITosis hosting platform.
334 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ git push origin master:refs/heads/master
335
336
337 [skipping a lot of lines...]
338
339
340 Initialized empty Git repository in /srv/gitosis/repositories/dolmen.git/
341 Counting objects: 3, done.
342 Writing objects: 100% (3/3), 233 bytes, done.
343 Total 3 (delta 0), reused 0 (delta 0)
344 To [email protected]:dolmen.git
345 * [new branch] master -> master
Last but not least, after making our local clone think it got cloned
from devel.example.com:dolmen.git with line 300, we push again with a
somewhat special command, a refspec, in line 334 and thus make the
whole thing complete which means, now we have two master branches on
both sides, locally and remotely which are now in sync and therefore
the repository is ready to be used... of to the races ladies and
gentlemen, start your engines ;-]
346 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ ssh dolmen-devel
347
348
349 [skipping a lot of lines...]
350
351
352 sa@rh0-ve3:~$ su
353 Password:
354 rh0-ve3:/home/sa# cd /srv/gitosis/repositories/
355 rh0-ve3:/srv/gitosis/repositories# la
356 total 16
357 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 .
358 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
359 drwxr-x--- 7 gitosis gitosis 4096 2009-07-13 14:13 dolmen.git
360 drwxr-x--- 8 gitosis gitosis 4096 2009-07-13 13:41 gitosis-admin.git
361 rh0-ve3:/srv/gitosis/repositories# cd dolmen.git/
362 rh0-ve3:/srv/gitosis/repositories/dolmen.git# la
363 total 40
364 drwxr-x--- 7 gitosis gitosis 4096 2009-07-13 14:13 .
365 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 ..
366 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 branches
367 -rw-r--r-- 1 gitosis gitosis 66 2009-07-13 14:13 config
368 -rw-r--r-- 1 gitosis gitosis 73 2009-07-13 14:13 description
369 -rw-r--r-- 1 gitosis gitosis 23 2009-07-13 14:13 HEAD
370 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 hooks
371 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 info
372 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-13 14:13 objects
373 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 refs
374 rh0-ve3:/srv/gitosis/repositories/dolmen.git# cat config
375 [core]
376 repositoryformatversion = 0
377 filemode = true
378 bare = true
379 rh0-ve3:/srv/gitosis/repositories/dolmen.git# la info/
380 total 12
381 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 .
382 drwxr-x--- 7 gitosis gitosis 4096 2009-07-13 14:13 ..
383 -rw-r--r-- 1 gitosis gitosis 240 2009-07-13 14:13 exclude
384 rh0-ve3:/srv/gitosis/repositories/dolmen.git# la refs/
385 total 16
386 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 .
387 drwxr-x--- 7 gitosis gitosis 4096 2009-07-13 14:13 ..
388 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 heads
389 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 tags
390 rh0-ve3:/srv/gitosis/repositories/dolmen.git# la refs/heads/
391 total 12
392 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 .
393 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 ..
394 -rw-r--r-- 1 gitosis gitosis 41 2009-07-13 14:13 master
395 rh0-ve3:/srv/gitosis/repositories/dolmen.git# cat refs/heads/master
396 ac848ac8482172485bc3322ab7e22a189dd320bf666f9
397 rh0-ve3:/srv/gitosis/repositories/dolmen.git# exit
398 exit
399 sa@rh0-ve3:~$ exit
400 logout
401 Connection to devel.example.com closed.
402 sa@wks:~/0/gitosis_projects/dolmen/gitosis-admin/dolmen$ cd /tmp/test/
Lines 346 to 397 are just to take another look around on rh0-ve3 after
we pushed all the local configurations we did upstream i.e. from the
local machine (wks) to the remote machine (rh0-ve3).
Note that this time, in line 346, we use dolmen-devel to refer to my
usual stanza in ~/.ssh/config i.e. the one where we use my standard
user sa rather than our system user gitosis.
The thing that is most interesting here is with line 396 — the
object type we are looking at here is a so-called commit object, the
one (ac84821...) we created with line 319 on our local machine and
which is now available, after the push in line 334, on rh0-ve3 as
well.
Providing a Repository to the World
There are two ways this can be done
- cloning via GITosis, and thus via SSH, for users with
write/commit/push permissions or
- cloning (optionally via SSH) for everybody i.e. for those without
write/commit/push permissions. This option is good to have for any
project because it allows, for example, that all those folks who
help with testing can update their local repository/clone
regularly... once cloned,
git pull is all that is needed to
update a local clone to the current status of the upstream
repository. If at some point, they would like to become
contributors, the GITosis administrator can collect their public
SSH key and add them to the members line in gitosis.conf.
403 sa@wks:/tmp/test$ git clone [email protected]:dolmen.git
404 Initialized empty Git repository in /tmp/test/dolmen/.git/
405
406 / \ _-'
407 _/ \-''- _ /
408 __-' { \
409 / \
410 / "o. |o }
411 | \ ; YOU ARE BEING WATCHED!
412 ',
413 \_ __\
414 ''-_ \.//
415 / '-____'
416 /
417 _'
418 _-'
419
420
421 This computer system is the private property of its owner, whether individual, corporate or government. It is
422 for authorized use only. Users (authorized or unauthorized) have no explicit or implicit expectation of
423 privacy.
424
425 Any or all uses of this system and all files on this system may be intercepted, monitored, recorded, copied,
426 audited, inspected, and disclosed to your employer, to authorized site, government, and law enforcement
427 personnel, as well as authorized officials of government agencies, both domestic and foreign.
428
429 By using this system, the user consents to such interception, monitoring, recording, copying, auditing,
430 inspection, and disclosure at the discretion of such personnel or officials.
431
432
433 UNAUTHORIZED OR IMPROPER USE OF THIS SYSTEM MAY RESULT
434 IN CIVIL AND CRIMINAL PENALTIES AND ADMINISTRATIVE OR
435 DISCIPLINARY ACTION, AS APPROPRIATE !!
436
437
438 By continuing to use this system you indicate your awareness of and consent to these terms and conditions of
439 use. LOG OFF IMMEDIATELY if you do not agree to the conditions stated in this warning. However, if you are
440 authorized personal with no bad intentions please continue. Have a nice day! :-)
441
442 remote: Counting objects: 3, done.
443 remote: Total 3 (delta 0), reused 0 (delta 0)
444 Receiving objects: 100% (3/3), done.
445 sa@wks:/tmp/test$ la
446 total 12
447 drwxr-xr-x 3 sa sa 4096 2009-07-13 17:19 .
448 drwxrwxrwt 26 root root 4096 2009-07-13 17:19 ..
449 drwxr-xr-x 3 sa sa 4096 2009-07-13 17:19 dolmen
450 sa@wks:/tmp/test$ cat dolmen/README
451 WRITEME
452 sa@wks:/tmp/test$
We issue line 403 and what happens is just plain lovely! Cloning as a
user who has write/commit/push permissions worked just fine as line
444 shows — on my local machine, wks, I have provided SSH-agent with
my private key before so...
We now have a clone of Dolmen in /tmp which also contains README, the
file we created in line 301 on our local machine, then pushed to the
remote machine rh0-ve3 and now, again, cloned i.e. transferred it from
the remote machine onto our local machine wks.
Ok, great, cloning works but what about doing some changes locally and
then pushing them back again onto GITosis hosting platform that, among
other GIT repositories, houses dolmen.git? Or in other words, what
would the girl/boy see if she/he were a contributor with
write/commit/push permissions do Dolmen? Let us find out...
453 sa@wks:/tmp/test$ cd dolmen/
454 sa@wks:/tmp/test/dolmen$ la
455 total 16
456 drwxr-xr-x 3 sa sa 4096 2009-07-13 17:19 .
457 drwxr-xr-x 3 sa sa 4096 2009-07-13 17:19 ..
458 drwxr-xr-x 8 sa sa 4096 2009-07-13 17:19 .git
459 -rw-r--r-- 1 sa sa 8 2009-07-13 17:19 README
460 sa@wks:/tmp/test/dolmen$ git st
461 # On branch master
462 nothing to commit (working directory clean)
463 sa@wks:/tmp/test/dolmen$ echo "PLEASE WRITEME" > README
464 sa@wks:/tmp/test/dolmen$ cat README
465 PLEASE WRITEME
466 sa@wks:/tmp/test/dolmen$ git st
467 # On branch master
468 # Changed but not updated:
469 # (use "git add <file>..." to update what will be committed)
470 # (use "git checkout -- <file>..." to discard changes in working directory)
471 #
472 # modified: README
473 #
474 no changes added to commit (use "git add" and/or "git commit -a")
475 sa@wks:/tmp/test/dolmen$ git cwh -m 'did some changes to README'
476 [master a137d2d] did some changes to README
477 1 files changed, 1 insertions(+), 1 deletions(-)
478 sa@wks:/tmp/test/dolmen$ git push
479
480 / \ _-'
481 _/ \-''- _ /
482 __-' { \
483 / \
484 / "o. |o }
485 | \ ; YOU ARE BEING WATCHED!
486 ',
487 \_ __\
488 ''-_ \.//
489 / '-____'
490 /
491 _'
492 _-'
493
494
495 This computer system is the private property of its owner, whether individual, corporate or government. It is
496 for authorized use only. Users (authorized or unauthorized) have no explicit or implicit expectation of
497 privacy.
498
499 Any or all uses of this system and all files on this system may be intercepted, monitored, recorded, copied,
500 audited, inspected, and disclosed to your employer, to authorized site, government, and law enforcement
501 personnel, as well as authorized officials of government agencies, both domestic and foreign.
502
503 By using this system, the user consents to such interception, monitoring, recording, copying, auditing,
504 inspection, and disclosure at the discretion of such personnel or officials.
505
506
507 UNAUTHORIZED OR IMPROPER USE OF THIS SYSTEM MAY RESULT
508 IN CIVIL AND CRIMINAL PENALTIES AND ADMINISTRATIVE OR
509 DISCIPLINARY ACTION, AS APPROPRIATE !!
510
511
512 By continuing to use this system you indicate your awareness of and consent to these terms and conditions of
513 use. LOG OFF IMMEDIATELY if you do not agree to the conditions stated in this warning. However, if you are
514 authorized personal with no bad intentions please continue. Have a nice day! :-)
515
516 Counting objects: 5, done.
517 Writing objects: 100% (3/3), 286 bytes, done.
518 Total 3 (delta 0), reused 0 (delta 0)
519 To [email protected]:dolmen.git
520 ac84821..a137d2d master -> master
521 sa@wks:/tmp/test/dolmen$ gllol
522 a137d2d85c68dd44a6b755ea8c020d6b1116c283 10 seconds ago CN: Markus Gattol AN: Markus Gattol S: did some changes to README
523 ac8482172485bc3322ab7e22a189dd320bf666f9 2 days ago CN: Markus Gattol AN: Markus Gattol S: initial commit
We do an edit in line 463, check the status with line 466 and commit
the change/edit from line 463 with line 475. Now, will the push
towards upstream work? It sure does as we can see from line 478 onward
... piece of cake! ;-]
The closer look in line 521 and following provides us with more
details —
we just went full circle... we cloned the upstream
repository, made local edits/changes which we committed and finally
pushed them back into the upstream repository onto our GITosis hosting
platform. Excellent!
Next we are going to set up GIT-daemon for anonymous read/pull/fetch
access, the second one of two possible choices.
524 sa@wks:/tmp/test/dolmen$ ssh dolmen-devel
525
526
527 [skipping a lot of lines...]
528
529
530 sa@rh0-ve3:~$ su
531 Password:
532 rh0-ve3:/home/sa# aptitude install git-daemon-run
533 Reading package lists... Done
534 Building dependency tree
535 Reading state information... Done
536
537
538 [skipping a lot of lines...]
539
540
541 Reading extended state information
542 Initializing package states... Done
543 Writing extended state information... Done
544
At first we need to enter rh0-ve3 again and install GIT-daemon — the
debian package for GIT-daemon is called git-daemon-run.
545 rh0-ve3:/home/sa# cd /usr/share/doc/git-daemon-run/
546 rh0-ve3:/usr/share/doc/git-daemon-run# la
547 total 300
548 drwxr-xr-x 2 root root 4096 2009-07-15 06:37 .
549 drwxr-xr-x 273 root root 12288 2009-07-15 06:37 ..
550 -rw-r--r-- 1 root root 15971 2009-06-26 08:18 changelog.Debian.gz
551 -rw-r--r-- 1 root root 259657 2009-06-26 08:18 changelog.gz
552 -rw-r--r-- 1 root root 3412 2009-06-26 08:18 copyright
553 -rw-r--r-- 1 root root 1143 2009-06-26 08:18 README.Debian
554 rh0-ve3:/usr/share/doc/git-daemon-run# cat /var/log/git-daemon/current
555 2009-07-15_06:37:39.93133 git-daemon starting.
556 rh0-ve3:/usr/share/doc/git-daemon-run# sv stat git-daemon
557 run: git-daemon: (pid 6156) 3275s; run: log: (pid 6155) 3275s
558 rh0-ve3:/usr/share/doc/git-daemon-run# ls -la /etc/init.d/ | grep git
559 rh0-ve3:/usr/share/doc/git-daemon-run# ln -s /usr/bin/sv /etc/init.d/git-daemon
560 rh0-ve3:/usr/share/doc/git-daemon-run# ls -la /etc/init.d/ | grep git
561 lrwxrwxrwx 1 root root 11 2009-07-15 07:33 git-daemon -> /usr/bin/sv
562 rh0-ve3:/usr/share/doc/git-daemon-run# cd /srv/gitosis/repositories/
563 rh0-ve3:/srv/gitosis/repositories# la
564 total 16
565 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 .
566 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
567 drwxr-x--- 7 gitosis gitosis 4096 2009-07-15 11:36 dolmen.git
568 drwxr-x--- 8 gitosis gitosis 4096 2009-07-15 11:33 gitosis-admin.git
569 rh0-ve3:/srv/gitosis/repositories# sudo -u gitosis touch dolmen.git/git-daemon-export-ok
570 rh0-ve3:/srv/gitosis/repositories# la dolmen.git/
571 total 40
572 drwxr-x--- 7 gitosis gitosis 4096 2009-07-15 11:36 .
573 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 ..
574 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 branches
575 -rw-r--r-- 1 gitosis gitosis 66 2009-07-13 14:13 config
576 -rw-r--r-- 1 gitosis gitosis 73 2009-07-13 14:13 description
577 -rw-r--r-- 1 gitosis gitosis 0 2009-07-15 11:36 git-daemon-export-ok
578 -rw-r--r-- 1 gitosis gitosis 23 2009-07-13 14:13 HEAD
579 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 hooks
580 drwxr-xr-x 2 gitosis gitosis 4096 2009-07-13 14:13 info
581 drwxr-xr-x 10 gitosis gitosis 4096 2009-07-15 05:15 objects
582 drwxr-xr-x 4 gitosis gitosis 4096 2009-07-13 14:13 refs
As usual, /usr/share/doc/git-daemon-run provides useful stuff (lines
550 to 553). From line 557 we can see that GIT-daemon is currently up
and running — installing git-daemon-run also started the daemon.
One important thing to note here is that GIT-daemon on Debian makes
use of runit — a UNIX init scheme with service supervision; it is a
replacement for SysV-init and other init schemes.
In order to make it work as usual i.e. in order to do
/etc/init.d/git-daemon restart for example, a symmetric link is
created in line 559.
We are going to setup GIT-daemon in a way, that by default, it does
not grant read/pull/fetch access to a newly created GIT repository —
that is recommended since it does avoid situations where a repository
is available to the entire world when it should not be.
If the default is to not allow read/pull/fetch access, we need to
explicitly allow read/pull/fetch access for each repository. Line 569
shows how this is done — GIT-daemon looks for a file called
git-daemon-export-ok within each repository and only if it is present,
is it made available to the public.
Note, that with using GITosis next to GIT-daemon, there is an even
smarter way to do this i.e. as it is shown in line 569, we have to log
into the remote machine rh0-ve3 and create git-daemon-export-ok
manually. When using GITosis in its default setup then the manually
crated git-daemon-export-ok will vanish with any git push from the
GITosis administrator's local machine. However, if we alter
.gitosis.conf on wks to read
[gitosis]
[group gitosis-admin]
writable = gitosis-admin
members = markusgattol
[group dolmen]
writable = dolmen
members = markusgattol user2 user3 user4
[repo dolmen]
daemon = yes
i.e. if we add a [repo dolmen] stanza which contains daemon =
yes and then git push this configuration to the remote machine
rh0-ve3, a manually created git-daemon-export-ok will not vanish and
even better, we do not even need to create it manually as we did above
with line 569 but GITosis will create git-daemon-export-ok for us
automatically without the need for the GITosis administrator to log
into rh0-ve3 via SSH and do it manually.
Again, this is good since we could do it on an airplane for example
where we do not currently have access to the Internet and then later
if we have Internet again, issue git push and thus transfer all the
new settings to rh0-ve3 and activate them in the process.
583 rh0-ve3:/srv/gitosis/repositories# cat /etc/sv/git-daemon/run
584 #!/bin/sh
585 exec 2>&1
586 echo 'git-daemon starting.'
587 exec chpst -ugitdaemon \
588 /usr/lib/git-core/git-daemon --verbose --base-path=/var/cache /var/cache/git
589 rh0-ve3:/srv/gitosis/repositories#
590
591
592 [ here we use nano to edit /etc/sv/git-daemon/run... ]
593
594
595 rh0-ve3:/srv/gitosis/repositories# cat /etc/sv/git-daemon/run
596 #!/bin/sh
597 exec 2>&1
598 echo 'git-daemon starting.'
599 exec chpst -ugitosis /usr/lib/git-core/git-daemon --base-path=/srv/gitosis/repositories
600 rh0-ve3:/srv/gitosis/repositories# sv restart git-daemon
601 ok: run: git-daemon: (pid 8282) 0s
602 rh0-ve3:/srv/gitosis/repositories# sv stat git-daemon
603 run: git-daemon: (pid 8282) 6s; run: log: (pid 6155) 18182s
604 rh0-ve3:/srv/gitosis/repositories# netstat -tulpen | grep 9418
605 tcp 0 0 0.0.0.0:9418 0.0.0.0:* LISTEN 105 680150 8282/git-daemon
606 tcp6 0 0 :::9418 :::* LISTEN 105 680151 8282/git-daemon
607 rh0-ve3:/srv/gitosis/repositories# type psa; psa git
608 psa is aliased to `ps aux | grep'
609 root 6154 0.0 0.0 108 28 ? Ss 06:37 0:00 runsv git-daemon
610 gitlog 6155 0.0 0.0 128 40 ? S 06:37 0:00 svlogd -tt /var/log/git-daemon
611 gitosis 8282 0.0 0.0 48972 1520 ? S 11:40 0:00 /usr/lib/git-core/git-daemon --base-path=/srv/gitosis/repositories
612 root 8288 0.0 0.0 7264 788 pts/1 S+ 11:41 0:00 grep git
613 rh0-ve3:/srv/gitosis/repositories# exit
614 exit
615 sa@rh0-ve3:~$ exit
616 logout
617 Connection to devel.example.com closed.
618 sa@wks:/tmp/test/dolmen$ cd ../..; mkdir test_git-daemon; cd test_git-daemon
619 sa@wks:/tmp/test_git-daemon$ git clone git://devel.dolmen-project.org/dolmen.git
620 Initialized empty Git repository in /tmp/test_git-daemon/dolmen/.git/
621 remote: Counting objects: 6, done.
622 remote: Compressing objects: 100% (2/2), done.
623 remote: Total 6 (delta 0), reused 0 (delta 0)
624 Receiving objects: 100% (6/6), done.
625 sa@wks:/tmp/test_git-daemon$ diff dolmen/README ../test/dolmen/README
626 sa@wks:/tmp/test_git-daemon$ cat dolmen/README
627 PLEASE WRITEME
628 sa@wks:/tmp/test_git-daemon$
Now we need to tell GIT-daemon where to find our repositories which is
done by altering /etc/sv/git-daemon/run as can be seen above. Line 599
acknowledges the path where GIT-daemon lives and, also, the path to
our repositories. Another important part is with chpst -ugitosis which
makes a lookup for the UID (User ID) and GID (Group ID) of our system
user gitosis in /etc/passwd and starts GIT-daemon with those values
(see line 46, 605/606 as well as 609).
After restarting GIT-daemon in line 600 and checking if it is up and
running with line 602, we also take a look at services on rh0-ve3 that
listen on port 9418 in lines 605 and 606 — of course we will see it
is GIT-daemon since 9418 is GIT-daemon's standard port.
If we have a firewall in place it has to allow access to port 9418 in
table filter, chain OUTPUT and INPUT respectively FORWARD in case of
OpenVZ.
Line 611 is yet another quick check in order to be sure everything is
up and running as expected... we are done setting up GIT-daemon.
Again, well done! ;-]
The rest is all about testing anonymous read/pull/fetch access and
then compare the former work with what we see right now — there is no
difference i.e. line 627 shows the change we did above with line 463
when we were testing the write/commit/push functionality.
Automate Repository Creation with GITosis
We wrote a Python script to automate the manual steps shown in lines
263 to 265, 281, 278, 297, 298, 300, 301, 319, 334. One way to use it
is ./create_repo.py <new_repository_name> and then it performs all the
steps from lines 297 to 334 for us automatically.
With our current setup it puts git-daemon-export-ok in place i.e. it
grants read/pull/fetch permissions to anonymous users. However, there
is a -p respectively --private switch to create_repo.py in order to
not create git-daemon-export-ok i.e. to not grant read/pull/fetch
access to the general public (see above).
Later, when we are going to set up GITweb, we will see how
git-daemon-export-ok can not just be used to provide read/pull/fetch
access to anonymous users via GIT-daemon, but, how we also use it to
provide anonymous users with the joy of being able to browse those GIT
repositories using their web browser.
Browsing our GIT Repositories: Next we are going to put an additional
HTTP layer (GITweb) on top of the GITosis and GIT-daemon setup so
users can download snapshots in tar.gz or .zip format, browse, search,
etc. our GIT repositories... all that using their web browser i.e. no
need install any additional software.
GITweb
We have successfully set up GITosis and GIT-daemon above. Now we want
our users to be able to browse the GIT repositories on the server via
GITweb. Before we start though, let us take a look at some screenshots
taken while setting up GITweb on http://gitweb.dolmen-project.org —
those mark our progress so the reader can acquire some taste for what
is to come:

629 sa@wks:/tmp/test_git_daemon$ cd
630 sa@wks:~$ ssh dolmen-devel
631 sa@rh0-ve3:~$ su
632 Password:
633 rh0-ve3:/home/sa# type dpl; dpl gitweb | grep ii
634 dpl is aliased to `dpkg -l'
635 ii gitweb 1:1.6.3.3-2 fast, scalable, distributed revision control system (web interface)
636 rh0-ve3:/home/sa# dpl apache* | grep ii
637 ii apache2-mpm-worker 2.2.11-6 Apache HTTP Server - high speed threaded mod
638 ii apache2-utils 2.2.11-6 utility programs for web servers
639 ii apache2.2-bin 2.2.11-6 Apache HTTP Server common binary files
640 ii apache2.2-common 2.2.11-6 Apache HTTP Server common files
Two things need to be installed as can be seen above —
gitweb and
some httpd like for example apache2-mpm-worker. When that is done, it
is a quick thing until we have things up and running.
Enabling HTTP
First however, we make a little detour by enabling the HTTP (Hypertext
Transfer Protocol) for cloning/fetching/pulling our repositories
hosted on rh0-ve3 where GITosis is used to manage authentication and
repository management.
In other words, we will be able to do git clone
http://devel.dolmen-project.org/dolmen.git after we finished our
detour — note the http instead of git as for example line 619 shows
it.
641 rh0-ve3:/home/sa# cd /srv/gitosis/repositories/
642 rh0-ve3:/srv/gitosis/repositories# la
643 total 168
644 drwxr-xr-x 42 gitosis gitosis 4096 2009-08-05 09:38 .
645 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
646 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:27 dolmen.app.authentication.git
647 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:27 dolmen.app.content.git
648
649
650 [skipping a lot of lines...]
651
652
653 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:29 snappy.transform.git
654 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-30 15:55 snappy.video.player.git
655 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-30 15:55 snappy.video.transforms.git
656 rh0-ve3:/srv/gitosis/repositories# cat snappy.video.transforms.git/hooks/post-update.sample
657 #!/bin/sh
658 #
659 # An example hook script to prepare a packed repository for use over
660 # dumb transports.
661 #
662 # To enable this hook, rename this file to "post-update".
663
664 exec git-update-server-info
665 rh0-ve3:/srv/gitosis/repositories# mv snappy.video.transforms.git/hooks/post-update{.sample,}
First of two things to do is to enable the post-update hook within
each repository we have. We do this by removing the .sample suffix
from the filename as shown in line 665.
As said, that has to be done for each repository but then it is only
shown here once for the snappy.video.transforms.git repository. After
the next commit/push to the repository the post-update hook will kick
in an do its magic and we can pull/fetch/clone over HTTP... if Apache
has been configured to allow it that is ;-]
Second thing to do is to enable read access for Apache to the
directory containing all our GIT repositories
(/srv/gitosis/repositories). We do this with a virtual host entry:
666 rh0-ve3:/srv/gitosis/repositories# grep -A15 'clone via http' /etc/apache2/sites-available/default
667 ### clone via http
668
669 <VirtualHost *:80>
670 ServerName devel.dolmen-project.org
671 DocumentRoot "/srv/gitosis/repositories"
672
673 <Directory "/srv/gitosis/repositories">
674 Options FollowSymlinks
675 Allow from all
676 AllowOverride all
677 Order allow,deny
678 </Directory>
679 </VirtualHost>
680
681
682 rh0-ve3:/srv/gitosis/repositories# apache2ctl graceful
683 apache2: Could not reliably determine the server's fully qualified domain name, using xx.xxx.xxx.xxx for ServerName
684 rh0-ve3:/srv/gitosis/repositories# netstat -tulpen | grep apach
685 tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 0 1112381 614/apache2
686 rh0-ve3:/srv/gitosis/repositories# exit
687 exit
688 sa@rh0-ve3:~$ exit
689 logout
690 Connection to devel.dolmen-project.org closed.
691 sa@wks:~$ cd /tmp
692 sa@wks:/tmp$ git clone http://devel.dolmen-project.org/misc.git
693 Initialized empty Git repository in /tmp/misc/.git/
694 got c29800bf59b3c329e8b012c04af452a9b49de7c6
695 walk c29800bf59b3c329e8b012c04af452a9b49de7c6
696 got 6508b60b0fc7aa20ddbcd1c3f7d2f2ff8b1e2fc0
697 got f100a6b63b7a13e8f3d154813e0d8e7260983d47
698
699
700 [skipping a lot of lines...]
701
702
703 got a862fa709e3d8717717a7b49d45d675cb594c80d
704 walk a862fa709e3d8717717a7b49d45d675cb594c80d
705 got 16e0a5e646e103bac9581e67dc8ff129c98cffd0
706 sa@wks:/tmp$ la misc/
707 total 132
708 drwxr-xr-x 3 sa sa 4096 2009-08-07 12:11 .
709 drwxrwxrwt 29 root root 4096 2009-08-07 12:11 ..
710 -rwxr-xr-x 1 sa sa 6162 2009-08-07 12:11 create_repo.py
711 -rw-r--r-- 1 sa sa 65450 2009-08-07 12:11 dolmen_logo_big.png
712 -rw-r--r-- 1 sa sa 37254 2009-08-07 12:11 dolmen.svg
713 drwxr-xr-x 8 sa sa 4096 2009-08-07 12:11 .git
714 -rw-r--r-- 1 sa sa 284 2009-08-07 12:11 .gitignore
There is not much to say here except that it works as can be seen from
lines 692 to 705. Note that we left rh0-ve3 and entered wks again
before we cloned in line 692. As mentioned, the hook is triggered by a
push to the repository i.e. after enabling the hook there has to be a
push to make it work — the push is not shown here i.e. one either has
to make an explicit push or wait until one happens for some other
reason.
Configuring GITweb
715 sa@wks:/tmp$ ssh dolmen-devel
716 sa@rh0-ve3:~$ su
717 Password:
718 rh0-ve3:/home/sa# cd /usr/share/gitweb/
719 rh0-ve3:/usr/share/gitweb# la
720 total 24
721 drwxr-xr-x 2 root root 4096 2009-08-04 16:22 .
722 drwxr-xr-x 83 root root 4096 2009-08-04 16:22 ..
723 -rw-r--r-- 1 root root 164 2009-06-29 01:20 git-favicon.png
724 -rw-r--r-- 1 root root 208 2009-06-29 01:20 git-logo.png
725 -rw-r--r-- 1 root root 7431 2009-06-29 01:20 gitweb.css
726 rh0-ve3:/usr/share/gitweb# touch {footer,home}.html
727 rh0-ve3:/usr/share/gitweb# la
728 total 36
729 drwxr-xr-x 2 root root 4096 2009-08-08 09:06 .
730 drwxr-xr-x 83 root root 4096 2009-08-04 16:22 ..
731 -rw-r--r-- 1 root root 139 2009-08-08 09:02 footer.html
732 -rw-r--r-- 1 root root 164 2009-06-29 01:20 git-favicon.png
733 -rw-r--r-- 1 root root 208 2009-06-29 01:20 git-logo.png
734 -rw-r--r-- 1 root root 7514 2009-08-08 08:59 gitweb.css
735 -rw-r--r-- 1 root root 7499 2009-08-08 09:02 home.html
736 rh0-ve3:/usr/share/gitweb# cd /tmp/
737 rh0-ve3:/tmp# git clone git://devel.dolmen-project.org/misc.git
738 Initialized empty Git repository in /tmp/misc/.git/
739 remote: Counting objects: 32, done.
740 remote: Compressing objects: 100% (31/31), done.
741 remote: Total 32 (delta 12), reused 0 (delta 0)
742 Receiving objects: 100% (32/32), 282.30 KiB, done.
743 Resolving deltas: 100% (12/12), done.
744 rh0-ve3:/tmp# cd /usr/share/gitweb/
745 rh0-ve3:/usr/share/gitweb# cp /tmp/misc/a_dolmen_with_tree_in_front.jpg .
746 rh0-ve3:/usr/share/gitweb# cp /tmp/misc/dolmen_logo_big.png .
747 rh0-ve3:/usr/share/gitweb# la
748 total 316
749 drwxr-xr-x 2 root root 4096 2009-08-08 09:19 .
750 drwxr-xr-x 83 root root 4096 2009-08-04 16:22 ..
751 -rw-r--r-- 1 root root 210461 2009-08-08 09:19 a_dolmen_with_tree_in_front.jpg
752 -rw-r--r-- 1 root root 65450 2009-08-08 09:19 dolmen_logo_big.png
753 -rw-r--r-- 1 root root 139 2009-08-08 09:02 footer.html
754 -rw-r--r-- 1 root root 164 2009-06-29 01:20 git-favicon.png
755 -rw-r--r-- 1 root root 208 2009-06-29 01:20 git-logo.png
756 -rw-r--r-- 1 root root 7514 2009-08-08 08:59 gitweb.css
757 -rw-r--r-- 1 root root 7499 2009-08-08 09:02 home.html
758 rh0-ve3:/usr/share/gitweb# cd /usr/lib/cgi-bin/
759 rh0-ve3:/usr/lib/cgi-bin# la
760 total 212
761 drwxr-xr-x 2 root root 4096 2009-08-08 10:17 .
762 drwxr-xr-x 42 root root 16384 2009-08-03 17:00 ..
763 -rwxr-xr-x 1 root root 190145 2009-06-29 01:20 gitweb.cgi
764 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/footer.html
765 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/home.html
766 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/git-favicon.png
767 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/git-logo.png
768 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/gitweb.css
769 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/a_dolmen_with_tree_in_front.jpg
770 rh0-ve3:/usr/lib/cgi-bin# ln -s /usr/share/gitweb/dolmen_logo_big.png
771 rh0-ve3:/usr/lib/cgi-bin# la
772 total 212
773 drwxr-xr-x 2 root root 4096 2009-08-08 10:18 .
774 drwxr-xr-x 42 root root 16384 2009-08-03 17:00 ..
775 lrwxrwxrwx 1 root root 49 2009-08-08 10:18 a_dolmen_with_tree_in_front.jpg -> /usr/share/gitweb/a_dolmen_with_tree_in_front.jpg
776 lrwxrwxrwx 1 root root 37 2009-08-08 10:18 dolmen_logo_big.png -> /usr/share/gitweb/dolmen_logo_big.png
777 lrwxrwxrwx 1 root root 29 2009-08-08 10:17 footer.html -> /usr/share/gitweb/footer.html
778 lrwxrwxrwx 1 root root 33 2009-08-08 10:17 git-favicon.png -> /usr/share/gitweb/git-favicon.png
779 lrwxrwxrwx 1 root root 30 2009-08-08 10:17 git-logo.png -> /usr/share/gitweb/git-logo.png
780 -rwxr-xr-x 1 root root 190145 2009-06-29 01:20 gitweb.cgi
781 lrwxrwxrwx 1 root root 28 2009-08-08 10:17 gitweb.css -> /usr/share/gitweb/gitweb.css
782 lrwxrwxrwx 1 root root 27 2009-08-08 10:17 home.html -> /usr/share/gitweb/home.html
When we install gitweb, it places its CGI (Common Gateway Interface)
script (line 763) into /usr/lib/cgi-bin and all the rest into
/usr/share/gitweb (lines 723 to 725) — we can elevate security by
using chattr on /usr/lib/cgi-bin/gitweb.cgi There is also a config
file /etc/gitweb.conf which is shown in lines 783 to 870.
What we do above is simply linking the files from /usr/share/gitweb to
/usr/lib/cgi-bin as lines 764 to 770 show. In addition, we create
files like for example footer.html and home.html which we will later
fill with HTML code in order to provide a footer and a message on our
GITweb's website main page.
We also grab two images directly from one of our already existing GIT
repositories as can be seen in lines 737 to 746.
783 rh0-ve10:/usr/lib/cgi-bin# cat /etc/gitweb.conf
784 ### GITweb config file for gitweb.dolmen-project.org
785
786 # directory to use for temp files
787 $git_temp = "/tmp";
788
789 # HTML text to include/render
790 $home_text = "home.html";
791 $site_footer = "footer.html";
792
793 # Sorting key for main page
794 $default_projects_order = "age";
795
796 # Project root for GITweb. This is the parent directory for all of
797 # your GIT repositories. As an example, 'gitosis-admin.git' should
798 # reside in this directory.
799 $projectroot = "/srv/gitosis/repositories";
800 $projects_list = $projectroot;
801
802 # Web display files. These are all _relative_ paths from the active
803 # gitweb.cgi file. If all three of these files are located in the same
804 # directory as gitweb.cgi (/urs/lib/cgi-bin), then the below settings
805 # should work fine. Remember that if they are in a different
806 # directory, you will need to give your Apache user/group read access
807 # to them!
808 $stylesheet = "/gitweb.css";
809 $logo = "/git-logo.png";
810 $favicon = "/git-favicon.png";
811
812 # Site name
813 $site_name = "The Dolmen Project's GIT Repositories";
814
815 # URL formatting. You can use this to make pretty URLs if you like. I
816 # am doing this using Apache rewrite rules, and so am not using these
817 # settings.
818 #$my_uri = "http://gitweb.dolmen-project.org/";
819 #$home_link = $my_uri;
820
821 # Base URL for repositories. This is used to prefix each of the GIT
822 # repositories on the webpages. So in my case, if you were viewing a
823 # GIT repository/tree called 'foo.git', the webpage would tell you
824 # that the tree was located at:
825 # 'ssh://[email protected]:1234/foo.git'. Note that
826 # escaping the '@' character is necessary to render the URL properly.
827 @git_base_url_list = ("git://devel.dolmen-project.org");
828
829 # Length of the project description column in the webpage.
830 $projects_list_description_width = 70;
831
832 # Only export repositories we are allowing to be publically cloned.
833 # What this setting actually says is that if the given file _exists_
834 # in the GIT repository, then the repository/tree can be exported to
835 # the web. So, for example, the file:
836 # /srv/git/repositories/configs.git/git-daemon-export-ok file exists,
837 # so configs.git will be exported via Gitweb. This file can be created
838 # with a simple '$ touch git-daemon-export-ok'. I am using this
839 # filename as it doubles for the same use with the GIT export daemon
840 # which we set via gitosis.conf. If this setting does not exist, then
841 # all trees will be exported by default. Note that there ARE other
842 # methods for controlling which repositories get exported. This is
843 # just the one I prefer.
844 $export_ok = "git-daemon-export-ok";
845
846 # Enable PATH_INFO so the server can produce URLs of the form:
847 # http://devel.dolmen-project.org/project.git/xxx/xxx This allows for
848 # pretty URLs *within* the GIT repository, where my Apache rewrite
849 # rules are not active.
850 $feature{'pathinfo'}{'default'} = [1];
851
852 # Enable blame, pickaxe search, snapshop, search, and grep support,
853 # but still allow individual projects to turn them off. These are
854 # features that users can use to interact with your GIT repositories.
855 # They consume some CPU whenever a user uses them, so you can turn
856 # them off if you need to. Note that the 'override' option means that
857 # you can override the setting on a per-repository basis.
858 $feature{'blame'}{'default'} = [1];
859 $feature{'blame'}{'override'} = [1];
860
861 $feature{'pickaxe'}{'default'} = [1];
862 $feature{'pickaxe'}{'override'} = [1];
863
864 $feature{'search'}{'default'} = [1];
865
866 $feature{'grep'}{'default'} = [1];
867 $feature{'grep'}{'override'} = [1];
868
869 $feature{'snapshot'}{'default'} = ['zip', 'tgz'];
870 $feature{'snapshot'}{'override'} = [1];
Next we take look at the config file for GITweb in lines 783 to 870.
In addition to the very verbose comments, there are a few important
things to say about it:
- At first, note lines 790, 791 and 808 to 810 where we set the path
for GITweb so it finds our files/symlinks we created in lines 764
to 770.
- Second, lines 818 and 819 — we do not need those because we use
Apache rewrite rules as shown in lines 896 to 899.
- Last but not least, note how we reuse the setting we already have
in place for
granting read/pull/fetch permissions to anonymous users in line
844 — if
git-daemon-export-ok exists within a repository, then
not only can anonymous users clone/pull/fetch the repository but
they can also browse it on http://gitweb.dolmen-project.org.
871 rh0-ve3:/usr/lib/cgi-bin#
872
873
874 [ here we use nano to edit home.html, footer.html, gitweb.css... ]
875
876
877 rh0-ve3:/usr/lib/cgi-bin# grep -A33 '### Gitweb' /etc/apache2/sites-available/default
878 ### Gitweb
879
880 <VirtualHost *:80>
881 ServerName gitweb.dolmen-project.org
882 DocumentRoot "/usr/lib/cgi-bin"
883 DirectoryIndex gitweb.cgi
884 SetEnv GITWEB_CONFIG /etc/gitweb.conf
885
886 <Directory "/usr/lib/cgi-bin">
887 Options FollowSymlinks ExecCGI
888 Allow from all
889 AllowOverride all
890 Order allow,deny
891
892 <Files gitweb.cgi>
893 SetHandler cgi-script
894 </Files>
895
896 RewriteEngine on
897 RewriteCond %{REQUEST_FILENAME} !-f
898 RewriteCond %{REQUEST_FILENAME} !-d
899 RewriteRule ^.* /gitweb.cgi/$0 [L,PT]
900 </Directory>
901
902 <Directory "/srv/gitosis/repositories">
903 Allow from all
904 </Directory>
905
906 # I only used those debug rewrite rules
907 #RewriteLog /var/log/httpd/rewrite_log
908 #RewriteLogLevel 9
909
910 #ErrorLog /var/log/httpd/gitweb
911 </VirtualHost>
Next we need to alter a few files if we want/need to i.e. we for
example change the CSS (Cascading Style Sheets) a bit, provide a
footer and maybe a main page text. I do so as can be seen from the
sceenshots.
We are done except for one last thing — we need to configure yet
another Apache virtual host to make it work. I am not going into
details about lines 880 to 911 since there is a lot of information
about Apache on the Internet already. In addition, I recommend to make
some changes to maybe elevate security a little bit — that step is
totally optional however.
Apache's rewrite functionality is no core functionality which is why
we load the rewrite module in line 912 and then restart Apache in
line 915.
912 rh0-ve3:/usr/lib/cgi-bin# a2enmod rewrite
913 Enabling module rewrite.
914 Run '/etc/init.d/apache2 restart' to activate new configuration!
915 rh0-ve3:/usr/lib/cgi-bin# apache2ctl graceful
916 apache2: Could not reliably determine the server's fully qualified domain name, using xx.xxx.xxx.xxx for ServerName
917
918
919 [ here we use nano to edit /etc/passwd... ]
920
921
922 rh0-ve3:/usr/lib/cgi-bin# grep gitosis /etc/passwd
923 gitosis:x:105:108:Dolmen Project,,,:/srv/gitosis:/bin/sh
924 rh0-ve3:/usr/lib/cgi-bin# cd /srv/gitosis/repositories/
925 rh0-ve3:/srv/gitosis/repositories# la
926 total 168
927 drwxr-xr-x 42 gitosis gitosis 4096 2009-08-05 09:38 .
928 drwxr-xr-x 5 gitosis gitosis 4096 2009-07-12 13:52 ..
929 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:27 dolmen.app.authentication.git
930 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:27 dolmen.app.content.git
931
932
933 [skipping a lot of lines...]
934
935
936 drwxr-xr-x 7 gitosis gitosis 4096 2009-08-07 07:16 misc.git
937 drwxr-xr-x 7 gitosis gitosis 4096 2009-08-07 07:16 snappy.git
938 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-30 15:46 snappy.site.git
939 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-31 17:29 snappy.transform.git
940 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-30 15:55 snappy.video.player.git
941 drwxr-xr-x 7 gitosis gitosis 4096 2009-07-30 15:55 snappy.video.transforms.git
942 rh0-ve3:/srv/gitosis/repositories# cat misc.git/description
943 Repository for miscellaneous stuff with regards to the Dolmen Project.
944 rh0-ve3:/srv/gitosis/repositories# exit
945 exit
946 sa@rh0-ve3:~$ exit
947 logout
948 Connection to devel.dolmen-project.org closed.
949 sa@wks:~$ grep -A2 '\[repo misc\]' 0/gitosis_projects/dolmen/gitosis-admin/gitosis.conf
950 [repo misc]
951 daemon = yes
952 description = Repository for miscellaneous stuff with regards to the Dolmen Project.
953 sa@wks:~$
We are done except for two minor things — we want to give the
repositories a one-line description and provide owner information when
they are shown on GITweb. One easy way is shown in line 923. This way
we can set a default owner and if needed, overwrite that default with
settings in ../foo.git/config as shown below. Note that this has to be
done within the repository (probably a bare repository) on the server
not in ones local clone.
[gitweb]
owner = "Markus Gattol"
Also on the server, each repository has a ../foo.git/description file
as can be seen in lines 942 and 943. We can either leave it as is or
provide a one-line description i.e. edit this file on the server,
rh0-ve3 in our case.
However, since we are using GITosis, there is a smarter way to do it
as is shown in lines 950 to 952 — note that we logged out of rh0-ve3
and thus we are back on wks again. This way, anybody with
administrator permissions to our GITosis platform can easily set new
descriptions by editing gitosis.conf without the need to even log into
the server using SSH (Secure Shell) for example.
We are done, the final version looks like this:
Note how all repositories have the default owner set but just a few so
far have their individual description...
Sharing Changes via pull/fetch and push
Ones local repository can be used by others to pull changes from (git
pull), but normally one would have a private repository and a public
repository. The public repository is where everybody pulls from and
the owner does the opposite — he pushes his changes from his private
repository to his public repository using git push.
Pushing will push/synchronize the local branch(es) with the
corresponding remote branch(es) — note that this works generally only
over SSH (Secure Shell) or HTTP with special web server setup. It is
highly recommended to setup a SSH to use keys (also known as PKA
(Public Key Authentication)) and the SSH-agent mechanism so that there
is no need to type in a password all the time.
-
One important thing to note is, that we should only push to remote
branches that are not currently checked out on the other side —
for
the same reasons we never switch to a remote branch locally! Otherwise
the working copy at the remote branch will get out of date and
confusion will ensue.
-
The best way to avoid that is to push only to remote repositories with
no working copy at all — a so-called bare repository which is
commonly used for public access or developer's meeting point, just for
exchange of history where a checked out copy would be a waste of space
anyway.
GIT can work with the same workflow as Subversion, with a group of
developers using a single repository for exchange for their work (a
bare repository). The only change is that their changes are not
submitted automatically but they have to use git push. The developers
must have either an entry in htaccess (for HTTP DAV) or a user account
for SSH. It is possible for the server admin to restrict their shell
account to GIT pushing and fetching by using the git-shell login
shell.
It is also possible to exchange patches using email. GIT has very good
support for patches incoming by mail. We can apply them by feeding
mailboxes with patch emails to git am. The person who wants to send
patches can use git format-patch and possibly git send-email to do so.
In order to maintain a set of patches it is best to use the StGIT
tool.
WRITEME
Sharing Changes via Patches
Aside from using such popular sites like for example GIThub or setting
up our own public repository with GITosis, we can share changes using
email. In order to do so, the sender needs to create appropriate
patches from his changes and the receiver needs to process those
changes which were send to him via email.
In fact, sharing changes via email seems to be the most common way how
changes are shared among folks as of now (February 2009). The reason
why this is, is probably because it is one of the least cumbersome
setups one can have — right after using sites like GIThub for
example, which in my opinion is going to become the most common method
for sharing changes in the future.
Most folks are just minor contributors and therefore they use git
clone to clone some public repository and then git pull respectively
get fetch followed by git merge to update their local repository on a
regular. This is very easy and straight forward to use for even
non-experts. All they have to do next is to make changes/improvements
to the code and then of course, get those changes back upstream.
Mostly, whenever someone make changes, he creates a topic branch,
makes changes, tests, merges back into master and then deletes the
topic branch after he is done. Now he needs to share his changes with
the upstream repository. Probably the easiest way to do so, is to send
the changes to someone who is considered a major contributor to the
project. Another things many folks do is send their patches directly
to a project's mailing list which is good for reasons of scrutiny etc.
We are now going to take a look at how to create patches that can be
used to share changes via email and also, we are going to take a look
at how to process such emails assuming we are on the receivers end of
the pipe.
Creating Patches
First of all we shall pay attention to some things considered best
practices when it comes to creating patches:
- use
git format-patch -M to create the patch
- do not use GPG (GNU Privacy Guard) to sign a patch
- do not attach your patch, but include it in the mail body, unless
you cannot teach your mailer to leave the formatting of the patch
alone
- be careful doing cut/paste into your mailer in order to not corrupt
whitespaces
- provide additional information (which is unsuitable for the commit
message) between the
--- and the diffstat information
- if you change, add, or remove a command line option or make some
other user interface change, the associated documentation should be
updated as well
- if your name is not writable in ASCII, make sure that you send off
a message in the correct encoding
- if you use
git send-email, please test it first by sending email to
yourself
Submitting Patches
WRITEME
Importing Patches
WRITEME
GIThub and Friends
GitHub is a web-based hosting service for projects that use GIT as
their SCM (Software Configuration Management) system. There are others
too like for example GITorious, http://repo.or.cz/ etc. (see here for
more information).
I have chosen to host/manage the source code for this website/platform
on GIThub simply because I figured that as of now (February 2009) it
has the best tool set with regards to social interaction for folks so
they can contribute.
What still sucks though is the lack of a decent ticketing system but
then, we will see what the situation looks like in a year from now; I
am pretty sure the folks at GIThub are very skilled and hardworking
geeks ;-] Another thing that I would like to see is the whole source
code for GIThub to be released under some FLOSS (Free/Libre Open
Source Software) license.
The fact that some project uses a web-based source code hosting system
like for example GIThub also enables non-geeks and/or folks with just
little time, to contribute to the project — they might for example
fix typos using the web interface i.e. there is no need to be a GIT
expert, Debian developer or maybe some long-time GNU Emacs user or
some other kind of geek of that magnitude.
Upload a project to GIThub
Before that can be done, we need to create an account on GIThub. The
information on how to do that on GIThub is fool-proof so I am not
going to repeat anything here.
Once we have an account on GIThub, we need to put the public key of an
SSH (Secure Shell) key pair into the account on GIThub.
1 sa@wks:~/.ssh$ ssh-keygen -b 8192 -t rsa
2 Generating public/private rsa key pair.
3 Enter file in which to save the key (/home/sa/.ssh/id_rsa): github_id_rsa
4 Enter passphrase (empty for no passphrase):
5 Enter same passphrase again:
6 Your identification has been saved in github_id_rsa.
7 Your public key has been saved in github_id_rsa.pub.
8 The key fingerprint is:
9 44:42:af:ea:d9:bf:b7:99:4b:24:ad:1a:ad:00:80:70 sa@wks
10 The key's randomart image is:
11 +--[ RSA 8192]----+
12 | . |
13 | . . |
14 | . E . + |
15 | o . + . . |
16 | . o S . o |
17 | . . . + |
18 | . o o o |
19 | . o . =.o . |
20 | o ..*o..o. |
21 +-----------------+
I opted to create a new pair especially to use it for GIThub (line 1
to 21). What we can also see from line 1 is that I created a key pair
which has a higher number of bits than the default one which is 2048
bits long.
The name chosen in line 3 is of course one that indicates its usage —
I have tens of key pairs for different usage so github_id_rsa makes
sense. The password supplied in lines 4 and 5 has been created with
one of my aliases in my ~/.bashrc file
sa@wks:~$ type pwg
pwg is aliased to `pwgen -sncB 55 1'
sa@wks:~$ pwg
jwKJcgs7uvnijwp73v4uxbbojghiaeesepwT3gUovKjbhFmzdmgNP7c
sa@wks:~$
22 sa@wks:~/.ssh$ pi github
23 -rw------- 1 sa sa 6431 2009-02-25 15:43 github_id_rsa
24 -rw-r--r-- 1 sa sa 1412 2009-02-25 15:43 github_id_rsa.pub
25 sa@wks:~/.ssh$ cat github_id_rsa.pub
26 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAABAEAretHEeiycQbbEvoQqB9l+9UP4iHFDwDJgQ33b44pMY0lXauE
27 OiLHZM3oqmgqPDpzF2O4qFJil1L+b9owEhkD51UIHe3kdoaTxdwxsm/1+dLl06yL3ZdmDbkRt3Vc9bFla0Sm
28
29
30 [skipping a lot of lines...]
31
32
33 QNIL0n0WCC6llFA+8H+4xsA0/fHd24UoXR9E7Mjy6XxGF49nJVZYy6kj8g6RywwnNNP4sHcanVRh+Lz3s09D
34 WiSE0lTR87qbVNwG/zEhwWAU8hIsGnZZxBZyg8sDabPjIHm4Cb5Pzt6XCQ== sa@wks
In our current case github_id_rsa.pub (line 24) is the public key and
github_id_rsa is the private key from the just created key pair. The
public key is put onto GIThub and the private key kept locally to
identify ourselves against GIThub for certain operations.
We get our public key onto GIThub by copy pasting the output from
lines 26 to 34 into the specified field on the account page
(screenshot below). The private key however must never be shown to
someone and kept secure!
35 sa@wks:~/.ssh$ cd ../0/0/
36 sa@wks:~/0/0$ la
37 total 12
38 drwxr-xr-x 7 sa sa 71 2009-02-25 19:00 .
39 drwxr-xr-x 32 sa sa 4096 2009-02-25 23:01 ..
40 drwxr-xr-x 5 sa sa 54 2008-02-04 20:47 blog
41 drwxr-xr-x 5 sa sa 43 2008-03-12 16:28 misc
42 drwxr-xr-x 7 sa sa 88 2008-06-02 09:52 pim
43 -rw-r--r-- 1 sa sa 1844 2009-02-25 19:00 README
44 drwxr-xr-x 8 sa sa 111 2008-08-29 21:35 ws
45 sa@wks:~/0/0$ git init && git add . && git cwh -m 'inital commit'
46 Initialized empty Git repository in /tmp/0/.git/
47 [master (root-commit)]: created b79875f: "inital commit"
48 1143 files changed, 101682 insertions(+), 0 deletions(-)
49 create mode 100644 README
50 create mode 100644 blog/local/weblog.business.muse
51 create mode 100644 blog/local/weblog.debian.muse
52
53
54 [skipping a lot of lines...]
55
56
57 create mode 100644 ws/latex/latex2png-dm-crypt_luks__3904075528.png
58 create mode 100644 ws/latex/latex2png-dm-crypt_luks__3905517320.png
59 create mode 100644 ws/latex/latex2png-dm-crypt_luks__976832061.png
60 create mode 100644 ws/latex/latex2png-misc__2526884390.png
61 create mode 100644 ws/latex/latex2png-planner__2617796.png
After we have uploaded the public key (github_id_rsa.pub), we need to
initialize the GIT repository, add all files (recursively) and create
the initial commit which we do with line 45.
62 sa@wks:~/0/0$ git st
63 # On branch master
64 nothing to commit (working directory clean)
65 sa@wks:~/0/0$ gllol
66 b79875f3b2267915179313184ac84436984ad33d 14 seconds ago CN: Markus Gattol AN: Markus Gattol S: inital commit
67 sa@wks:~/0/0$ git remote add origin [email protected]:markusgattol/0.git
68 sa@wks:~/0/0$ ssh-add ~/.ssh/github_id_rsa
69 Enter passphrase for /home/sa/.ssh/github_id_rsa:
70 Identity added: /home/sa/.ssh/github_id_rsa (/home/sa/.ssh/github_id_rsa)
71 sa@wks:~/0/0$ git push origin master
72 Counting objects: 1054, done.
73 Compressing objects: 100% (1049/1049), done.
74 Writing objects: 100% (1054/1054), 110.71 MiB | 88 KiB/s, done.
75 Total 1054 (delta 203), reused 0 (delta 0)
76 To [email protected]:markusgattol/0.git
77 * [new branch] master -> master
78 sa@wks:~/0/0$
Before we can push our local repository onto GIThub, we need to add a
remote branch in line 67. Actually we make our just created local
repository think it got cloned from a remote bare repository on
GIThub.
Next we need to tell the SSH authentication agent about our new key
pair (line 68) since, with every git push now, GIThub checks for our
private key to match up the public key we uploaded before. Folks who
forget about line 68 get a Permission denied (publickey) error when
they try to push.
Note that this information — because SSH-agent keeps its information
within RAM (Random Access Memory) which is a volatile memory — does
not survive a reboot or any other kind of power outage for that
matter ergo line 68 need be issued after each reboot.
The passphrase requested in line 69 is the one we supplied in lines 4
and 5 respectively. Finally, in line 71 we can trigger the initial
push which might take a while. When this command finishes, which it
did here, we have successfully uploaded a GIT repository to GIThub in
order to start collaborating with others like for example it is
intended with this website/platform.
Update: After restructuring my SSH setup, I am now using the following
stanza within ~/.ssh/config
sa@wks:~$ grep -A9 -m1 ', github' .ssh/config
###_ , github
# description: just a dummy stanza to make git push work with
# github.com i.e. to pick the right keyfile
Host github.com
User git
Port 22
Hostname github.com
IdentityFile %d/.ssh/github_id_rsa
TCPKeepAlive yes
IdentitiesOnly yes
sa@wks:~$
However, if we were just using a standard SSH setup for
/etc/ssh/ssh_config and/or ~/.ssh/config respectively, then the
approach shown in lines 68 and 69 above i.e. letting the SSH-agent
sort out authentication for us would work perfectly fine.
Nice to know
The contents in this section, I consider nice to know but not in
anyway mandatory for folks who would like to complete a full workflow
circle with GIT.
Creating a tarball plus Changelog for a Software Release
We can use git archive in order to create a tar or zip archive from
any commit of a project that uses GIT as its SCM system.
1 sa@wks:~/0/openvz/vzpkg_test$ gllol | head -n2
2 617669671fadd24edb1f3176153dd5fdd7f86053 5 months ago CN: Robert Nelson AN: Robert Nelson S: Fix read_vz_conf return code so it doesn't cause "set -e" scripts to fail.
3 5615b8134d16020617ba5b30fcbf1cd2fa6360ca 5 months ago CN: Robert Nelson AN: Robert Nelson S: Fix return value from read_vzpkg_conf.
4 sa@wks:~/0/openvz/vzpkg_test$ git archive -l
5 tar
6 zip
7 sa@wks:~/0/openvz/vzpkg_test$ git archive --format=tar --prefix=openvz_vzpkg2/ HEAD | gzip > vzpkg2_`date +%F`.tar.gz
8 sa@wks:~/0/openvz/vzpkg_test$ git archive --format=tar --prefix=openvz_vzpkg2/ HEAD | bzip2 > vzpkg2_`date +%F`.tar.bz2
9 sa@wks:~/0/openvz/vzpkg_test$ pi vzpkg2
10 -rw-r--r-- 1 sa sa 45574 2009-02-27 10:41 vzpkg2_2009-02-27.tar.bz2
11 -rw-r--r-- 1 sa sa 47614 2009-02-27 10:39 vzpkg2_2009-02-27.tar.gz
12 sa@wks:~/0/openvz/vzpkg_test$ tar -tjf vzpkg2_2009-02-27.tar.bz2 | head -n4
13 openvz_vzpkg2/
14 openvz_vzpkg2/COPYING
15 openvz_vzpkg2/Makefile
16 openvz_vzpkg2/NEWS
17 sa@wks:~/0/openvz/vzpkg_test$
The above example creates a tarball release for an OpenVZ utility
called vzpkg2. As we can see in lines 5 and 6, as of now (February
2009) git archive is able to create tar as well as zip archives.
I opted to create tar archives which I further compressed using gzip
in line 7 and bzip2 in line 8. The result can be seen in lines 10 and
11 respectively. With line 12, we take a look inside the archive from
line 10 and can see that the --prefix option from line 8 worked fine
since each filename (or path for that matter) is preceded with
openvz_vzpkg2/.
The tarball is created using HEAD although, as we already know, HEAD
can be replaced by anything that names a commit.
Mostly, when releasing a new version of a software project, we may
want to simultaneously make a changelog to include in the release
announcement. Linus Torvalds, for example, makes new kernel releases
by tagging them, then running $ release-script 2.6.29 2.6.30-rc6
2.6.30-rc7 where release-script is a shell script that looks like:
#!/bin/sh
stable="$1"
last="$2"
new="$3"
echo "# git tag v$new"
echo "git archive --prefix=linux-$new/ v$new | gzip -9 > ../linux-$new.tar.gz"
echo "git diff v$stable v$new | gzip -9 > ../patch-$new.gz"
echo "git log --no-merges v$new ^v$last > ../ChangeLog-$new"
echo "git shortlog --no-merges v$new ^v$last > ../ShortLog"
echo "git diff --stat --summary -M v$last v$new > ../diffstat-$new"
and then he just cuts and pastes the output after verifying that it
looks good.
Last but not least, anybody should then of course digitally sign the
just created tarball using GPG (GNU Privacy Guard) in order to ensure
verifiable data integrity and authenticity to users who use this
tarball
sa@wks:~/0/openvz/vzpkg_test$ gpg --detach-sign --armor vzpkg2_2009-02-27.tar.gz
You need a passphrase to unlock the secret key for
user: "Markus Gattol () <[email protected]>"
1024-bit DSA key, ID C0EC7E38, created 2009-02-06
sa@wks:~/0/openvz/vzpkg_test$ pi gz
-rw-r--r-- 1 sa sa 47614 2009-02-27 10:39 vzpkg2_2009-02-27.tar.gz
-rw-r--r-- 1 sa sa 197 2009-02-27 11:14 vzpkg2_2009-02-27.tar.gz.asc
sa@wks:~/0/openvz/vzpkg_test$ cat *.asc
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1.4.9 (GNU/Linux)
iEYEABECAAYFAkmnvOIACgkQSOlKxsDsfjgd7wCfVwH6ZxhnALPuS7CsdZIy7ozv
RbcAmwatP59hppcEWMnn0Q7O7N8WUFQ+
=YG39
-----END PGP SIGNATURE-----
sa@wks:~/0/openvz/vzpkg_test$ gpg --verify vzpkg2_2009-02-27.tar.gz.asc vzpkg2_2009-02-27.tar.gz
gpg: Signature made Fri 27 Feb 2009 11:13:54 AM CET using DSA key ID C0EC7E38
gpg: Good signature from "Markus Gattol () <[email protected]>"
sa@wks:~/0/openvz/vzpkg_test$
Finding Commits referencing a File with given Content
Let us assume somebody hands us a copy of a file (received_file), and
asks which commits modified a file such that it contained the given
content either before or after the commit. The way we can find out is
1 sa@wks:/tmp$ mkdir demo; cd demo
2 sa@wks:/tmp/demo$ la
3 total 4
4 drwxr-xr-x 2 sa sa 6 2009-02-27 12:59 .
5 drwxrwxrwt 14 root root 4096 2009-02-27 13:00 ..
6 sa@wks:/tmp/demo$ echo 'some blabla' > our_file
7 sa@wks:/tmp/demo$ ll
8 total 4.0K
9 -rw-r--r-- 1 sa sa 12 2009-02-27 13:00 our_file
10 sa@wks:/tmp/demo$ git init; git add .; git cwh -m 'initial commit'
11 Initialized empty Git repository in /tmp/demo/.git/
12 [master (root-commit)]: created 8de1f5c: "initial commit"
13 1 files changed, 1 insertions(+), 0 deletions(-)
14 create mode 100644 our_file
15 sa@wks:/tmp/demo$ echo 'more text' >> our_file
16 sa@wks:/tmp/demo$ git cwh -m 'added more content to file our_file'
17 [master]: created 45cb121: "added more content to file our_file"
18 1 files changed, 1 insertions(+), 0 deletions(-)
19 sa@wks:/tmp/demo$ gllol
20 45cb1212da5d48b062622785841fa4ea489c6b6c 35 minutes ago CN: Markus Gattol AN: Markus Gattol S: added more content to file our_file
21 8de1f5cc61482c965ded2d9abfaf8f0648d9cac9 36 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
22 sa@wks:/tmp/demo$ cp our_file received_file
23 sa@wks:/tmp/demo$ git log --raw -r --abbrev=40 --pretty=oneline our_file | grep -B1 $(git hash-object received_file)
24 45cb1212da5d48b062622785841fa4ea489c6b6c added more content to file our_file
25 :100644 100644 99e51806133707c0c518ed4ad2586b799196ab5a 538e6b4f74c64a7af7eaae4289f77d88405441b8 M our_file
26 sa@wks:/tmp/demo$
The answer is with line 24 — it shows that the file received_file
someone gave us represents the state of received_file right after we
issued line 16 (see line 20) — the commit ID we were looking for is
45cb1212da5d48b062622785841fa4ea489c6b6c.
Figuring out why and how this works is left as an exercise to the
reader — the person who understands line 25 and its meaning will
understand the whole thing we just did. The man pages for git log, git
diff-tree, and git hash-object may prove helpful.
Recovering lost Changes
Even if it might look quite similar, recovering lost changes is not to
be confused with fixing mistakes.
Say we modify a branch with git reset --hard <some_commit_id> (like we
did above), and then realize that the branch was the only reference we
had to that point in history. Why is this a problem?
-
As a short recap from above,
git reset --hard <some_commit_id> resets
not just the pointer which points to the current tip of the currently
active branch (HEAD) to point to some new commit object, but it also
resets the index and the working tree, thus practically deleting any
history from <some_commit_id> onwards. As I mentioned before already,
a git reset --hard cannot be undone! See... there it is... problem!
Fortunately, GIT also keeps a log, called a reflog, of all the
previous values of each branch. So in this case we can still find the
old history using, for example, git log master@{1}.
This lists the commits reachable from the previous version of HEAD.
This syntax can be used with any GIT command that accepts a commit ID,
not just with git log. Some other examples are:
git show master@{2} See where the branch pointed 2,
git show master@{3} 3... commits ago
git show master@{one.week.ago} where master used to point to one week ago
gitk master@{yesterday} See where it pointed yesterday,
gitk master@{"1 week ago"} ... or last week
git log --walk-reflogs master show reflog entries for master
A separate reflog is kept for each HEAD, so git show HEAD@{"1 week
ago"} will show where HEAD pointed to one week ago, not what the
current branch pointed to one week ago. This allows us to see the
history of what we have checked out.
The reflogs are kept by default for 30 days, after which they may be
pruned —
man 1 git reflog and man 1 git gc have more details about
how to control pruning. There is more information to be found within
the Specifying Revisions section of man 1 git rev-parse.
I decided to configure the values for how long a reflog entry is kept
before it gets pruned by e.g. git gc
sa@wks:~/0/0$ git config --global gc.reflogexpire 365
sa@wks:~/0/0$ git config --global gc.reflogexpireunreachable 180
sa@wks:~/0/0$ git config --get gc.reflogexpireunreachable
180
sa@wks:~/0/0$ git config --get gc.reflogexpire
365
sa@wks:~/0/0$
Last but not least, a very important to understand fact on the reflog
history — the reflog history is very different from normal GIT
history. While normal history is shared by every repository that works
on the same project, the reflog history is not shared i.e. it tells us
only about how the branches in our local repository have changed over
time.
In some situations the reflog may not be able to save us. For example,
suppose we delete a branch (the reflog is also deleted when deleting
the branch), then we realize that we need the history it contained.
If we have not yet pruned the repository by running git gc or git
prune directly, then there may still be a chance to find the lost
commits in the dangling objects that git fsck reports
git fsck
dangling commit 7281251ddd2a61e38657c827739c57015671a6b3
dangling commit 2706a059f258c6b245f298dc4ff2ccd30ec21a63
dangling commit 13472b7c4b80851a1bc551779171dcb03655e9b5
[skipping a lot of lines...]
We can examine one of those dangling commits with, for example, gitk
7281251ddd --not --all which does what it sounds like i.e. it says
that we want to see the commit history that is described by the
dangling commit(s), but not the history that is described by all our
existing branches and tags. Thus we get exactly the history reachable
from that commit that is lost.
Notice that it might not be just one commit — we only report the tip
of the line as being dangling, but there might be a whole deep and
complex commit history that was dropped.
If we decide we want the history back, we can always create a new
reference pointing to it, for example, a new branch git branch
recovered-branch 7281251ddd.
Other types of dangling objects (e.g. blobs and trees) are also
possible, and dangling objects can arise in other situations.
Temporarily setting aside Work in Progress
This one I love! It is not just totally practical because it reflects
how humans think and work, but it also allows me to obey
best practices...
We use git stash whenever we want to record the current state of the
working directory and the index, but want to go back to a clean
working directory in order to do some intermediate work that just
sprung into our face.
git stash save will save our changes away to the stash, and reset our
working tree and the index to match the tip of our current branch.
Then we can make our fixes or complete some intermediate work as
usual. After that, we can go back to what we were working on before
with git stash apply.
For example, while we are in the middle of working on something
complicated, we might find an unrelated but obvious and trivial bug or
something that can be seen as a recursion of what we are currently
working on i.e. some intermediate step which is a logical unit for
itself and deserves a separate commit.
Usually, a humans workflow is where we want to go from A to B but then
figure that there is a C necessary to be done before B can be finished
and so we use git stash to stash away the partial work done for B
already, complete C (by starting out with a clean slate) and then,
after finishing C, we finish B.
Below is an example where we use git stash to save the current state
of our work. After fixing a trivia, we unstash the work in progress
from before and continue as with it as usual.
It is just for the sake of brevity that I do not provide a demo on
completing some intermediate step (optionally after doing so on a
different branch and then coming back) which as we might have figured
is a logical unit of itself.
1 sa@wks:/tmp$ mkdir demo; cd demo; touch afile; git init; git cwi; git cwh -m 'initial commit'
2 Initialized empty Git repository in /tmp/demo/.git/
3 [master (root-commit)]: created 10decd6: "initial commit"
4 0 files changed, 0 insertions(+), 0 deletions(-)
5 create mode 100644 afile
6 sa@wks:/tmp/demo$ echo 'some teeeeeext' > afile; git cwh -m 'added some text'
7 [master]: created aff733c: "added some text"
8 1 files changed, 1 insertions(+), 0 deletions(-)
9 sa@wks:/tmp/demo$ gllol
10 aff733c4edacc845a26c4546c3cf3275043244b5 2 seconds ago CN: Markus Gattol AN: Markus Gattol S: added some text
11 10decd6a751c109afc0ce81d54cb2420af7e728e 17 seconds ago CN: Markus Gattol AN: Markus Gattol S: initial commit
12 sa@wks:/tmp/demo$ head -n3 afile; git dwh | wc -l
13 some teeeeeext
14 0
The whole example is self-explanatory so I will just mention the most
important steps taken during this demo. As said, our intention is to
fix some trivia (typo in line 13) using git stash. After committing in
line 6, the working tree is clean at this point as we can see in
line 14.
15 sa@wks:/tmp/demo$ for ((i=0; i < 500; i+=1)); do echo $i; done >> afile; head -n3 afile; git dwh | wc -l
16 some teeeeeext
17 0
18 1
19 506
20 sa@wks:/tmp/demo$ git stash list
21 sa@wks:/tmp/demo$ git stash save 'fixing some trivia'
22 Saved working directory and index state "On master: fixing some trivia"
23 HEAD is now at aff733c added some text
24 sa@wks:/tmp/demo$ head -n3 afile; git dwh | wc -l
25 some teeeeeext
26 0
27 sa@wks:/tmp/demo$ git branch -a
28 * master
29 sa@wks:/tmp/demo$ nano afile
30
31
32 [ here the default editor opened...]
33
34
Line 15 is to simulate some work in progress before we figure out we
might need to set aside some work to address some trivia or
intermediate work. While line 19 shows us that the working tree as
well as the index are not clean because of the work we did, we can see
(line 26) that line 21 does what it is intended to do — it sets back
the working tree and the index to the state of the last commit. In
order to fix the typo I have chosen to use nano as can be seen in
line 32.
35 sa@wks:/tmp/demo$ head -n3 afile; git dwh | wc -l
36 some text
37 7
38 sa@wks:/tmp/demo$ git cwh -m 'some intermediate step (a logical unit of itself)'
39 [master]: created 4e97eff: "some intermediate step (a logical unit of itself)"
40 1 files changed, 1 insertions(+), 1 deletions(-)
41 sa@wks:/tmp/demo$ gllol
42 4e97effd3505fdad3fc66781ea6be14ec19ef914 4 seconds ago CN: Markus Gattol AN: Markus Gattol S: some intermediate step (a logical unit of itself)
43 aff733c4edacc845a26c4546c3cf3275043244b5 5 minutes ago CN: Markus Gattol AN: Markus Gattol S: added some text
44 10decd6a751c109afc0ce81d54cb2420af7e728e 6 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
45 sa@wks:/tmp/demo$ git stash apply
46 Auto-merging afile
47 CONFLICT (content): Merge conflict in afile
48 sa@wks:/tmp/demo$ head -n8 afile
49 <<<<<<< Updated upstream:afile
50 some text
51 =======
52 some teeeeeext
53 0
54 1
55 2
56 3
After the trivia is fixed, we commit this logical unit in line 38.
Note, only for this demo do we make a separate commit for a single
typo. Usually we should always create one commit for one logical unit.
As can be seen above, after issuing line 45, it might happen that we
run into a merge conflict which we simply resolve manually (line 57).
57 sa@wks:/tmp/demo$ nano afile
58
59
60 [ here the default editor opened...]
61
62
63 sa@wks:/tmp/demo$ head -n5 afile
64 some text
65 0
66 1
67 2
68 3
69 sa@wks:/tmp/demo$ git stash list
70 stash@{0}: On master: fixing some trivia
71 sa@wks:/tmp/demo$ git cwh -m 'finished yet another logial unit'
72 [master]: created 821616a: "finished yet another logial unit"
73 1 files changed, 501 insertions(+), 0 deletions(-)
74 sa@wks:/tmp/demo$ gllol
75 821616a41e03562159427896669b318731608154 2 seconds ago CN: Markus Gattol AN: Markus Gattol S: finished yet another logial unit
76 4e97effd3505fdad3fc66781ea6be14ec19ef914 2 minutes ago CN: Markus Gattol AN: Markus Gattol S: some intermediate step (a logical unit of itself)
77 aff733c4edacc845a26c4546c3cf3275043244b5 7 minutes ago CN: Markus Gattol AN: Markus Gattol S: added some text
78 10decd6a751c109afc0ce81d54cb2420af7e728e 7 minutes ago CN: Markus Gattol AN: Markus Gattol S: initial commit
79 sa@wks:/tmp/demo$ git dwh
80 sa@wks:/tmp/demo$
Aside from seeing the final result of our actions in lines 64 to 68,
what is interesting are lines 75 to 78 as it shows that we have a
succession of commits representing a logical unit each — it is not so
that, because we do not know better or because the SCM system we use
is incapable of, we would have to put the logical units from line 75
and 76 into a single commit.
Modifying a single Commit
In an earlier section we saw how to
fix a mistake by editing the history, which for example works by
replacing the most recent commit using git commit --amend. This will
replace the old commit by a new commit incorporating our changes, also
giving us a chance to edit the old commit message.
We can also use a combination of this and git rebase to edit commits
further back in our history. For example, first we tag the problematic
commit with git tag bad mywork~5 — go five commits back into the
past, take this commit and create the tag bad from it.
Then we check out that commit using git checkout, edit it using git
commit --amend, and rebase the rest of the series on top of it (note
that we could check out the commit on a temporary branch, but instead
we are using a detached head):
git checkout bad
[ make changes here and update the index... ]
git commit --amend
git rebase --onto HEAD bad mywork
I think some explanation for git rebase --onto <newbase> <upstream>
<branch> might help understanding what is going on. In our current
case, what happens is:
- check out branch
mywork (if not already on branch mywork)
- save all commits which are not in
bad but in mywork to a temporary
area i.e. what git log bad..mywork would show us
- reset
mywork to HEAD, which at this point in time points to
mywork~5, the commit we fixed that is
- apply all patches saved aside on top of
mywork, one by one, in order
- we clean up with
git tag -d bad
When we are done, we will be left with branch mywork checked out, with
the top patches of mywork reapplied on top of our modified commit.
Note that the immutable nature of GIT history means that we have not
really modified existing commits. Instead, we have replaced the old
commits with new commits having new object names.
Problems with rewriting History
The primary problem with rewriting the history of a branch has to do
with merging. Suppose somebody fetches our branch and merges it into
their branch, with a result something like this:
o--o--O--o--o--o <-- origin
\ \
t--t--t--m <-- their branch
Then suppose we modify the last three commits:
o--o--o <-- new head of origin
/
o--o--O--o--o--o <-- old head of origin
If we examine all this history together in one repository, it will
look like:
o--o--o <-- new head of origin
/
o--o--O--o--o--o <-- old head of origin
\ \
t--t--t--m <-- their branch:
GIT has no way of knowing that the new head is an updated version of
the old head — it treats this situation exactly the same as it would
if two developers had independently done the work on the old and new
heads in parallel. At this point, if someone attempts to merge the new
head in to their branch, GIT will attempt to merge together the two
(old and new) lines of development, instead of trying to replace the
old by the new. The results are likely to be unexpected.
We may still choose to publish branches whose history is rewritten,
and it may be useful for others to be able to fetch those branches in
order to examine or test them, but they should not attempt to pull
such branches into their own work. As I said many times above already:
For true distributed development that supports proper merging,
published branches should never be rewritten!
Inside GIT
A look under the hood...
Examining the Data
We can examine the data represented in the object database (also known
as GIT back end) and the index with various helper tools. For every
object, we can use git cat-file to examine details about the object —
something we have already used in conjunction with git rev-parse
above.
1 sa@wks:/tmp/spear.clan$ git cat-file -t $(git rev-parse HEAD)
2 commit
3 sa@wks:/tmp/spear.clan$ git cat-file -s $(git rev-parse HEAD)
4 423
5 sa@wks:/tmp/spear.clan$ git cat-file commit $(git rev-parse HEAD)
6 tree 5dccb7bc01b01992f06185cb642f7f4f96b078b3
7 parent b1eba669f85e8d6b978217fcef2827d3f2c26eb2
8 author trollfot <trollfot@82af7df8-bc4b-4ebc-8022-2999806f7efb> 1235418218 +0000
9 committer trollfot <trollfot@82af7df8-bc4b-4ebc-8022-2999806f7efb> 1235418218 +0000
10
11 using the last spear.content way to declare portal_type
12
13
14 git-svn-id: http://tracker.trollfot.org/svn/projects/spear.clan@760 82af7df8-bc4b-4ebc-8022-2999806f7efb
Line 2 shows the type of the object, and once we have the type (which
is usually implicit in where we find the object), we can use line 5 to
show its contents. git cat-file -p $(git rev-parse HEAD) would have
also worked just fine though.
It is especially instructive to look at commit objects, since those
tend to be small and fairly self-explanatory. In particular, if we
follow the convention of having the top commit name in .git/HEAD, we
can do
15 sa@wks:/tmp/spear.clan$ git cat-file commit HEAD
16 tree 5dccb7bc01b01992f06185cb642f7f4f96b078b3
17 parent b1eba669f85e8d6b978217fcef2827d3f2c26eb2
18 author trollfot <trollfot@82af7df8-bc4b-4ebc-8022-2999806f7efb> 1235418218 +0000
19 committer trollfot <trollfot@82af7df8-bc4b-4ebc-8022-2999806f7efb> 1235418218 +0000
20
21 using the last spear.content way to declare portal_type
22
23
24 git-svn-id: http://tracker.trollfot.org/svn/projects/spear.clan@760 82af7df8-bc4b-4ebc-8022-2999806f7efb
25 sa@wks:/tmp/spear.clan$
to see what the top commit was. With this convention obeyed, line 5
and 15 cater for the same result as can be seen.
Note: Trees have binary content, and as a result there is a special
helper for showing that content, called git ls-tree, which turns the
binary content into a more easily readable form.
How GIT stores objects efficiently: pack files
We have seen how GIT stores each object in a file named after the
object's SHA1 hash. Unfortunately this system becomes inefficient once
a project has a lot of objects. For example, the source for this
website/platform looks like the below
1 sa@wks:~/0/0$ git count-objects
2 1168 objects, 118688 kilobytes
The first number (1168) is the number of objects which are kept in
individual files. The second is the amount of space taken up by those
loose objects.
We can save space and make GIT faster by moving those loose objects
into a so-called pack file, which stores a group of objects in an
efficient compressed format — the details of how pack files are
formatted can be found in ../technical/pack-format.txt.
3 sa@wks:~/0/0$ git repack
4 Counting objects: 1163, done.
5 Compressing objects: 100% (1150/1150), done.
6 Writing objects: 100% (1163/1163), done.
7 Total 1163 (delta 264), reused 0 (delta 0)
8 sa@wks:~/0/0$ git count-objects
9 1168 objects, 118688 kilobytes
10 sa@wks:~/0/0$ git prune
11 sa@wks:~/0/0$ git count-objects
12 0 objects, 0 kilobytes
13 sa@wks:~/0/0$
The actual magic is with lines 3 to 7. Line 10 removes any of the
loose objects that are now contained in the pack. This will also
remove any unreferenced objects (which may be created whenever we use
git reset for example). We can verify that the loose objects are gone
by looking at the .git/objects directory or by running git
count-objects again as we did in line 11.
Although the object files are gone, any commands that refer to those
objects will work exactly as they did before because of the
pack index.
As mentioned before already, the git gc command performs packing,
pruning and more for us in one shoot so is normally the only
high-level (porcelains) command we need.
Dangling Objects
The git fsck command will sometimes complain about dangling objects.
They are not a problem as we will find out... they can actually be
very useful in case we need to revive deleted stuff.
The most common cause of dangling objects is that we have rebased a
branch, or we have pulled from somebody else who rebased a branch. In
that case, the old head of the original branch still exists, as does
everything it pointed to. The branch pointer itself just does not
exist anymore since we replaced it with another one.
There are also other situations that cause dangling objects. For
example, a dangling blob may arise because we did a git add of a file,
but then, before we actually committed it and made it part of the
bigger picture, we changed something else in that file and committed
that updated that file — the old state that we added originally ends
up not being pointed to by any commit or tree, so it is now a dangling
blob object.
Similarly, when the recursive merge strategy runs, and finds that
there are criss-cross merges and thus more than one merge base (which
is fairly unusual, but it does happen), it will generate one temporary
midway tree (or possibly even more, if we had lots of criss-crossing
merges and more than two merge bases) as a temporary internal merge
base, and again, those are real objects, but the end result will not
end up pointing to them, so they end up dangling in our repository.
Generally, dangling objects are not anything to worry about. They can
even be very useful e.g. if we screw something up, the dangling
objects can be how we recover our old tree (say, we did a rebase, and
realized that we really did not want to — we can look at what
dangling objects we have, and decide to reset our head to some old
dangling state).
For commits, we can just use something like gitk
<dangling-commit-sha-goes-here> --not --all. This asks for all the
history reachable from the given commit but not from any branch, tag,
or other reference. If we decide it is something we want, we can
always create a new reference to it like this git branch
recovered-branch <dangling-commit-sha-goes-here>
For blobs and trees, we can not do the same, but we can still examine
them. We can just do git show <dangling-blob/tree-sha-goes-here> to
show what the contents of the blob were (or, for a tree, basically
what the ls for that directory was), and that may give us some idea of
what the operation was that left that dangling object floating around.
Usually, dangling blobs and trees are not very interesting. They are
almost always the result of either being a half-way mergebase (the
blob will often even have the conflict markers from a merge in it, if
we have had conflicting merges that we fixed up by hand), or simply
because we interrupted a git fetch with ^C (Ctrl + c or in Emacs
speech, C-c) or something like that, leaving some of the new objects
in the object database, but just dangling and useless.
Anyway, once we are sure that we are not interested in any dangling
state, we can just prune all unreachable objects and they will be be
gone.
But we should only run git prune on a quiescent repository — it is
kind of like doing a filesystem fsck recovery; we do not want to do
that while the filesystem is mounted.
The same is true of git fsck itself but since git fsck never actually
changes the repository, it just reports on what it found, git fsck
itself is never a dangerous thing to issue on some repository. Running
it while somebody is actually changing the repository can cause
confusing and scary messages, but it will not actually do anything
bad. In contrast, running git prune while somebody is actively
changing the repository is a bad idea.
Hooks
Go here for information. Sample scripts can be found in
/usr/share/git-core/templates/hooks. Another place to look is directly
within the GIT source code
sa@wks:/tmp/git/contrib/hooks$ la
total 48
drwxr-xr-x 2 sa sa 102 2009-03-01 19:27 .
drwxr-xr-x 19 sa sa 4096 2009-03-01 19:27 ..
-rw-r--r-- 1 sa sa 19324 2009-03-01 19:27 post-receive-email
-rw-r--r-- 1 sa sa 1291 2009-03-01 19:27 pre-auto-gc-battery
-rw-r--r-- 1 sa sa 6920 2009-03-01 19:27 setgitperms.perl
-rw-r--r-- 1 sa sa 11647 2009-03-01 19:27 update-paranoid
sa@wks:/tmp/git/contrib/hooks$

Usage
One nice example is with this source code of my website/platform
itself. In order to get rid of trailing whitespace (which we know is
bad), I decided to activate the pre-commit script by deleting the
.sample suffix from it
sa@wks:~/0/0$ ll .git/hooks/ | grep pre-comm
-rwxr-xr-x 1 sa sa 519 2009-02-25 15:52 pre-commit
sa@wks:~/0/0$
Depending on what method is chosen to edit the source code (I use
GNU Emacs) there may or may not be a means of control in place in
order to check for trailing whitespace — in my case, in order to get
rid of it automatically, I use (add-hook 'before-save-hook
'delete-trailing-whitespace) in my .emacs.
However, this hook (pre-commit) checks for trailing whitespace no
matter what way the source was edited i.e. which editor had been used
or who did it.
1 sa@wks:~/0/0$ cat .git/hooks/pre-commit
2 #!/bin/sh
3 #
4 # An example hook script to verify what is about to be committed.
5 # Called by git-commit with no arguments. The hook should
6 # exit with non-zero status after issuing an appropriate message if
7 # it wants to stop the commit.
8 #
9 # To enable this hook, rename this file to "pre-commit".
10
11
12 ## added by Markus Gattol
13 exec git add .
14
15
16 ## default
17 if git-rev-parse --verify HEAD 2>/dev/null
18 then
19 against=HEAD
20 else
21 # Initial commit: diff against an empty tree object
22 against=4b825dc642cb6eb9a060e54bf8d69288fbee4904
23 fi
24
25 exec git diff-index --check --cached $against --
26 sa@wks:~/0/0$
If we take a closer look, we can also see that I added some additional
code in line 13. This line insures that, for example, new
files/images/etc. I added are not forgotten to be added under version
control with GIT.
Miscellaneous
This section is used to drop anything GIT related here but which on
its own does not deserve a section on its own. The subsections here
must not necessarily have anything to do with each another, except for
the fact that GIT may be the only thing they have in common.
Bash Prompt
Why not enhance our Bash prompt to show GIT related information?
Something like it is shown below, where information like the current
active branch, whether or not we have uncommitted changes etc. is
displayed directly within the Bash prompt. Go here for more
information.
/etc under Version Control
The most obvious benefits of putting /etc under version control are to
clean up the mess somebody inexperienced created when doing some sort
of trial and error within /etc — those folks do stuff but then can
not remember what they did so reverting their changes becomes quite
impossible. That is not so if /etc is under version control.
Another obvious reason is — resulting in pretty much the same actions
as above; looking at the changes (e.g. via git diff HEAD), and maybe
rollback — if for example aptitude full-upgrade or some other akin
tool did something bad.
A third reason why having /etc under version control is so great, is a
multi-user environment — certainly, we want to be able to see who did
what and when. This, in combination with sudo is quite powerful.
Sometimes a business case demands such standard via contracts anyway.
There are many more reasons but the former three are those which I
already experienced myself — once /etc is under version control using
GIT, pretty much only the stars become the only things we might not be
able to go to...
Come quickly, I am tasting stars!
— Dom Perignon, upon discovering champagne.
isisetup
isisetup is one possibility to put ones /etc under version control. I
opted for etckeeper simply because I did not wanted to learn another
UI (User Interface) aside GIT — isisetup has it is own UI so...
etckeeper
The etckeeper program is designed to let us put /etc under version
control. There are a few files involved in the process:
/etc/.gitignore: stores ignore patterns as we already know; this
file is specific to /etc and does not affect other repositories
like for example ~/.gitignore does./etc/.metadata: stores metadata about file owners and permissions./etc/.etckeeper: stores information that can be used to recreate
the empty directories and symlinks./etc/etckeeper/etckeeper.conf: the configuration file for etckeeper/etc/.git: actual repository data for /etc; see repository layout
What is etckeeper? What does it do?
etckeeper is a collection of tools in order to put /etc under version
control in a GIT (the default), mercurial, bazaar or darcs repository.
It hooks into APT (Advanced Packaging Tool) to automatically commit
changes made to /etc during package upgrades.
It tracks file metadata that GIT does not normally support, but that
is important for /etc, such as the permissions of /etc/shadow. It is
quite modular and configurable, while also being simple to use if one
understands the basics of working with SCM (Software Configuration
Management) systems.
etckeeper has special support to handle changes to /etc caused by
installing and upgrading packages. Before APT installs packages,
etckeeper pre-install will check that /etc contains no uncommitted
changes. After APT installs packages, etckeeper post-install will add
any new interesting files to the repository, and commit the changes.
We can also run etckeeper commit by hand to commit changes. In
addition to pre and post hooks, as well as the possibility to manually
trigger things, there is also a cron job, that will use etckeeper to
automatically commit any changes to /etc each day.
Install and Configure etckeeper
1 sa@wks:/etc/etckeeper$ dpl etckeeper | grep ^ii
2 ii etckeeper 0.30 store /etc in git, mercurial, bzr or darcs
3 sa@wks:/etc/etckeeper$ type gr && gr HIGHLEVEL etckeeper.conf
4 gr is aliased to `grep -rni --color'
5 29:HIGHLEVEL_PACKAGE_MANAGER=apt
6 sa@wks:/etc/etckeeper$ cd ..
I have already installed etckeeper as can be seen in line 2. The dpl
command in line 1 and gr in line 4 are just aliases in my ~/.bashrc.
Since I use aptitude I made a change to /etc/etckeeper/etckeeper.conf
as can be seen in line 6. If this line already looks as shown above,
then no actions need to be taken. HIGHLEVEL_PACKAGE_MANAGER should be
apt for all Debian systems or any system using anything in the APT
family for package management. The variable mostly controls
installation of APT config files.
7 sa@wks:/etc$ su
8 Password:
9 wks:/etc# etckeeper init
10 Initialized empty Git repository in /etc/.git/
11 wks:/etc# git commit -a -m "Initial Commit"
12
13 [skipping a lot of lines...]
14
15 create mode 100644 xpdf/xpdfrc-arabic
16 create mode 100644 xpdf/xpdfrc-cyrillic
17 create mode 100644 xpdf/xpdfrc-greek
18 create mode 100644 xpdf/xpdfrc-hebrew
19 create mode 100644 xpdf/xpdfrc-latin2
20 create mode 100644 xpdf/xpdfrc-thai
21 create mode 100644 xpdf/xpdfrc-turkish
22 create mode 100644 yaird/Default.cfg
23 create mode 100644 yaird/Templates.cfg
24 wks:/etc# git gc
25 Counting objects: 2931, done.
26 Compressing objects: 100% (2177/2177), done.
27 Writing objects: 100% (2931/2931), done.
28 Total 2931 (delta 267), reused 0 (delta 0)
29 wks:/etc# ls -lat | head
30 total 1588
31 drwx------ 8 root root 4096 2009-02-14 19:21 .git
32 -rwx------ 1 root root 6101 2009-02-14 19:21 .etckeeper
33 drwxr-xr-x 171 root root 12288 2009-02-14 19:20 .
34 -rw------- 1 root root 433 2009-02-14 19:20 .gitignore
35 drwxr-xr-x 10 root root 4096 2009-02-14 17:47 etckeeper
36 -rw-r--r-- 1 root root 23 2009-02-14 14:29 resolv.conf
37 -rw-r--r-- 1 root root 111633 2009-02-14 13:52 ld.so.cache
38 drwxr-xr-x 2 root root 4096 2009-02-14 13:52 cron.daily
39 drwxr-xr-x 2 root root 4096 2009-02-14 13:52 bash_completion.d
40 wks:/etc# exit
41 exit
42 sa@wks:/etc$ ll etckeeper/post-install.d/
43 total 12K
44 -rwxr-xr-x 1 root root 462 2008-12-17 00:14 50vcs-commit
45 -rwxr-xr-x 1 root root 22 2009-02-15 01:15 99git-gc
46 -rw-r--r-- 1 root root 141 2008-12-17 00:14 README
47 sa@wks:/etc$ cat etckeeper/post-install.d/99git-gc
48 #!/bin/sh
49 echo -e "\ngit repository housekeeping using git gc..."
50 git gc
51 echo -e "git gc finished successfully...\n"
52 sa@wks:/etc$
In line 9 I am initializing the GIT repository — using etckeeper init
instead of git init because the latter one would not take care of all
the metadata, creating ignore patterns, empty directories, etc.
Update: As of version 0.38, issuing etckeeper init is not necessary
anymore as can be seen
sa@wks:~$ zcat /usr/share/doc/etckeeper/changelog.gz | head -n7
etckeeper (0.38) unstable; urgency=low
* Use hostname if hostname -f fails. Closes: #533295
* Automatically commit on initial install, so users can
begin relying on etckeeper right away. Closes: #533290
-- Joey Hess <[email protected]> Wed, 08 Jul 2009 14:40:58 -0400
sa@wks:~$
We can then git status to check that it includes all the right files,
and none of the wrong files. Based on ones individual findings he
would then edit /etc/.gitignore. I did so in another terminal window
but did not include this above since it is individual to my whole
setup. When I was satisfied, I issued line 11 in order to make the
initial commit of /etc.
After that finished we can run git gc in line 24 to do the
housekeeping for us. Actually, we want that to happen after every
apt/aptitude run. Therefore we create a file and put the appropriate
commands in it (lines 48 to 51). As for the other files, it should be
owned by root and have the octal permissions 755 as can be seen in
line 45.
In lines 31 to 39 we can see things like /etc/.git, /etc/.etckeeper
and /etc/.gitignore that got created in the progress.
We have now successfully installed and setup etckeeper, the repository
will track all changes made to /etc, either via APT (Advanced
Packaging Tool), some daemon or manually. Detailed information can be
found with man 8 etckeeper.
GNU Emacs and GIT
No matter what SCM (Software Configuration Management) I am working
with, I usually use Emacs as a frontend since it is a lot faster then
using the CLI (Command Line Interface) and even much more speedy than
using some nonsense GUI (Graphical User Interface). Next to the saving
me a lot of time, using Emacs as a frontend also allows to use the
whole mighty range of Emacs magic that I am used to. I use psvn.el for
SVN. For GIT there are currently two choices
- The combination of
git.el, git-blame.el and vc-git.el or
- DVC (Distributed Version Control)
As of now (August 2007) DVC undergoes heavy development and is not
fully ready for action that is why I use git.el. At some point in the
not so distant future, I will then switch to DVC. At that point I
would like to mention that it is good idea to read the developers
mailing list for DVC in order to be up-to-date about what is going
on. Update: I am now (February 2008) on DVC exclusively.
git.el
DVC (Distributed Version Control)
DVC is an Emacs frontend for various Decentralized Revision Control
systems. It is the successor, and still includes Xtla, which is the
Emacs frontend to tla and baz (GNU Arch client).
Take a look at the aliases in my ~/.bashrc (namely mudvc) in order to
see how I stay with up-to-the-minute DVC code. Installing and setting
up is a piece of cake as well
cd ~
bzr get http://bzr.xsteve.at/dvc/
cd ~/dvc
autoconf
./configure
make
Finally, take a look at the settings in my .emacs (plain text version)
how I load the code, what keybindings I have etc. — search for the
string dvc within .emacs.
git-mergetool
The git manual says e.g. Emacs ediff can be used to resolve conflicts.
You may also use git-mergetool(1), which lets you merge the unmerged files
using external tools such as emacs or kdiff3.
|


















