Miscellaneous
Status: Finished. However, new content might be added at any time.
Last changed: Saturday 2015-01-10 18:32 UTC
Abstract:
I use this page for miscellaneous content -- content that does not fit into the context of any other page or simply is of just little volume and thus does not deserve a dedicated page.
|
Table of Contents
|
Naming Schemes
A naming scheme is a plan for naming objects. In computing, naming
schemes are often used for objects connected into computer networks. I
am, as many others, confronted with naming devices (e.g. servers,
workstations, routers, switches, etc.) connected to a computer
network. Until now, except for my private equipment, I always had to
live with what was already in place and go from there :-/
Usually, Computer/IT (Information Technology) Networks or respectively
IT infrastructure grows more or less uncontrolled which is of course a
very bad thing. Because it does grow more or less uncontrolled, last
thing people care about is a decent naming scheme for devices
connected together via some computer network.
Now that I have the opportunity to shape an entire IT infrastructure
from scratch, I decided to sit down for a day or two and evaluate this
whole shebang in order to come up with a decent naming scheme that
simply fits our current as well as future needs. Speaking of...
Future needs... Whatever the naming scheme is going to be, it needs
to scale i.e.
- work for just a hand full of devices in one geographical location,
managed by just one person up to
- thousands of devices spread across the globe, managed by an army of
tech engineers
User Name
Let us dive right in. My user name is sa:
sa@wks:~$ whoami
sa
sa@wks:~$
Therefore, my terse policy is as follows:
- Must be 2-8 characters long, all lower case, alphanumeric,
starting with an alphabetic. No dots, blanks, underscores, etc.
- Common choices are first name, last name, initials (this is what I
do), etc.
- ONE username for ALL systems i.e. UNIX, NT, VMS, SecurID, Oracle,
PostgreSQL, MySQL, etc.
- Anyone can have any name he wants as long as it is not already
taken or something stupid like
hitler, anal, etc. Therefore, if you
really want to be known as fluffy, go for it, big boy ;-]
Hostname
I name hosts i.e. what we find in /etc/hostname based on some scheme I
came up with over the years. Why is this important over all? Well, it
is not if it is about one person with just one computer who never uses
the CLI (Command Line Interface) but prefers GUIs (Graphical User
Interfaces). On the other hand, if someone is like me, CLI junkie,
dealing with lots of machines (local and remotely), we simply have to
come up with a logical, easy to understand and for the mundane
applicable host naming scheme that simply works. I think my naming
scheme is good (no rocket science but somehow that is the whole point
otherwise nobody would use it) since it does what a host naming scheme
is intended to do... nothing more and nothing less.
-
A host naming scheme should provide a person sitting in front of a
computer, logged in locally or remotely, with a mnemonic so he knows
with a glance on the left side of the CLI on what machine he currently
works.
Anything else than that... simply not going to scale! Well, maybe
for the person @home with his three or so computers named after his
pets or even worse, movie characters and such. This is exactly how you
introduce chaos once an infrastructure starts growing. With something
like user_0@skywalker, folks find it quite hard to determine that it
is them, currently logged onto a server via SSH (Secure Shell) which
is located within a datacenter hundreds of miles away in Huston Texas,
hosting some MongoDB databases.
Some Examples I consider bad Practice
Here are some notorious examples of what should be avoided. As simple
as it is, many people tend to be attracted by those bad practices like
is a moth to light... we all know how that ends... finally, last we
see/hear of the moth is zzzzzzzzap, some smoke... Voila ce que c'est
que de... You do not want to be a moth ;-]
- Running out of hostnames
-
Remember that you will always end up needing one more name than the
category contains. For example, avoid the 7 dwarf's names — you will
end up with 9 machines in that group, despite what you think now.
Also, stuff like planets are definitely not going to work since there
is a limited number of them floating around.
- Non speaking names
-
What is true for planets is also true for stuff like using the common
names from Lord of The Rings. What does a movie character tell about a
server or the services running on it? Nothing and therefore it is a
bad choice for a hostname.
-
Another bad example is to use
pwgen as an inspiration. It gives
meaningless names. There are folks which have names like yiwaz
(laptop), vojei (router), aija (a second laptop), aine (powerpc box),
etc. Again, what does vojei tell about a specific server? Its location
and services running on it etc.? The question has been posed How will
a new person know what the server does if it is not named something
logical?
The Dilemma with Host Naming Schemes
Its amazing, but naming machines tends to be a religious subject —
comes right after stuff like Vim vs Emacs, Ubuntu vs Debian, etc. The
3 or so worst fights I have ever seen (professionally) were all over
naming schemes. I would hate to recommend what someone should name his
machines, but I will share some of my thoughts on what one should
consider. (It is really more like a random spewing of many of my
thoughts on the subject).
There are essentially two camps on this issue. On one side are the
people who want everything to look like prt02nycd4, which means
something to them. On the other side are people who would like human
readable hostnames like zenda for example. There are reasonable
arguments to be made for both:
Encoding Names
There are two main reasons for creating machine-readable,
human-unmemorable names:
- To encode every piece of information possible into it and
- to enable rapid rollouts of machines
The main argument for encoding information into the hostname is to
allow the system administrators, upon simply seeing the hostname, to
be able to tell everything there is to know about the machine...
- its purpose
- location
- type
- user
- production or development system
- OS (Operating System) flavor
- etc.
While doing this may make a system administrator's live easier, every
time some aspect of this information changes we must change the
hostname, or we cannot depend on any of the names. Databases, CMSs
(Content Management Systems) and the like on the other hand, are
really good at keeping this kind of information up-to-date, and they
do not require us to rename the machine when we
- physically move it or
- change its usage from being a database server to hosting a
mail system or
- move it from development to production
- etc.
Putting in place a CMS (or something like it), will allow us to do the
mapping between hostnames and all information with regards to a particular host.
This way we can look up hostnames like calvin or rd0 and be told that
it is, for example, a Xeon Quad Core with 64 GiB of RAM (Random Access
Memory), currently in use by the human user joe and tina, with a
particular IP address in a specific location (e.g. datacenter). Having
automated update procedures makes sure the information does not go out
of date.
Allowing rapid rollouts is a much stronger argument. When we are
rolling out 10 machines a day, selecting interesting and memorable
name becomes more difficult, though certainly not impossible, and
usually a creative challenge!
Human Digestible Names
There are also numerous benefits for naming systems in a human
readable, and likeable, form:
- If users are looking for a calculation server, it is easier for
them to look for
calc1 than pc013b.
- When calling the helpdesk for a machine that is down, a user might
actually be able to provide the name of their machine.
- It is also important not to overlook the psychology of users since
what we really want is happy users. A way to make a user feel more
comfortable with their system is to make it take on more of a
personality. Providing it with a memorable name is one way to
accomplish this.
Incidentally, if system administrators regularly support a user, they
will also come to quickly place his machine, since these names are
more memorable to system admins as well. One scheme that worked well
is naming groups of machines with similar names, so that any football
team, for instance, represent one area. When an sys admin sees a
machine named jets he knows that it is in the football group (or the
planes group). This tends to work in medium sized companies best but
is certainly not very scalable (see above). Some specific advice:
- Naming machines after people, as others have indicated, is really
bad. I left a company 8 years ago, and I think a machine with my
name on it is still floating around there.
- For very similar reasons, naming machines based on their IP
address is also bad. If we ever plan to move machines (and I
assume that everybody does — most of the places that I have
worked at move machines on a regular) we will also have to rename
machines, and, depending on applications and operating system
type, this can be very painful. Host files were invented so we
would not need to remember our IP address. While many people claim
that renaming hosts is easy, not renaming them is even easier (and
I would like to see them rename 1000 windows 3.1 systems over a
weekend move!).
The most important thing to consider when coming up with a naming
scheme is to think about what we are trying to accomplish and make
sure our users will agree as well. This in turn requires users to be
included in the brainstorming process!
- Are we trying to make our sys admins lives easier at any price? Do
they need to know by simply looking at a hostname everything about
that machine or might an additional database respectively CMS be a
better way to go for all involved people i.e. users, tech staff,
management etc.
- Do we care if our users remember their machine names? It is much
more likely that they will remember and enjoy a name like
snowwhite
rather than dnys103fg.
- Are we trying to name clients, servers, or both? We may want to
name a server after a function, so that people can address it
(especially if we do not have tools to automatically direct them to
a service). On the other hand, we may want to either allow for
personalization of clients, or, if we are rolling out many clients,
we may want names that can be automatically generated.
Best thing to do is to take a look at what common sense is there
already. Mostly, with computer stuff that means looking at some RFC
(Request for Comments) paper. In our particular case, that would be
RFC 1178 also known as Choosing a Name for Your Computer. After I read
it, here is what I came up with in order to keep things from falling
apart and folks from getting confused and corporations from wasting
tons of money simply because no one ever took care of introducing a
host naming scheme.
Things we should NOT encode/do with the Hostname
- OS (Operating System) flavor e.g. Linux, Windows, Novel, Solaris,
AIX, etc. Machines have different OSes installed during their
lifetime and therefore encoding it with the hostname is not smart.
- Services it provides respectively tasks it carries out. Those
change way to often and therefore including it with the hostname
makes no sense.
- Peoples names who currently work with the machine (see above).
- A machines IP address, VLAN (Virtual Local Area Network) ID
(Identifier), cluster ID, MAC (Media Access Control) address,
switch it is connected to, etc.
In short, everything that is highly possible to change over time
should not be encoded with the hostname of a particular device.
Things that make sense to encode respectively we should do with the Hostname
- Type of machine i.e. microwave oven, digicam,
workstation, notebook, server, router/switch, cell phone, etc. I
assume, unless we have some sort of transformer gadget, a
workstation is not going to transform into a cell phone so encoding
it with the hostname seems all right.
- Location of a machine if it is a server and the like (hardware that
is usually not moved once it got installed). The location encoded
should be, for example, the datacenter but not be more detailed.
Servers move around within (e.g. from one cage to another, one rack
to another, one room to another etc.) a datacenter but usually do
not get transported from one datacenter to another or one town to
another. For a subnotebook however, we would not encode a
geographical location at all since it might travel the globe a lot.
- Some unique ID (Identifier) if it happens that there are many
machines at the same spot, doing the same thing, looking exactly
the same and are used by the same people. It could be as simple as
numbering them e.g. starting with
0 and increasing this ID as much
as needed. The outcome might then look like this rd0, rd1... ,
rd48.
- The shorter the better. Alphanumeric characters only etc. Actually
the same that applies for user names also applies for host
names.
One thing that is a given is that, unless we are the only person at
our site, there will be people violently, in some cases homicidally,
opposed to whatever naming scheme we come up with. Live with it! Do
not flinch. The important thing is that we think about what we are
trying to accomplish, make sure that our reasons are acceptable, pick
a naming scheme, start using it and stick to it. And very importantly,
document and publish both the scheme and why we have chosen it. If we
do not do this, someone will come along 6 months later and try to do
it all over again.
Practical Approach
With this subsection, I am now going to show the practical part
i.e. how I use the afore mentioned information to name my devices.
Workstation
sa@wks:~$ hostname
wks
sa@wks:~$
As can be seen, my workstation is simply called wks. This is perfectly
fine because
- It is between 2 and 8 characters long.
- Lowercase.
- Starts with an alphanumeric.
- Consists of alphanumeric only.
- No dots, blanks, underscores, etc.
- No embarrassing or stupid name like e.g.
twit.
- I am running DebianGNU/Linux but as I mentioned above, we do not
encode the OS with the hostname but use some CMS or database or
whatever fits.
- There is no notion about the services running on it, the tasks it
is used for etc. simply because it makes no sense to encode it into
the hostname (especially for a workstation).
- The person name working on the machine is not encoded with the host
name. It would be especially superfluous doing it with my
workstation since I am the only one using it anyway. We put this
into some text file, CMS or database etc.
- Things like the IP address, MAC address, VLAN ID etc. are not
encoded with the hostname of my workstation. This goes into some
CMS as well.
- The type of machine is indicated by
wks (short for workstation).
- There is no need to encode the location with the hostname since my
workstation may be moved around.
- Since I only have one workstation, there is no need for encoding
some unique identifier with the hostname.
- Last but not least, because I did not have to encode a few things
with the hostname of my workstation, I end up with a short host
name —
wks, only three characters long.
Subnotebook
sa@wks:~$ ssh -p 33286 192.168.1.102
[email protected]'s password:
Linux sub 2.6.25-2-amd64 #1 SMP Tue May 27 12:45:24 UTC 2008 x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
You have new mail.
Last login: Sat Jun 21 23:39:36 2008 from wks.local
sa@sub:~$ hostname
sub
sa@sub:~$ exit
logout
Connection to 192.168.1.102 closed.
sa@wks:~$
As can be seen, my subnotebook is simply called sub. This is perfectly
fine because
- It is between 2 and 8 characters long.
- Lowercase.
- Starts with an alphanumeric.
- Consists of alphanumeric only.
- No dots, blanks, underscores, etc.
- No embarrassing or stupid name like e.g.
twit.
- I am running DebianGNU/Linux but as I mentioned above, we do not
encode the OS with the hostname.
- There is no notion about the services running on it, the tasks it
is used for etc. simply because it makes no sense to encode it into
the hostname (especially for a subnotebook).
- The person name working on the machine is not encoded with the host
name. It would be especially superfluous doing it with my
subnotebook since I am the only one using it anyway.
- Things like the IP address, MAC address, VLAN ID etc. are not
encoded with the hostname of my subnotebook.
- The type of machine is indicated by
sub (short for subnotebook).
- There is no need to encode the location with the hostname since my
subnotebook may be moved around.
- Since I only have one subnotebook, there is no need for encoding
some unique identifier with the hostname.
- Last but not least, because I did not have to encode a few things
with the hostname of my subnotebook, I end up with a short host
name —
sub, only three characters long.
Random Server (remote Access)
Now, that I have shown two examples of machines which I use locally
i.e. they are at the same geographical location as I am, I am going to
show a probably more interesting hostname scheme for remote machines.
I have servers which I manage remotely (e.g. via SSH (Secure Shell))
since they are located far away in some datacenter — we are talking
about colocation of hardware...
Usage Scenario for a Host Naming Scheme
In order to administer them and to comply to all the rules from above,
I had to came up with some scalable, expressive but yet simple and
intuitive naming scheme. Let us get just right to the point:
1 sa@wks:~$ ssh rd0
2 [email protected]'s password:
3 Linux rd0 2.6.24-1-686 #1 SMP Thu May 8 02:16:39 UTC 2008 i686
4
5 The programs included with the Debian GNU/Linux system are free software;
6 the exact distribution terms for each program are described in the
7 individual files in /usr/share/doc/*/copyright.
8
9 Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
10 permitted by applicable law.
11 Last login: Sun Jun 22 06:46:05 2008 from xxxxxxxxxxxxxxxxxxxxxxxxxxxx
12 sa@rd0:~$ hostname
13 rd0
14 sa@rd0:~$ exit
15 logout
16 Connection to 178.230.145.77 closed.
17 sa@wks:~$
Wow, now what was that?! There are basically three things going on
in lines 1 to 17.
- We are logging into a remote machine using its hostname
rd0.
- Line 1 shows
ssh rd0 which not just shows the hostname of the
machine we are going to log in to but also is an alias so we do not
have to type something like this ssh -p 16784 178.230.145.77 over
and over again every time we want to log into this particular
machine. Aside from saving keystrokes, I am not the kind of guy who
remembers hundreds of IP addresses but my ~/.ssh/config does. The
SSH (Secure Shell) bits and pieces (~/.ssh/config snippet below) I
am showing here are out of scope for the current issue therefore I
am not focusing on security i.e. it should be clear that just
moving the sshd listening port from 22 to 16784 is by far not all
that should be done in terms of security. Those who are interested
into the SSH part might go on my security page.
- Lines 12 and 13 show that the machine is really called
rd0
(completely independent from our SSH alias which just happens to be
the same... on purpose of course).
So, for the first time now we already see how naming a host decently
eases things (line 1) simply because we can recognize this host and
therefore do some other stuff like for example set aliases in
~/.ssh/config
sa@wks:~$ cat .ssh/config
[skipping a lot of lines...]
Host rd0
HostName 178.230.145.77
Port 16784
User sa
[skipping a lot of lines...]
sa@wks:~$
although those two actions, (setting the hostname (/etc/hostname) and
setting an SSH alias (~/.ssh/config)), are completely unrelated from a
technical point of view, the whole purpose of introducing a decent
naming scheme is all about such things like the current usage scenario
— we can do stuff like setting SSH aliases and the like based on the
hostname.
Decoding the Hostname rd0
Now that I have given one possible usage scenario (and there are many
more) for a hostname, we are now going to analyze the hostname rd0
i.e. what does it mean to someone starring at the prompt of his CLI.
With rd0,
r denotes remote i.e. it is no machine I use locally like for
example my sub or wks.d denotes a location namely Datacloud (a specific datacenter where
I have hardware in colocation).0 is an identifier that identifies a particular host at this
location (this may be a particular box or a virtual server e.g. an
OpenVZ instance).
Although this three letter hostname looks very trivial and one might
ask himself All this trouble for this simple hostname? Yes,
absolutely because I am not done explaining it in detail yet.
Now that we know what r, d and 0 determine, it should be clear that
for example rvi57 is box number 57 located in Vienna at Interxion
(Austrias biggest Internet Exchange). Since Interxion has numerous
datacenters all over the globe, we need to have some indicator which
of them we are talking about... v stands for Vienna and therefore vi
denotes Interxion's datacenter in Vienna.
The idea here is quite clear, only do we encode things with the host
name when we need to since the shorter a hostname is, the better it
is. If we recap, my workstation for example is named wks even though I
could encode a whole lot of other things with the hostname that are
clear anyway e.g. sunowksquadcore. That is an example of how to not
do it. I know my name and also do I know that my workstation has a
Quad Core CPU (Central Processing Unit) build in so only a twisted
mind would encode that into the hostname and make it 16 (!)
characters long.
Another example is rh3. It is my third box, located at Hetzner. Since
there is only one Hetzner (there is Germany/Nuernberg and South
Africa) where I have hardware in colocation (same as for Datacloud)
there is no need to encode the geographical location (city or country)
with the hostname i.e. no need for rnh3 where n would denote
Nuernberg (a city in Germany). As for all the other rules we are going
to stick to, rd0 is just fine as we can see:
- The hostname is between 2 and 8 characters long.
- Lowercase.
- Starts with an alphanumeric.
- Consists of alphanumeric only.
- No dots, blanks, underscores, etc.
- No embarrassing or stupid name like e.g.
thug.
- I am running DebianGNU/Linux but as I mentioned above, we do not
encode the OS with the hostname.
- There is no notion about the services running on it, the tasks it
is used for etc. simply because it makes no sense to encode it into
the hostname.
- The person(s) name(s) working on/with the machine is/are not
encoded with the hostname.
- Things like the IP address, MAC address, VLAN ID etc. are not
encoded with the hostname.
- The type of machine is not indicated by
rd0 but one would assume it
is a server, switch or something like that anyway since it is a
remote device because as indicated by r. To be sure, we would check
our database, plain text file, CMS or whatever else holds the
up-to-date and detailed information for rd0.
- There is no need to encode the location with the hostname simply
because this time I know, there is only one Datacloud datacenter.
As in comparison to
vi for Interxion's datacenter in Vienna (see
above).
- Since I have a whole bunch of devices at Datacloud, some unique
identifier (
0) is encoded with the hostname. Again, the CMS,
database etc. will provide us with detailed information about rd0.
- Last but not least, because I did not have to encode a few things
with the hostname of this particular device, I ended up with a
short hostname —
rd0, only three characters long.
Adding Virtualization to the Mix
What if we are not just talking about one box i.e. one OS (Operating
System) but a virtualized environment with one host and many guest
OSes? I am for example a total OpenVZ fan boy. This implies that I am
running many VEs (Virtual Environments) on top of one single host also
known as HN (Hardware Node). Any VE behaves and allows me to do the
same things as with any real server therefore my concept about host
naming schemes need be extended to include the notion of a virtualized
environment. No problem. Here is what I do. (For details e.g. about
the specific layers of abstraction with some virtualized environment,
please go, read about OpenVZ and return afterwards.)
Let us assume I am using the afore mentioned server (rd0) to pull up a
virtualized environment. The hostname for the first VE on top of rd0
would then become rd0-ve0, for the second VE it would be rd0-ve1 and
so forth. I have already decoded the rd0 part above. rd0-ve0 would
then encode as
- We are talking about virtualization because the hostname extends
the base part (
rd0) for -ve0 (the virtualization part).
- The type/flavor is OpenVZ simple because it reads
...ve.. whereas
it would read ...lvs.. i.e. rd0-lvs0 for Linux-VServer, rd0-xen0
for Xen and so on.
- It is the first VE also known as VPS (Virtual Private Server) etc.
on top of the host because of
...0 i.e. ...ve0 (first VE). Would it
be VE number 49 then it would read ...ve49.
A few examples
sub-ve2, I am using my subnotebook as the host system. The
virtualization approach is OpenVZ because of ...ve... We are
talking about the second VE running on my subnotebook.rli2-xen12, Remote box, located in London, datacenter Interxion,
physical box number 2. Xen DomU number 12 running on the host
system rli2.rh3-ve56, Remote box, located at Hetzner, physical box number 3.
OpenVZ VE number 56 running on top of rh3.
We are done. Anyone should now be able to read a bit, think about what
is a decent naming scheme for his requirements and then come up with
something similar as I did.
Ultimately, my naming scheme is very scalable (one of the requirements
I identified before starting with this whole subject). Aside from the
above cases (wks, sub, rd0, rvi57, rh3, etc.) it is also used for
client machines running all sorts of OSes, devices which are not
computers but some other gadgets etc. This just tells me I did my job
right.
Mapping Hostnames
Finally, whatever hostname we came up with, we might have a CMS like
Django CMS where we do the mapping between some hostname like for
example rh3-ve56 and more detailed information about them:
rh3-ve56
- Remote box, located at Hetzner, physical box number 3. OpenVZ VE
number 56 running on top of
rh3.
- Users: sa, twister, notz, sepp, steih
- Usage: GIT hosting of project blabla
- Hardware is blablabla... in action since blablabla etc.
- Info about the datacenter and contract e.g. bandwidth, contact
person, etc.
- SLA (Service Level Agreement) of all sorts
- etc.
We are done — not only have we discussed a host naming scheme but
also how to do the mapping in a smart way i.e. a CMS can be used by
many users to keep information about a particular machine up-to-date,
can have images and all other sorts of information about a particular
machine.
Since most machines are accessed via SSH (Secure Shell), folks can
still refer to rh3-ve56 individually by using the Host keyword in
their ~/.ssh/config. In the above example, the user twister
might use
###_ . rh3-ve56
Host git-repo
HostName devel.example.com
Port 38489
whereas notz might use
###_ . rh3-ve56
Host work-devel
HostName devel.example.com
Port 38489
I hope others can get something out of this section that might help
them for their own endeavor of inventing a decent host naming scheme.
User Password
The big picture is still missing its last part — after we have a
user name and a hostname, we need to come up with passwords
for our users. This passwords are then required when somebody
wants to use his user to log into the machine via SSH (Secure
Shell) for example. In short, whenever somebody wants to log into this
host, his user credentials (user name and password) will be
required to do so.
There are basically two ways to come up with the last missing part
- We can create a password which is completely unrelated to the host
name as well as to the user name or
- We can create a password somehow related to the hostname and the
user name
Both have advantages as well as disadvantages over the other. Which
one to pick is entirely up to anyone himself and the current use case
he is dealing with. The whole purpose of creating passwords which are
related to user names and hostnames is so that we can use the
same command sequence over and over again to create passwords in a
reproducible manner as long as we do not change the command sequence
itself but have only changing user names and hostnames.
Unrelated to User Name and Hostname
Because of its nature — being unrelated — this one is more secure in
terms of that it is practically not possible to guess it or somehow
compute it. Here is how to create one such password which is unrelated
to the hostname and also unrelated to the user name.
Related to User Name and Hostname
This one has some potential risk because, we are going to use a
sequence of commands which, roughly speaking, transform the
<user_name><host_name> pair into the password.
In order to so, we are going to use a what is know as one-way-function
i.e. if someone knows the <user_name><host_name> pair plus the command
sequence we used to create the password, he can compute the password.
What does this mean? Well, nothing less than Should anyone else ever
get his hands onto this command sequence, then we have a huge security
issue!
This is because anyone who knows the <user_name><host_name> pair but
not the command sequence that was used to compute the password cannot
compute the password. Only if we have both, the command sequence and
the <user_name><host_name> pair, can we compute the password.
<user_name><host_name> Pair
Let this be sard0 whereas sa is the user name and rd0 is the
hostname, just as we already used them in the examples above.
One-way-function Command Sequence
In fact, there are already many tools we can use. One of them is
md5sum which we are going to use now.
1 sa@wks:~$ echo sard0duck | sed y/d-p/2-6/ | md5sum | cut -c1-9
2 797acc1d8
3 sa@wks:~$ echo tomrd0duck | sed y/d-p/2-6/ | md5sum | cut -c1-9
4 2d66bee0e
5 sa@wks:~$ echo tomrd1duck | sed y/d-p/2-6/ | md5sum | cut -c1-9
6 861ff32cd
7 sa@wks:~$
The examples in lines 1 to 7 above demonstrate what I am talking
about. We got two users, sa and tom and two hosts, rd0 and rd1. Now,
this is the only information that we consider is known by anyone.
All the rest — our command sequence including the one-way-function
— is not public and must never be known by anyone else than the
person who creates all the passwords for other peoples users on
a host.
It should be quite clear, that the above shown command sequence can be
altered to fit somebodies personal likings/demands
i.e. we might not append duck but maybe we might prepend 43france. And
of course, the sed part might be altered or even not used at all.
Other commands might be added to scramble the string etc. Go wild!
Again, anybody knows about sard0 which is ok. Once somebody gets his
hands on the process how the password (line 2) for sa on rd0 has been
computed e.g. line 1, he could compute any other password for any
other user on this host as well and maybe even worse, he might be able
to compute all the passwords for all users across all our hosts
if we use the same command sequence on all hosts as can be seen above
from lines 3 and 5.
Bottom line here is, even though it is a straight forward process for
the person who sets up new user accounts across many hosts on a
daily basis for other folks to use (probably including /etc/sudoers
magic), this also carries a high risk factor should the connecting key
(the command sequence with the one-way-function) leak out. I therefore
only recommend this way of creating passwords to experts and only if,
for some reason, they want/need to have this sort of reproducible
connection between
- the
<user_name><host_name> pair and
- the passwords
System Request Keys
The magic SysRq (System Request) key is a key combination in the Linux
kernel which, if the CONFIG_MAGIC_SYSRQ option was enabled at kernel
compile time, allows the user to perform various low level commands
regardless of the system's state using the SysRq keys. It is often
used to recover from freezes, or to reboot a computer without
corrupting the filesystem.
Go here or take a look at the kernel sources at
../Documentation/sysrq.txt if your machine freezes and does not
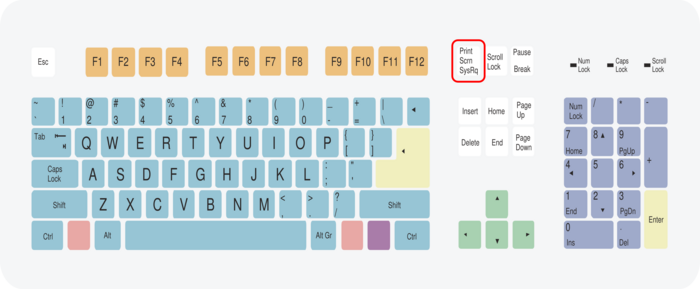
respond to common keyboard and/or mouse input no more — the image
below shows a standard 102-key computer keyboard with the Print screen
key marked in red which, in combination with various other SysRq keys,
determines specific actions taken by the Linux kernel.
sysctl
Sysctl (System control) is an interface for examining and dynamically
changing parameters in a BSD Unix (or Linux) operating system kernel.
There is also a tool named sysctl around —
sysctl (man 8 sysctl) is a
tool used to modify Linux kernel parameters at run time. The
parameters available are those listed under /proc/sys/.
procfs is required for sysctl support in Linux. sysctl can then be
used for both, to read and to write sysctl data. All the configuration
data permanently set with sysctl is stored in /etc/sysctl.conf. So,
what is sysctl actually used/good for? An answer to this question can
be found below...
Linux Kernel Tuning using sysctl
Some of the most notable performance improvements for Linux can be
accomplished via sysctl in /proc/sys. Unlike most other areas of /proc
under Linux, sysctl variables are typically writable and are used to
adjust the running kernel rather than simply monitor currently running
processes and system information.
With this subsection, I will walk us through several areas of sysctl
that can result in large performance improvements. While certainly not
a definitive work, this article should provide the foundation needed
for further research and experimentation with Linux sysctl.
Kernel Version / Date
It is important to know that I am going to use a 2.6 kernel for this
article but parts of the Documentation for sysctl within the kernel
source docs are dated back to v2.2 and v2.4 respectively — however,
the docs are up to date for the most part...
sub:/home/sa# date
Tue Aug 26 09:28:44 CEST 2008
sub:/home/sa# uname -a
Linux sub 2.6.26-1-openvz-amd64 #1 SMP Wed Aug 20 13:06:07 UTC 2008 x86_64 GNU/Linux
sub:/home/sa# lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux unstable (sid)
Release: unstable
Codename: sid
sub:/home/sa#
Working with the sysctl Interface
The sysctl interface allows us to modify variables that the kernel
uses to determine behavior or in short, also known as tuning the
kernel/system ;-]. There are two ways to work with sysctl:
- by directly reading and modifying files in
/proc/sys and
- by using the sysctl program supplied with most, if not all,
distributions like for example Debian
Most documentation on sysctl accesses variables via the /proc/sys file
system, and does so using cat for viewing and echo for changing
variables, as shown in the following example where IP forwarding is
enabled:
sub:/home/sa# cat /proc/sys/net/ipv4/ip_forward
0
sub:/home/sa# echo 1 > /proc/sys/net/ipv4/ip_forward
sub:/home/sa# cat /proc/sys/net/ipv4/ip_forward
1
sub:/home/sa#
This is an easy way to work with sysctl. An alternative is to use the
sysctl utility, which provides an easy interface to accessing sysctl.
With the sysctl program, we specify a path to the variable, with
/proc/sys being the base (pretty much like Apache's documentroot
;-]). For example, to view /proc/sys/net/ipv4/ip_forward, we would use
sub:/home/sa# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
sub:/home/sa#
Then, to update this variable, we use the -w (write) option. With the
example below, I have simply undone what was accomplished earlier when
using cat and echo.
sub:/home/sa# sysctl -w net.ipv4.ip_forward=0
net.ipv4.ip_forward = 0
sub:/home/sa# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
sub:/home/sa#
Deciding which approach to use is often a matter of preference, but
sysctl does have the benefit of being supported via the
/etc/sysctl.conf configuration file, which is read during system
startup. After experimenting with variables that increase the
performance or reliability of the system, we should enter and document
these variables in /etc/sysctl.conf. We can also specify that the
sysctl program reread /etc/sysctl.conf via the -p option i.e. sysctl
-p. In this article, I will typically be using the sysctl utility
syntax for accessing sysctl variables i.e. I will use
net.ipv4.ip_forward rather than /proc/sys/net/ipv4/ip_forward.
Getting to Work
sysctl exposes several important elements of the kernel beneath
/proc/sys, and I will be focusing on
/proc/sys/fs, which are used to tune file system/proc/sys/vm, virtual memory and disk buffers/proc/sys/net, and network code
Of course, there is a lot more available in sysctl than what can be
covered here, so, one might actually use this article as a stepping
stone toward learning more about sysctl.
Tweaking /proc/sys/fs
The /proc/sys/fs interface exposes several interesting variables, but
only a few will directly affect the performance or utilization of our
system. For most workstations or lightly loaded servers, we can
typically leave everything as is, but as our system offers more
services and opens more files, we should begin monitoring fs.file-nr
sub:/home/sa# sysctl fs.file-nr
fs.file-nr = 5248 0 189946
sub:/home/sa#
The fs.file-nr variable displays three parameters:
- total allocated file handles
- currently used file handles and
- maximum file handles that can be allocated.
The Linux kernel dynamically allocates file handles whenever a file
handle is requested by an application, but it does not free these
handles when they are released by the application. Instead, the file
handles are recycled. This means that over time we will see the total
allocated file handles increase as the server reaches new peaks of
file handle use, even though the number of in-use file handles may be
low (or zero as currently on my subnotebook; see above).
If we are running a server that opens a large number of files e.g. a
database server doing financial transactions, a news, or file server,
then we should pay close attention to these parameters when tuning the
system. For example, adjusting the maximum file handles that Linux
will allocate is only a matter of updating fs.file-max:
sub:/home/sa# sysctl -w fs.file-max=200000
fs.file-max = 200000
sub:/home/sa# sysctl fs.file-nr
fs.file-nr = 5312 0 200000
sub:/home/sa#
Here I have set the maximum number of file handles that may be
allocated to 200000, noting that the peak usage is currently topping
out at 5312 file handles. The subnotebook is not used for anything
else than editing this file as of now so its currently used file
handles are zero.
In 2.2 kernels, we would also need to worry about setting a similar
variable for inodes via fs.inode-max, but as of the 2.4, this is no
longer necessary, and indeed this variable is no longer available
under /proc/sys/fs. We can, however, still view information on inode
usage via fs.inode-state.
There are several other variables that can be used in /proc/sys/fs.
However, the 2.4 and 2.6 kernel default values for most variables are
quite sufficient for all but the most extreme cases.
More about /proc/sys/fs can be read in
/path/to/linux_source/Documentation/sysctl/fs.txt. The information is
generally dated to the 2.4 respectively 2.2 kernels but there are some
excellent nuggets of information in the document still usable if not
still up to date for 2.6 — actually, most of the information is up to
date...
Tweaking /proc/sys/vm
-
The following (virtual memory) is not for v2.6 but v2.4 — one has to
use other parameters with v2.6 but then, the principle is the same.
There are two variables under /proc/sys/vm which are quite useful in
tweaking how disk buffers and the Linux VM (Virtual Memory) works with
our disks and file systems. The first, vm.bdflush, allows us to adjust
how the kernel will flush dirty buffers to disk.
Disk buffers are used by the kernel to cache data stored on disks,
which are very slow compared to RAM (Random Access Memory). Whenever a
buffer becomes sufficiently dirty i.e. its contents have been changed
so that it differs from what is on the disk, the kernel daemon bdflush
will flush it to disk. When viewing vm.bdflush we can see several
parameters:
# sysctl vm.bdflush
vm.bdflush = 30 500 0 0 500 3000 60 20 0
Some of the parameters are dummy values. For now, let us pay attention
to the first, second, and seventh parameters (nfract, ndirty, and
nfract_sync, respectively). nfract specifies the maximum percentage of
a buffer that bdflush will allow before queuing the buffer to be
written to disk. ndirty specifies the maximum buffers that bdflush
will flush at once. Finally, nfract_sync is similar to nfract, but
once the percentage specified by nfract_sync is reached, a write is
forced rather than queued.
Adjusting vm.bdflush is something of an art because we need to
extensively test the effect on our server and target applications. If
the server has an intelligent controller and disks, then decreasing
the total number of flushes (which will in turn cause each flush that
is done to take a bit longer) may increase overall performance.
However, with slower disks, the system may end up spending more time
waiting for the flush to finish. For this tweak, we need to test,
test, and then test some more. The default for nfract is 30%, and it
is 60% for nfract_sync. When increasing nfract, we need to make sure
the new value is not equal to nfract_sync:
# sysctl -w vm.bdflush="60 500 0 0 500 3000 80 20 0"
vm.bdflush = 60 500 0 0 500 3000 80 20 0
Here, nfract is being set to 60% and nfract_sync to 80%. The ndirty
parameter simply specifies how much bdflush will write to disk at any
one time. The larger this value, the longer it could potentially take
bdflush to complete its updates to disk.
We can also tune how many pages of memory are paged out by the kernel
swap daemon, kswapd, when memory is needed using vm.kswapd:
# sysctl vm.kswapd
vm.kswapd = 512 32 8
The vm.kswapd variable has three parameters:
tries_base, the maximum number of pages that kswapd tries to free
in one roundtries_min, the minimum pages that kswapd will free when writing to
disk (in other words, kswapd will try to at least get some work
done when it wakes up) andswap_cluster, the number of pages that kswapd will write in one
round of paging
The performance tweak, which is similar to the adjustment made to
vm.bdflush, is to increase the number of pages that kswapd pages out
at once on systems that page often by modifying the first and last
parameters:
# sysctl -w vm.kswapd="1024 32 64"
vm.kswapd = 1024 32 64
Here I am specifying that kswapd frees up to 1024 pages to be paged
out, and that during one round of paging that kswapd can write out 64
pages. There is no hard and fast rule on modifying these parameters as
their effect is very much dependent on disk and HBA (Host Bus Adapter)
I/O (Input/Output). The best bet is to simply experiment until finding
the right value.
Tweaking /proc/sys/net
Unlike the other two areas discussed, /proc/sys/net offers many more
areas where we can tweak and tune our system's performance.
Unfortunately, we can also break our system's compatibility with other
computers on the Internet, so rigorously testing changes is a must. I
will not discuss any changes that can affect compatibility. As with
../fs and ../vm, all changes can be tested simply on the basis of
their performance improvements.
When viewing /proc/sys/net, we will see several different directories:
sub:/home/sa# uname -r
2.6.26-1-openvz-amd64
sub:/home/sa# ls -l /proc/sys/net
total 0
dr-xr-xr-x 0 root root 0 2008-08-25 20:43 core
dr-xr-xr-x 0 root root 0 2008-08-25 20:43 ipv4
dr-xr-xr-x 0 root root 0 2008-08-25 20:43 ipv6
dr-xr-xr-x 0 root root 0 2008-08-25 20:43 token-ring
dr-xr-xr-x 0 root root 0 2008-08-25 20:43 unix
sub:/home/sa#
I am only going to address net.core and net.ipv4. net.core typically
provides defaults for all networking components, especially in terms
of memory usage and buffer allocation for send and receive buffers. On
the other hand, net.ipv4 only has variables that affect the IPv4
stack, and many of the variables, but not all, will override net.core.
When working with net.core and net.ipv4, we should concern ourselves
with three areas:
- new connections
- established connections and
- closing connections
High Latency Connections
When thinking along these lines, it is usually easy to determine which
variables to tune. An excellent example is how Linux will handle
half-open connections. That is, when connections that have been
initiated to the server, but where the three-way TCP handshake has not
completed. We can see connections that are in this state by looking
for SYN_RECV
sub:/home/sa# netstat -nt
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:389 127.0.0.1:52994 TIME_WAIT
tcp 0 1 10.0.0.23:25 10.0.0.93:3432 SYN_RECV
tcp 0 0 10.0.0.8:37785 xxx.xxx.xx.157:6667 ESTABLISHED
tcp 0 0 10.0.0.8:51933 xxx.xxx.xx.83:443 ESTABLISHED
tcp 0 0 10.0.0.8:52626 xxx.xxx.xx.130:5222 ESTABLISHED
tcp 0 0 10.0.0.8:54182 xxx.xxx.xx.98:6667 ESTABLISHED
tcp 0 0 10.0.0.8:49774 xxx.xxx.xx.220:5222 ESTABLISHED
tcp 0 0 10.0.0.8:52158 xxx.xxx.xx.85:9001 ESTABLISHED
tcp 0 0 10.0.0.8:57694 xxx.xxx.xx.116:6667 ESTABLISHED
tcp 0 0 10.0.0.8:39158 xxx.xxx.xx.6.3:6667 ESTABLISHED
tcp 0 0 10.0.0.8:52223 xxx.xxx.xx.159:6667 ESTABLISHED
sub:/home/sa#
When dealing with a heavily loaded service or with clients on high
latency or bad connections, the rate of half-open connections is going
to increase. Web server administrators are particularly aware of this
issue because a lot of Web site clients are still on dial-up
connections. Dial-up tends to have a high latency where clients can
sometimes disappear entirely from the Internet.
In Unix, half-open connections are placed in the incomplete (or
backlog) connections queue, and under Linux, the amount of space
available in this queue is specified by ipv4.tcp_max_syn_backlog.
-
It is important to realize that each half-open connection consumes
memory. Also, realize that a common DoS (Denial of Service) attack,
the syn-flood attack, is based on the knowledge that our server will
no longer be able to serve new connection requests if an attacker
opens enough half-open connections.
For those of us running a site/service which needs to handle a large
number of half-open connections, those should consider increasing this
value:
sub:/home/sa# sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 1024
sub:/home/sa# sysctl -w net.ipv4.tcp_max_syn_backlog=2048
net.ipv4.tcp_max_syn_backlog = 2048
sub:/home/sa# sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 2048
sub:/home/sa#
As a marginal note, many administrators also enable syn-cookies, which
enable a server to handle new connections even when the incomplete
connections queue is full e.g. during a syn-flood attack:
sub:/home/sa# sysctl -w net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syncookies = 1
sub:/home/sa# sysctl net.ipv4.tcp_syncookies
net.ipv4.tcp_syncookies = 1
sub:/home/sa#
Unfortunately, when using syn-cookies, we will not be able to use
advanced TCP features such as window scaling (discussed later).
Number of usable Ports
Another important consideration when connections are being established
is ensuring our server has enough local ports to allocate to sockets
for outgoing connections. When a server, such as HTTP proxy, has a
large number of outgoing connections, the server may run out of local
ports. The number of local ports dedicated to outgoing connections is
specified in net.ipv4.ip_local_port_range, and the default is to
allocate ports
sub:/home/sa# sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 61000
sub:/home/sa#
for this purpose. To adjust these values, we can simply increase this
range e.g. sysctl -w net.ipv4.ip_local_port_range="1024 65535".
Bandwidth (Window Size)
Once a TCP session has been established, we need to think about how
efficiently TCP/IP uses the available bandwidth. One of the most
common ways to increase the utilization is to adjust the possible size
of the TCP congestion window.
The TCP congestion window is simply how many bytes of data the server
will send over a connection before it requires an acknowledgement by
the client on the other end of the connection. The larger the window,
the more data is allowed on the wire at a time, and vice versa. This
is a key point to understand because if we are serving clients on a
high latency network (e.g. a WAN (Wide Area Network) or the Internet),
then our server is probably wasting a lot of network capacity while it
waits for a client ACK.
The congestion window will start at a small size and increase
over time as the server begins to trust the connection. The
maximum size of the window is limited by the size of the send
buffer because the server must be able to resend any data that
is lost, and this data must be in the send buffer to be sent.
Adjusting the buffer size used by Linux is a matter of adjusting both
net.core.wmem_max and net.ipv4.tcp_wmem. net.core.wmem_max specifies
the maximum buffer size for the send queue for any protocol, including
IPv4. net.ipv4.tcp_wmem, on the other hand, includes three parameters:
- the minimum size of a buffer regardless of how much stress is on the memory system
- the default size of a buffer and
- the maximum size of a buffer.
The default size specified in net.ipv4.tcp_wmem will override
net.core.wmem_default, so we can simply ignore net.core.wmem_default.
However, net.core.wmem_max overrides the maximum buffer size specified
in net.ipv4.tcp_wmem, so when changing net.ipv4.tcp_wmem, be sure that
the maximum buffer size specified in net.core.wmem_max is as large or
larger than the maximum buffer size specified by net.ipv4.tcp_wmem.
By default, Linux configures the minimum guaranteed buffer size to be
4K, the default buffer size as 16K, and the maximum buffer size as
419K:
sub:/home/sa# sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 4194304
sub:/home/sa#
We can determine our optimal window by using the bandwidth-delay
product, which will help us find a general range where we should begin
experimenting with congestion window sizes:

Let us say that we determine the congestion window size should be 48K.
We should then adjust the parameters to net.ipv4.tcp_wmem to reflect
this size as the default size for the send buffer:
sub:/home/sa# sysctl -w net.ipv4.tcp_wmem="4096 49152 4194304"
net.ipv4.tcp_wmem = 4096 49152 4194304
sub:/home/sa#
That is all there is to it. Note, however, that historically the
congestion window has been limited to 64K in size. RFC (Request for
Comments) 1323 did away with this limit by introducing window scaling,
which allows for even larger values. TCP window scaling is enabled by
default on the 2.4 and 2.6 kernels
sub:/home/sa# sysctl net.ipv4.tcp_window_scaling
net.ipv4.tcp_window_scaling = 1
sub:/home/sa# sysctl -w net.core.wmem_max="262144"
net.core.wmem_max = 262144
sub:/home/sa# sysctl -w net.ipv4.tcp_wmem="4096 131072 262144"
net.ipv4.tcp_wmem = 4096 131072 262144
sub:/home/sa#
Here I have increased the default buffer size to 128KB, and the
maximum buffer size to double that number, or 256KB. Since the
new default and maximum buffer sizes are larger than the
original value in net.core.wmem_max, I must also adjust that
value as it will override the maximum specified by
net.ipv4.tcp_wmem.
Receive Buffer
One should also investigate net.core.rmem_default, net.core.rmem_max,
and net.ipv4.tcp_rmem, which are variables used to control the size of
the receive buffer. This can make a large impact especially on a
client system, as well as for file servers.
Closing Connections
The final considerations are closing connections. One problem that
servers will face, especially if clients may disappear or otherwise
not close connections, is that the server will have a large number of
open but unused connections.
TCP has a keepalive function that will begin probing the TCP
connection after a given amount of inactivity. By default Linux will
wait for 7200 seconds, or two hours:
sub:/home/sa# sysctl net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_time = 7200
sub:/home/sa#
That is a long time, especially if serving a large number of clients
that only require short-lived connections. Good examples of this are
Web servers. The trick here is to reduce how long a quiet TCP
connection is allowed to live by adjusting net.ipv4.tcp_keepalive_time
to something perhaps along the lines of 15 minutes:
sub:/home/sa# sysctl -w net.ipv4.tcp_keepalive_time=900
net.ipv4.tcp_keepalive_time = 900
sub:/home/sa# sysctl net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_time = 900
sub:/home/sa#
We can also adjust how often the connection will be probed, and how
long between each probe, before a forceful closing of the connection.
But relative to the time specified by net.ipv4.tcp_keepalive_time,
these values are low. Those interested, might review and set
net.ipv4.tcp_keepalive_probes and net.ipv4.tcp_keepalive_intvl.
Conclusion
One of the most critical elements to consider when tuning the kernel
and overall system performance is sysctl. Most use cases can see
dramatic improvements in performance if we know where to look and
perform changes.
The variables mentioned in this article will take folks only so far on
their way to understanding how sysctl affects their system, thus I
invite anybody to learn more by reading the documentation i.e. man 8
sysctl and /path/to/linux_source/Documentation/sysctl/* respectively.
However, it need be said that documentation on sysctl variables is
scarce at best — mostly it simply does not exist because no one
bothered to write it :-/
Linux and its Partition Types
What is a partition? Hard disk drives can be divided into one or more
logical disks called partitions. This division is described in the
partition table found in sector 0 also know as MBR (Master Boot
Record) of the disk. The partition is a devicename followed by a
partition number e.g. /dev/hdb2 where /dev/hdb is the device which
might contain one or more partitions and the trailing number (2 in
this case) indicates a unique partition. In this case /dev/hdb2
denotes the second partition at the second IDE HDD (Hard Disk Drive).
SCSI HDDs or external IDE HDDs connected to the computer via USB cable
would show up as /dev/sda3 i.e. third partition onto the first SCSI
HDD.
-
A partition is self-contained space. What does that mean? That means,
that
/dev/hdc2 might for example contain a complete DebianGNU/Linux
installation, /dev/hdc3 a Windows installation, /dev/hdc1 might be
empty and /dev/hdc5 might have an encrypted filesystem whereas
/dev/hdc6 does not contain any operating system but a filesystem that
can be accessed by all operating systems installed on the third IDE
HDD (/dev/hdc) in our computer. And what about /dev/hdc4?
As mentioned above, every HDD has a MBR (sector 0). This sector
contains the partition table for the whole device. If this data
(usally 512 Bytes) gets messed up or lost, all data onto that
particular device is no more accessible, which, for usual folks is
somewhat equal to the loss of all the data on that particular device.
Sure, there are ways to recover from that worst case scenario but I
wont cover them here (easiest way would be to write back a backup of
the MBR).
So, the MBR contains a partition table which furthermore contains so
called partition descriptors — exactly four of them — one for every
primary partition. Think of them like pointers, pointing from the very
beginning (sector 0) of some HDD to somewhere inside the HDD. This
inside refers to those sectors on a HDD where primary partitions
begin.
There are three partition types:
- primary partitions
- extended partitions
- logical partitions
Per default, the partition numbering is like this:
- Numbers 1 to 4 for primary partitions whether they exist or not
e.g.
/dev/hdc1, /dev/hdc2, /dev/hdc3 and /dev/hdc4.
- Numbers 5 up to maximum for IDE resp. SCSI for logical partitions
e.g.
/dev/hdc5, /dev/hdc6, etc.
An extended partition is a primary partition which could contain up to
60 logical partitions in case of an IDE HDD or 12 in case of an SCSI
HDD. There can only be one extended partition per HDD. That makes 4
primary partitions, one of them an extended partition containing a
maximum of 60 logical partitions for IDE HDDs and 4 primary
partitions one being an extended partition containing 12 logical
partitions for SCSI HDDs. The maximum partition number for IDE HDDs
therefor is 63 (3 primary and 60 logical partitions) and 15 partitions
(3 primary and 12 logical partitions) for SCSI HDDs.
-
/dev/hdc4 in our example is an extended partition containing two
logical partitions /dev/hdc5 and /dev/hdc6. The first partition
descriptor points from the MBR to the beginning of the first primary
partition, the second one to the beginning of the second primary
partition, the third partition descriptor to the third primary
partition and the fourth partition descriptor points from the MBR to
the beginning of the fourth primary partition on /dev/hdc which
actually is an extended patition containing our two logical partitions
/dev/hdc5 and /dev/hdc6.
Each primary and extended partition does have a so called boot sector,
at the very beginning of the partition. This is where partition
descriptors point to — all four start within the MBR and end within a
BS (Boot Sector) of either a primary or an extended partition. A boot
sector contains all information needed to boot an operating system,
make file system I/O (Input/Output) or provide other essential
information.
Each partition, regardless if primary or logical partition, may have
its own file system e.g. ext3, ext2, NTFS, FAT, XFS, etc. Below, is a
table of the types of file systems one can choose from. Each entry has
two columns. The first one is the ID (Identifier) in hexadecimal
notation and the second column is the textual identifier.
01 FAT12 24 NEC DOS 81 Minix / old Linux C1 DRDOS/sec (FAT-12)
02 XENIX root 39 Plan 9 82 Linux swap / Solaris C4 DRDOS/sec (FAT-16 <
03 XENIX usr 3C PartitionMagic recov 83 Linux C6 DRDOS/sec (FAT-16)
04 FAT16 <32M 40 Venix 80286 84 OS/2 hidden C: drive C7 Syrinx
05 Extended 41 PPC PReP Boot 85 Linux extended DA Non-FS data
06 FAT16 42 SFS 86 NTFS volume set DB CP/M / CTOS /...
07 HPFS/NTFS 4D QNX4.x 87 NTFS volume set DE Dell Utility
08 AIX 4E QNX4.x 2nd part 88 Linux plaintext DF BootIt
09 AIX bootable 4F QNX4.x 3rd part 8E Linux LVM E1 DOS access
0A OS/2 Boot Manager 50 OnTrack DM 93 Amoeba E3 DOS R/O
0B W95 FAT32 51 OnTrack DM6 Aux1 94 Amoeba BBT E4 SpeedStor
0C W95 FAT32 (LBA) 52 CP/M 9F BSD/OS EB BeOS fs
0E W95 FAT16 (LBA) 53 OnTrack DM6 Aux3 A0 IBM Thinkpad hiberna EE EFI GPT
0F W95 Ext'd (LBA) 54 OnTrackDM6 A5 FreeBSD EF EFI (FAT-12/16/32)
10 OPUS 55 EZ-Drive A6 OpenBSD F0 Linux/PA-RISC boot
11 Hidden FAT12 56 Golden Bow A7 NeXTSTEP F1 SpeedStor
12 Compaq diagnostics 5C Priam Edisk A8 Darwin UFS F4 SpeedStor
14 Hidden FAT16 <32M 61 SpeedStor A9 NetBSD F2 DOS secondary
16 Hidden FAT16 63 GNU HURD or SysV AB Darwin boot FD Linux raid autodetec
17 Hidden HPFS/NTFS 64 Novell Netware 286 B7 BSDI fs FE LANstep
18 AST SmartSleep 65 Novell Netware 386 B8 BSDI swap FF BBT
1B Hidden W95 FAT32 70 DiskSecure Multi-Boo BB Boot Wizard hidden
1C Hidden W95 FAT32 (LBA) 75 PC/IX BE Solaris boot
1E Hidden W95 FAT16 (LBA) 80 Old Minix BF Solaris
IM, IRC, MUC, Microblogging
This section is about IM (Instant Messaging), IRC (Internet Relay
Chat), MUC (Multi User Chat) and other things like that.
IRC with Pidgin
I, as many others, use IRC (Internet Relay Chat). In order to do so,
one needs to have an IRC client available. There are many IRC clients
out there, all of which have their strength and their weaknesses.
I have been using different clients in the past like for example Irssi
or Conspire. Somehow I settled with ERC and Pidgin. In the following I
am going to talk about Pidgin and how to use it in order to
communicate with other people via IRC. Having that said, Pidgin can be
used for a whole lot more than just IRC — for example instant
messaging via OSCAR (ICQ) or XMPP (Jabber), sending SMS, interacting
with ones microblog (e.g. twitter) and other stuff, all of which is
not part of this short article (visit the Pidgin website for more
information).
The following will basically be about installing Pidgin, doing some
basic configuration, creating an account on some IRC network and
finally creating and registering a so-called nickname for IRC — any
user has a name on IRC — which identifies someone within IRC
channels.
Installation and Configuration
1 sa@wks:~$ type dpl && dpl pidgin* | grep ^ii
2 dpl is aliased to `dpkg -l'
3 ii pidgin 2.4.3-4 graphical multi-protocol instant messaging client for X
4 ii pidgin-data 2.4.3-4 multi-protocol instant messaging client - data files
5 ii pidgin-dev 2.4.3-4 multi-protocol instant messaging client - development f
6 ii pidgin-encryption 3.0-3 pidgin plugin that provides transparent encryption
7 ii pidgin-extprefs 0.7-2 extended preferences plugin for the instant messenger p
8 ii pidgin-festival 2.3-1 pidgin plugin to hear incoming messages using voice syn
9 ii pidgin-guifications 2.14-3 toaster popups for pidgin
10 ii pidgin-hotkeys 0.2.4-1 Configurable global hotkeys for pidgin
11 ii pidgin-libnotify 0.13-2 display notification bubbles in pidgin
12 ii pidgin-otr 3.2.0-2 Off-the-Record Messaging plugin for pidgin
13 ii pidgin-plugin-pack 2.2.0-1 30 useful plugins for pidgin
14 ii pidgin-privacy-please 0.5.1-1 A pidgin plugin for enhanced privacy
15 ii pidgin-sipe 1.2-1 Pidgin plugin for connect to LCS
16 sa@wks:~$
As can be seen in line 3, Pidgin has one core package with some
dependency packages and numerous plugins (lines 6 to 15) which I have
installed already.
Actually, the only package needed for IRC is pidgin. Whatever one
decides to do, after having installed Pidgin with or without some of
its plugins, it should be configured which can be done using the
Preferences, Privacy as well as the Plugins menu from Tools — there
might be more or less to configure depending on what and how much
plugins are installed with core Pidgin...
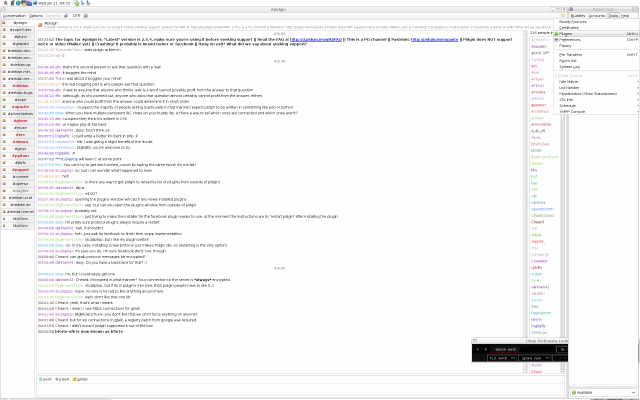
The image above already shows my final setup for pidgin i.e. with
nicknames configured and a bunch of IRC channels that I joined
already. Anybody who just installed Pidgin does not have the left
window yet, only the right one, also known as Buddy List, should be
visible, plus the tray icon at the top that can be used to
expand/collapse the Buddy List.
I am not going to dive deeper into this matter of installing and
configuring Pidgin since all that is probably very different from user
to user and based on personal taste and needs as well as dependent on
the set of installed plugins — the Plugins menu provides good
explanations to any plugin installed plus there are numerous sources
on the web that explain things in detail.
IRC and its Services
Roughly speaking, IRC is provided to us by a compound of servers
(which means they become a so-called IRC network) to which we (humans)
connect using one of the afore mentioned clients (e.g. Pidgin). On
those servers we have so-called Services (basically a bunch of
programs providing various services to humans as they use IRC).
It may also be nice to know that there are many IRC networks, each
carrying numerous channels — in fact, there are around half a million
of existing channels (e.g. #getpaid on irc.freenode.net) on hundreds
of networks (e.g. irc.freenode.net). Anyway, let us stay focused,
shall we :-]... So, why do we need services?
For example, services allow us to ensure that no one else steals our
nickname (ones unique username) on IRC. If somebody would, we could
get services to automatically change their nickname to something else
or kick them off the network (we will see later how to do this).
Services also provide a safe way to control channels including their
ops (also known as operators; a human in charge of one particular
channel with superior permissions e.g. to change the channel topic,
kick users from the channel if they harass others etc.), topics and
modes.
Unlike other methods of controlling operator related things like for
example using our own bot, services are an integral part of the IRC
infrastructure and thus do not need to be given op permissions in
order to op somebody (assign superior permissions to a nickname).
Services are accessed by messaging (more on that later) to them. As of
now there are eight of them:
- NickServ (the only one that asks for a password)
- ChanServ
- MemoServ
- StatServ
- SeenServ
- OperServ
- HelpServ
- Global
Each of these has a complete online help available by messaging them
i.e. typing /msg <service_name> HELP. Note that NickServ is the only
one of these that will ever ask us for a password. If any other
nickname claims to be a service and asks for a password, one should of
course report it the IRC admin(s) immediately (e.g. for freenode by
visiting #freenode on irc.freenode.net). While we can identify to
both, ChanServ and OperServ, they will never say anything more than
just you are not identified for example.
Creating an Account on some IRC Network
What we want is to create an account on e.g. freenode (there are a
bunch of other IRC networks as we already know). In order to do so, we
go to the Buddy List, open Accounts and pick Manage — the management
window appears.
I have already set up accounts on freenode and other networks as can
be seen i.e. someone who just started has an empty management window.
Also, his Buddy List does not show Groups like for example emacs and
so forth — I have already set them up after initially installing and
configuring Pidgin.
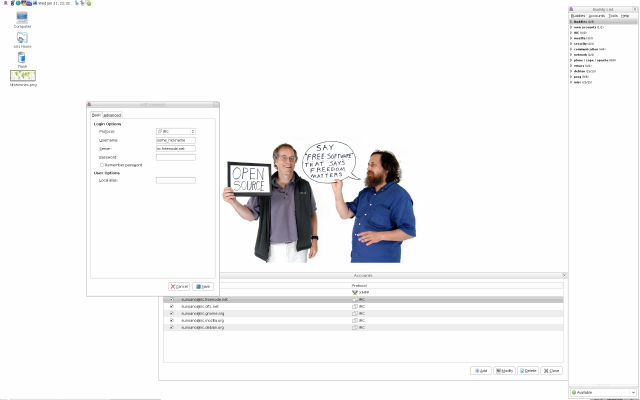
All we have to do now is to pick the correct protocol from the pull
down menu (IRC in our current case), input the networks URL (Uniform
Resource Locator) (irc.freenode.net) and provide a nickname (I have
chosen sunoano to be my nickname on freenode as well as other
networks). The nickname should be chosen wisely — pretty much the
same that applies for user names also applies for nicknames on
some IRC network.
After entering all this information, a click on the Save button should
bring up the chat window i.e. we are now ready to start chatting on
freenode. In case someone else has already joined freenode using the
same nickname, we will be told so — meaning we have to repeat the
process until freenode accepts our nickname i.e. there is no one else
using the same nickname.
Creating and Registering a Nickname
At this point — maybe after trying several times — we should be
online at freenode with some unique nickname. Now we want to make
sure that this nickname is registered. Why is this important?
Well, a nickname is how people on freenode know each other — as in
real life, people have the same name, most of us for their entire
life. If one registers his nickname, he will be able to use the same
nickname over and over again i.e. the nickname gets reserved.
With a registered nickname, used by the same person at all times,
people will begin to know this person by reputation. If we would not
register our nicknames, then someone else may end up registering the
nickname for himself, practically stealing ones identity on IRC.
As mentioned before, after entering the data and pushing the Save
button, a chat window should pop up (see left window in the first
screenshot above) and NickServ (the IRC network's service program)
should talk to us i.e. providing us with some messages with regards to
our nickname, status on the network, etc.
In case this window does not pop up automatically, go to Tools menu in
the Buddy List, chose Room List (a window pops up) and pick
<your_nickname>@irc.freenode.net from the pull down menu. Then push
Get List and wait a few seconds until all channels carried on freenode
are listed within this window. Pick an arbitrary channel and Join it.
Now, there it is, a chat window just appeared.
Whether it is the chat window with NickServ or another one, all are
carried at irc.freenode.net and therefore can be used to register a
nickname. In order to so, we type /msg nickserv register
<your_password> <your_email_address> into the field at the bottom of
the chat window and hit RET. The stuff between < and > need be
replaced to reflect a users individual data i.e. something like /msg
nickserv register EpHwinEY3zevprRPN3Fzfv [email protected] would be
all right. The password needs to be remembered and the email address
to be a valid one.
Freenode will then send an email to this email address with a command
sequence that is used to complete the registration of ones nickname.
As of now, the way this works is, this email contains a line that can
be copy-pasted into the bottom field of the chat window and send to
NickServ by pushing the RET key again. NickServ will respond in its
usual manner with some status message, basically acknowledging that we
have now successfully registered a new nickname on irc.freenode.net.
Only the person with the password used for registration can now use
this nickname. The only thing left now is to identify ourselves
whenever we join irc.freenode.net. This can be done manually every
time we join freenode or, as preferable, automatically carried out by
Pidgin every time we join irc.freenode.net.
The reader may have noticed already, most IRC network services are not
case sensitive with regards to their commands (for nicknames,
passwords, etc. that is another story of course) i.e. it makes no
difference if we would use /msg nickserv register <your_password>
<your_email_address> or /msg nickserv REGISTER <your_password>
<your_email_address>.
Automatically Identifying
We have successfully registered a nickname on irc.freenode.net. Now we
want to automatically identify with freenode every time we fire up
Pidgin. In order to do so, I recommend a plug-in called IRC Helper
which is part of the pidgin-plugin-pack as can be seen below (afs is
just an alias in my .bashrc).
sa@wks:~/mm/new$ afs irchelper | grep so$
pidgin-plugin-pack: /usr/lib/purple-2/irchelper.so
sa@wks:~/mm/new$
If not installed already, one should go ahead and do so. After
installing it, it need be enabled by checking its checkbox under
Plugins from the Tools menu in the Buddy List. Then we use the
Advanced tab and enter NickServ for the authentication service and our
password for the Nick password.
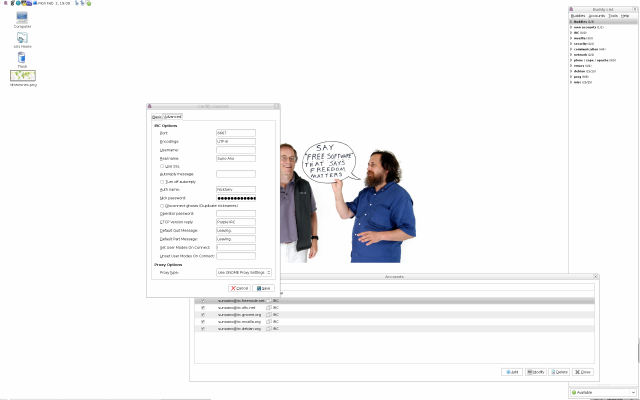
That is all there is to it — after closing Pidgin and starting again
we should be signed on to freenode with our nickname automatically —
we are identified by freenode which can be checked by either using
/whois <our_nickname>, right-mouse button and info, /msg nickserv
status <nickname>, etc. In order to have the full use of ChanServ,
MemoServ and others, we have to be identified to the IRC network in
question so, registering and managing to get identified are a
necessity (at least from my point of view).
Pro-active Protection
At this point we are good to go — the basic setup is done, we have
registered and managed to identify our unique nickname. But what would
happened if we did not identify ourselves?
Well, nothing actually, our nickname is reserved and protected by a
password. However, additional measures can be taken. For example, we
could setup NickServ to guard our nickname and actively prevent others
from using it by using the SET ENFORCE command. When turned on we will
have a minute to identify before NickServ takes action. Action to
prevent what?
For example, if we are offline someone could just do /nick
<our_username> and become... well, us/you... Note, by doing so, he
does not identify himself — he does not have our password — but
still others might not note and so take him as us/you. Surely, that we
do not want.
The action taken after using /msg NickServ SET ENFORCE ON is that
NickServ changes anybodies nickname to something else (e.g. Guest3242)
and thus insures that when we are not logged into IRC, nobody pretends
to be us/you.
In practice this means that no one can use our nickname for more than
a minute without identifying himself (which he needs the password
for). This setting is not enabled by default because it is a pretty
new IRC feature and before it existed, the SET ENFORCE command would
simply kick someone from the network which is a lot more severe.
Switching up a few Gears
That is right ladies and gentleman! Those of you who have made it this
far can consider themselves more or less informed IRC users simply
because already by passing the pro-active protection step from above
we left behind the majority of IRC users.
What follows is probably only used by 10% (or less) of all IRC users
out there. Switching up a few gears also means I am not going to stay
in idiot-proof-writer-mode as I have until now — the rest will be a
short note plus link or accompanying command thingy. All information
needed can be directly accessed by asking one of our eight services
from above e.g. /msg nickserv help. One might try /msg nickserv help
help for example.
So, let us ride... right?! ;-]
- Another thing I can recommend is to use
/msg NickServ SET PRIVATE
ON. As for all the of the following and already mentioned commands,
we use the afore mentioned help command to get more information
about a particular command.
- We can group nicknames. For example, assuming someone has
registered and identified his nickname (
ismoda) then he can become
ismoda_away (another nickname) by issuing /nick ismoda_away. Why
not adding this nickname to his main account i.e. the one holding
ismoda which is registered and identified automatically already. No
problem, /msg nickserv group does the trick. This has the effect,
that it protects any nickname with this group from nickname theft
and other stuff I mentioned earlier. Depending on the IRC network
it might or might not be necessary to register ismoda_away.
- Now is a good time to mention that not IRC networks work the same
way. There are subtle differences with for example what general
policies are in place, what commands can be used and so on. If some
command works on
irc.freenode.net but is not available on for
example irc.oftc.net then that is just the way it is. Some things
are in place on irc.oftc.net but not on irc.freenode.net — we are
only talking about two IRC networks so far...
- From time to time we might want to check our account information.
/msg NickServ INFO <nickname> does just that.
- We can also go through Tor but doing so has a few strings/issues
attached... I used to use Tor for quite some time but decided it
is not worth the troubles e.g. whenever there is an attack coming
from Tor directed towards an IRC network, staffers have to take
measures which is mostly to block any connection requests coming
from Tor. Imho using a cloak (see below) is a good alternative
since most folks considering Tor basically want their IP address
hidden and do not need all the other benefits of using Tor.
- Finally a URL with some of the most useful IRC commands.
Want more? No problem, next we are going to take a look at how to
become invisible... we can cloak ourselves (e.g. to prevent our IP
from showing up when someone uses /whois <nickname> for example),
protecting us from e.g. DoS (Denial of Service) stuff, nosy people,
etc.
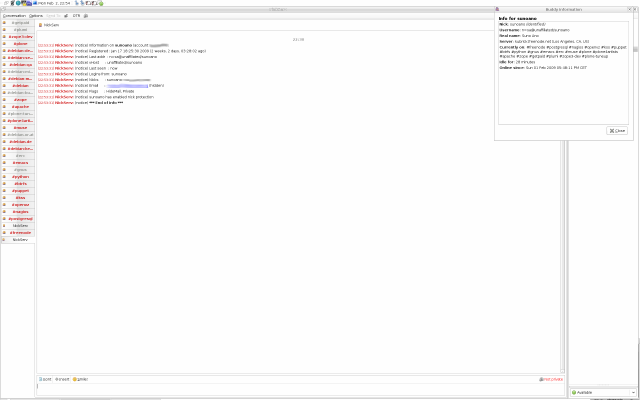
What the image above shows is my account information while my nickname
uses a cloak, having used SET PRIVATE and a few other things. The
commands used to get the information are /msg nickserv info <nickname>
and /whois nickname. From my point of view, we are done setting up
things. Please note that this short article is only about IRC user
related things — it does not cover channel operator nor IRC network
staffer things.
Running our own IRC Channel
In order to have real-time conversations with others, an IRC channel
is the perfect choice — another good choice would be a XMPP based
multi-user chat.
Note that this is different to idea of having one2one conversations
which is called instant messaging — I am talking about on-line
conversations including 3 or more entities. Entities you say? Yes,
entities I say i.e. not just humans.
There may be so-called bots/services that hang out in an IRC channel
as well and provide certain features to us like for example making a
lookup to Google, log all conversations going on in the channel, store
channel specific URLs (Uniform Resource Locators) for quick reference,
etc. There are a lot more features bots/services can provide but then
that is not what this article is about so...
If you have knowledge, let others light their candles at it.
— Margaret Fuller (1810 - 1850)
Intro
With this article I will show how to create the channel named #sunoano
at irc.freenode.net. Freenode is just one of many IRC networks on the
Internet but then it is probably the most popular one when it comes to
matters of FLOSS (Free/Libre Open Source Software), which this
website/platform is all about.
As any other IRC network, Freenode has its guidelines, FAQs and hints
at which one should take a look in order to have the best-possible IRC
experience for himself as well as allowing the whole community to get
the most out of IRC in a friendly and effective manner:
Channel Naming
I already mentioned the channel name #sunoano above. However, it is
important to know a little bit more about Freenode's policy on channel
naming.
Freenode uses an unusual naming convention to indicate the difference
between official (primary) and unofficial (about or topical) IRC
channels. A primary channel is considered appropriate for a channel
operated by a project — for example, the Debian project operates
#debian, the Philadelphia Linux users group operates #plug and so on.
In these examples, these groups have a valid claim to the channel
name. An about channel or topical channel is a channel for a specific
subject or topic, but operated by someone without a claim to the
channel name.
Since we are a group and I have a claim about Sunoano the project, its
legal entity, URLs, etc. we are going to operate #sunoano.
The short version is that official channels (also known as primary
channels) are named starting with one #, unofficial (topical or about
channels) start with ##.
If we are starting a primary channel (as is #sunoano) we will also
need to file a GRF (Group Registration Form) — the actual
registration form can be found here.
It is very important that we file this form as soon as possible, as in
the near future channels without one filed will need to either file or
move to the ## namespace, and new registrations of primary channels
without a GRF filed and accepted will eventually be disabled.
Register a Channel
First thing we need to do is to register the channel #sunoano. In
order to do that, we must posses a registered nickname.
As we know from above, my nickname sunoano is registered so it can be
used to register the IRC channel #sunoano. Next thing to go forward
with our plan is to check whether or not #sunoano is registered
already — in case it were registered already we would need to pick a
different/new name or see what can be done about transferring channel
ownership to us. I am not sure about that... never had to consider it
... I am sure freenode staff knows what to do then.
To check whether a channel has already been registered, we use /msg
ChanServ info #sunoano. When I checked, #sunoano was not registered so
I could proceed.
To create a channel on irc.freenode.net, we just join it using /join
#sunoano. If we are the first person to join that channel, then we
create it by doing so. If we are not then we will join the other
people in there, and we will not be able to register it unless someone
gives us channel owner/operator status — which of course, practically
is never going to happen but technically, that would be the way to go.
In case of #sunoano, I was the first one joining and thereby creating
the channel as can be seen below.
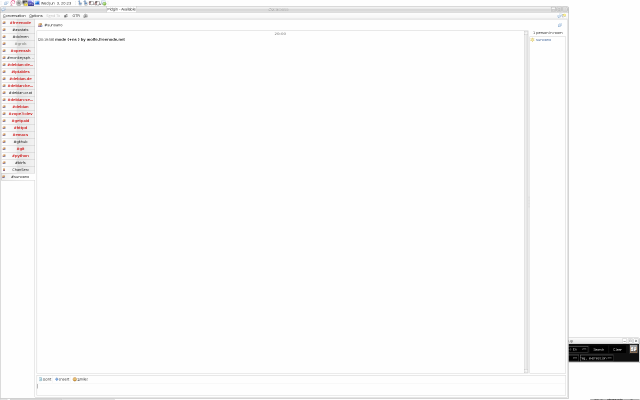
Now we can do what we came for, register #sunoano that is, making
myself (actually my nickname) owner and founder of it which also means
I am the highest authority on #sunoano with regards to permissions
etc. (more on that later). /msg chanserv register #sunoano does the
trick of registering, and thereby binding, #sunoano to my nickname
sunoano.
Just in case we wanted to unregister #sunoano for some reason, /msg
chanserv drop #sunoano would do the trick. The channel #sunoano would
then be on the market again i.e. available for anybody to register. Of
course, he would have to file a GRF but from a technical point of
view, the channel would be available again.
Take back what is Yours
Assuming the worst happened, /msg chanserv recover #sunoano would
allow me to regain control of our channel again in the event of a
takeover by hostiles.
More precisely, everyone will be deopped, limit and key will be
cleared, all bans matching the nickname sunoano itself (channel
owner/founder) are removed, a ban exception matching sunoano is added
(in case of bans #sunoano cannot see because they might be enforced by
another, external bot or something like that), the channel is set
invite-only and moderated and sunoano is invited.
Configure our IRC Channel
Now comes the main part — we are going to set a few settings in
addition to the default ones set already (see templates further down).
First, if we want to have ChanServ watch our channel, we use /msg
chanserv set #sunoano guard on.
Then we want to have an entry message /msg chanserv set #sunoano
entrymsg Welcome to Markus's IRC channel, the place for real-time
discussions with regards to . Use /topic to see
what's on the menu for today ;-].
Having a topic so people know what is going on is also very important
/msg chanserv topic #sunoano website::
and to make it stick /msg
chanserv set #sunoano keeptopic on plus protect it /msg chanserv set
#sunoano topiclock on so only channel operators can change it.
Last but not least, for the more-paranoid, /msg chanserv set #sunoano
secure on should let them sleep better. We can now issue /msg chanserv
info #sunoano which will show us
[(notice) Information on #sunoano:]
[(notice) Founder : sunoano]
[(notice) Successor : (none)]
[(notice) Registered : Jun 03 21:10:41 2009 (1 day, 09:57:48 ago)]
[(notice) Mode lock : +ntc-slk]
[(notice) Flags : SECURE KEEPTOPIC TOPICLOCK GUARD]
[(notice) *** End of Info ***]
We have now gone trough and thereby set the most important settings.
Any channel operator and such should read the whole /msg chanserv help
commands part of course to further educate himself.
Deal with troublesome People
Last but not least, the most unfortunate part we have to educate
ourselves with i.e. what to do with regards to hostile behavior like
for example users spamming our channel or harassing other users?
There is a lot we can do about it technically like for example make
him quiet, kick or ban him. However, this should only be a measure of
last resort because first and foremost should a channel owner/operator
be an utter relaxed person with social skills that can pretty much
resolve and de-escalate any problematic situation. We refer to such
people as catalysts.
However, if it does not seem to lead anywhere in a reasonable amount
of time (say 10 minutes) and the annoying schmuck (e.g. user
nasenbaer) keeps launching any possible harassment we can think of and
behaves bad, why not make him quiet /msg ChanServ quiet #sunoano
nasenbaer for a while. If he cools down after a day or so, we may
reverse it with /msg ChanServ unquiet #sunoano nasenbaer. Of course,
we must be a channel operator or a higher authority (founder/owner) to
do that.
We could also kick or even ban him but then I have learned over the
years that, if we have to do something pro-active i.e. when talking
sense into that person just does not work, then making the user quiet
is way better than kicking or banning him. If we kick or ban him we
just fuel his anger even more and trust me, he will be back one way or
the other...
By just making him quiet, there is no
being-excluded-talking-behind-my-back feeling for him because he can
still read everything in the channel plus stay there until we reverse
the quiet command. If that also does not help, we can still ban him,
inform the network staff even so he might be banned from the entire
network — not being able to go on Freenode hurts everybody no matter
what!
Channel Flags/Modes Templates and Access Lists
Flags are the basic building-blocks that drive the permission/user
framework on IRC channels.
Depending on which flags a user has set on his nickname, he can apply
modes and thus carry out certain tasks like for example, change the
topic, kick troublesome users off the channel, manage core-channel
settings etc.
We can issue /msg chanserv help flags in order to get a detailed
listing of available flags. How to set/unset them on particular users
respectively build our own templates is shown below.
Access List
Every IRC channel has an access list — basically, a list about who
can do what on a particular channel e.g. #sunoano.
By default the only entry on the access list will be the founder
itself (sunoano in our current case). We can add others at any level,
below the founder, if they have registered their nickname.
With /msg chanserv access #sunoano list we can take a look at the
access list for #sunoano
[(notice) 1 sunoano +votsriRfAF [modified 1 day, 17:38:19 ago]]
We can then add the user frank with /msg chanserv access #sunoano add
frank HOP, using a template (HOP, see below). Of course, we can also
remove frank again later on if we want/need to after he got added to
the access list i.e. we gave/granted him elevated powers/permissions
on #sunoano. For more information, see /msg chanserv help access.
While the above was about the channel point of view, it is also
important to know that we have a user point of view available.
This is important for the simple reasons, that we might not have
permissions to see the channel access list with all entries for all
other users.
/msg chanserv status #sunoano returns You have access flags
+votsriRfAF on #sunoano. This way we can at least see our own
flags/modes within #sunoano.
Templates
We do not want to set flags and modes over and over again manually.
Rather, we want to reuse particular combinations of flags and modes
which we consider serve our purpose best. For example, /msg chanserv
template would show network-wide templates we can use
[ Name [Flags]
[ -------------------- -----]
[ SOP +voOtsrifA]
[ AOP +voOtriA]
[ HOP +vVtA]
[ VOP +VA]
[ -------------------- -----]
[ End of network wide template list.]
/msg chanserv template #sunoano would show those templates currently
available for #sunoano
[(notice) -------------------- -----]
[(notice) OP +votriA]
[(notice) MANAGER +votsriRfA]
[(notice) -------------------- -----]
In both cases, we have a list of flags (e.g. voOtsrifA) that make up
for the template. The leading + indicates that they are set.
Now, those were predefined templates but we can of course build our
own for later reuse. For more information on the matter, please take a
look at /msg chanserv help template.
Microblogging with Pidgin
I use http://code.google.com/p/microblog-purple/wiki/README to put my
tweets at http://twitter.com/sunoano.
What I did in a nutshell: download and extract the tar.gz to /tmp.
Change into this directory. As root, make && make install.
Restart/start pidgin. Enable twitter plugin menu via tools menu —>
plugins. Add new account, account type twitter. Provide twitter
username and password. Make pidgin store twitter password using the
checkbox. That is it...
Update: Since about August 2009 there is the pidgin-microblog
available to get this working i.e. no need to install it manually.
Instant Messaging / Multi User Chat
WRITEME
Iceweasel Add-ons
For those who do not know what Iceweasel is please click here. Also
note, that the FSF (Free Software Foundation) has got its own
Iceweasel web browser (I am using Debians Iceweasel). Both projects,
Debians and FSFs Icweasel have nothing to do with each other — not
until now (June 2007) — however it seems a merger is planned...
I use the following add-ons with Iceweasel:
sa@pc1:~/.mozilla/firefox/xjlg0mai.default$ grep -i ns1:name extensions.rdf | gawk -F \" '{print $2}' | sort
Adblock
Aquatint
Bookmark Duplicate Detector
Clear Cache Button
Closy
Context Style Switcher
Cooliris Previews
CSSViewer
Extension Manager Extended
Fasterfox
FaviconizeTab
Firebug
FireFoxMenuButtons
FlashGot
Forecastfox
FormFox
FoxClocks
FoxyProxy
Html Validator
Iceweasel (default)
iMacros for Firefox
ImageBot
Link Alert
Locate in Bookmark Folders
MozCC
Noia 2.0 (eXtreme)
NoScript
OpenBook
Orkut Scrap Helper
Paragrasp
PDF Download
SafeCache
Sage
ScrapBook
Screen grab!
SearchLoad Options
Selenium IDE
ShowIP
StockTicker
Tab Counter
Tab Mix Plus
Toolbar Buttons
TrackMeNot
Update Notifier
User Agent Switcher
Web Developer
sa@pc1:~/.mozilla/firefox/xjlg0mai.default$
you can get them at mozillas add-on page. Note, the above screendump
also lists my installed themes i.e. Iceweasel (default) and Noia 2.0
(eXtreme). A must-have is the NoScript, Tab Mix Plus, FaviconizeTab
and Cooliris Previews I would say. ScrapBook is for the always on the
go folks to take with them some websites when being without
connectivity to the Internet.
The others are quite nice to have though. Finally, If you want to
provide images to folks on IRC (Internet Relay Chat)/IM (Instant
Messaging) or just love to sprinkle some expandable thumbnails into
some bulletin board you would not miss the powers of ImageBot.
And last but not least two images. The first one shows icweasel with
sage feed reader at the left-hand site and the main window on the
right. The second one is the bookmarks panel instead of sage feed
reader. Bookmarks are very important to me — I have
sa@sub:~$ grep -E 'ftp|http' .mozilla/firefox/xjlg0mai.default/bookmarks.html | wc -l
3211
sa@sub:~$
bookmarks although I am using Bookmark Duplicate Detector. What can I
say... I have them well organized into categories, subcategories and
so on. The number steadily grew over the years — pretty fast at the
beginning when I started out with iceweasel (if I recall correctly,
that was in 2003) but has now come to a normal level of new entries
per day. Now they are part of my daily working habits and I can simply
not be without them.
 |
| Fullscreen Iceweasel with Sage on the left |
 |
| Upper left corner showing some bookmarks |
The only crazy thing about iceweasel respectively firefox is the
amount of RAM (Random Access Memory) they need to work quite well
sa@pc1:~$ ps aux | egrep 'USER|icewe' | grep -v grep
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
1000 27795 5.4 17.7 296588 184012 pts/0 Sl 06:01 34:28 /usr/lib/iceweasel/firefox-bin -a firefox
sa@pc1:~$
Wow, that is ~ 184 MiB RAM usage (~ 296 MiB of virtual memory in
total). Whatever, I don't care, the next web-shop has to provide one
more GiB of RAM to me. As of now (June 2007) I have 1 GiB RAM but will
soon upgrade or better get a whole new velociraptor-like workstation;
4 CPU cores or more, 4 GiB RAM or more, some TiBs diskspace, all
spiced up with a hardware RAID controller of course.
Smoothen Filenames
I am going to show how to smoothen (renaming that is) file/directory
names of our beloved audio/movie/image/etc. collection. In order to
demonstrate that, I am going to use my music collection as well as a
movie. As can be seen, I have a bunch of mp3 files
sa@wks:~/mm/audio$ find music/ -type f -name *.mp3 | wc -l && du -sh music/
12211
68G music/
sa@wks:~/mm/audio$
So, as we can see, I have around ~12000 mp3's (no duplicates since I
use fslint and fdupes) but it happens that filenames as well as
directory names look very ugly like for example
/home/sa/mm/audio/music/Pop-Rock.260kbps@lunar? by frank/Katie Melua very cool!!/katie melua call off the search Bonus Album Discography/2004 my aphrodisiac is you.mp3
whereas I would prefer
/home/sa/mm/audio/music/poprock/katie_melua/call_off_the_search/my_aphrodisiac_is_you.mp3
What would certainly not work with around ~12000 files is doing all
the smoothening manually. Because of that, the recursive find approach
shown below helps a lot since it descends down from the top of our mp3
collection, renaming files/directories all along its way. However, it
still is a semiautomatic approach since moving files/directories
around and doing the final cosmetics on file/directory renaming must
be done manually which I do using wdired but then that is another
story...
sa@wks:~$ cd mm/audio/music/
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/[[:space:]]/_/g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 'y/A-Z/a-z/' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/-/_/g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/__/_/g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename "s/20[0123456789][0123456789]//g" {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename "s/19[0123456789][0123456789]//g" {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/discografia//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/discografie//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/discography//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/^_//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename "s/^_//g" {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/collection//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/albums//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/album//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/alben//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/net_//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/_net//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/www//g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename 's/__/_/g' {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename s/^_// {} 2> /dev/null \;
sa@wks:~/mm/audio/music$ find . -type d -execdir rename s/_$// {} 2> /dev/null \;
Please note that -type d from above only alters directory names in a
recursive manner. In order to also smoothen mp3 filenames itself we
would use -type f instead.
-
Bottom line is, the above is not perfect but good enough to transform
a huge collection of video/audio/image/etc. data into some better
looking bunch of data.
-
I am thinking that maybe I am going to write some python code to not
just only do the smoothening on filen and directory names but to also
enable some automatic moving around of directories e.g.
../a/b/b/c/my_file.mp3 into ../a/b/c/my_file.mp3. All that hooked into
a central service on the net where folks can input the ugly strings
that we do not want to have within our file and/or directory names
like for example kbps and the like (see below). The local python code
might then update itself with the central service and as time goes by,
the central database of strings to remove would grow so that whatever
we download and whatever that looks like, after the python code
finished, all would look real nice because it got smoothened.
Example Shell Script
What does it do? Well, it removes ugly strings and characters we do
not want contained in our file/directory names. It is a handy script
of mine which I hacked together in a hurry during a train ride.
However, it does a good job to me which is removing ugly strings from
file and directory names. Any of the rename commands from below can of
course be combined with the above find.
#!/bin/sh
#
# License: GPL v3
#
# Name: /usr/local/bin/my_file_rename_helper.sh
#
# Purpose: The code below renames file and directory names in the
# current working directory.
rename 'y/A-Z/a-z/' * &&\
rename 's/[[:space:]]/_/g' * &&\
rename 's/[[:cntrl:]]/_/g' * &&\
#rename 's/[[:punct:]]/_/g' * &&\ # this one is very powerfull if uncommented
rename 's/\204/ae/g' * &&\
rename 's/\224/oe/g' * &&\
rename 's/\201/ue/g' * &&\
rename 's/\341/ss/g' * &&\
rename 's/\351//g' * &&\
rename 's/\205//g' * &&\
rename 's/\225//g' * &&\
rename 's/\240//g' * &&\
rename 's/-/_/g' * &&\
rename 's/\./_/g' * &&\
rename 's/\:/_/g' * &&\
rename 's/\?//g' * &&\
rename 's/\!//g' * &&\
rename 's/,//g' * &&\
rename "s/\'//g" * &&\
rename 's/\`//g' * &&\
rename 's/\)//g' * &&\
rename 's/\(//g' * &&\
rename 's/\[//g' * &&\
rename 's/\]//g' * &&\
rename 's/__/_/g' * &&\
rename 's/__/_/g' * &&\
# file extensions and the like
rename 's/_avi$/\.avi/g' * &&\
rename 's/_mpg$/\.mpg/g' * &&\
rename 's/_mpeg$/\.mpeg/g' * &&\
rename 's/_wmv$/\.wmv/g' * &&\
rename 's/_asf$/\.asf/g' * &&\
rename 's/_mp3$/\.mp3/g' * &&\
rename 's/_rar$/\.rar/g' * &&\
rename 's/_zip$/\.zip/g' * &&\
rename 's/_tar$/\.tar/g' * &&\
rename 's/_pdf$/\.pdf/g' * &&\
rename 's/_doc$/\.doc/g' * &&\
rename 's/_odt$/\.odt/g' * &&\
rename 's/hdrip//g' * &&\
rename 's/_ac3_//g' * &&\
rename 's/hdrip//g' * &&\
rename 's/dvdrip//g' * &&\
rename 's/dvd//g' * &&\
rename 's/rip//g' * &&\
rename 's/divx//g' * &&\
rename 's/vid//g' * &&\
rename 's/xvid//g' * &&\
rename 's/__/_/g' * &&\
# languages
rename 's/_english_//g' * &&\
rename 's/_eng_//g' * &&\
rename 's/_ita_//g' * &&\
rename 's/_french_//g' * &&\
rename 's/_italian_//g' * &&\
rename 's/_spanish_//g' * &&\
#dates
rename "s/20[0123456789][0123456789]//g" * &&\
rename "s/19[0123456789][0123456789]//g" * &&\
# random stuff
rename 's/^img_//g' * &&\
rename 's/^mvi_//g' * &&\
rename 's/dcam//g' * &&\
rename 's/hdtv//g' * &&\
rename 's/_fov//g' * &&\
rename 's/_0tv//g' * &&\
rename 's/_fqm//g' * &&\
rename 's/_unseen//g' * &&\
rename 's/_2hd//g' * &&\
rename 's/para_spanishred/_/g' * &&\
rename 's/integrados/_/g' * &&\
rename 's/subtitulos/_/g' * &&\
rename 's/sub_fr_kiki/_/g' * &&\
rename 's/real_proper_dot/_/g' * &&\
rename 's/v_o_/_/g' * &&\
rename 's/_hr_/_/g' * &&\
rename 's/_aaf/_/g' * &&\
rename 's/_dot\./\./g' * &&\
rename 's/real_proper\./\./g' * &&\
rename 's/_proper\./\./g' * &&\
rename 's/_internal\./\./g' * &&\
rename 's/_repack\./\./g' * &&\
rename 's/_bluetv\./\./g' * &&\
rename 's/rogue//g' * &&\
rename 's/_mint\./\./g' * &&\
rename 's/_crimson\./\./g' * &&\
rename 's/_lol//g' * &&\
rename 's/_hv//g' * &&\
rename 's/_topaz//g' * &&\
rename 's/_wat_//g' * &&\
rename 's/_rebirth\./\./g' * &&\
rename 's/_savannah//g' * &&\
rename 's/jericho_//g' * &&\
rename 's/megastructures_//g' * &&\
rename 's/mega_cities_//g' * &&\
rename 's/^lost_//g' * &&\
rename 's/^californication_//g' * &&\
rename 's/^eureka_//g' * &&\
rename 's/^2004_//g' * &&\
rename 's/heroes_//g' * &&\
rename 's/sopranos_the_//g' * &&\
rename 's/_saints//g' * &&\
rename 's/weeds_//g' * &&\
rename 's/prison_break//g' * &&\
rename 's/my_name_is_earl_//g' * &&\
rename 's/terminator_the_sarah_connor_chronicles_//g' * &&\
rename 's/the_unit//g' * &&\
rename 's/unit_the//g' * &&\
rename 's/dexter_//g' * &&\
rename 's/firefly_//g' * &&\
rename 's/l_word_the//g' * &&\
rename 's/veronica_mars//g' * &&\
rename 's/the_l_word//g' * &&\
rename 's/^house_//g' * &&\
rename 's/closer_the//g' * &&\
rename 's/the_closer//g' * &&\
rename "s/big_bang_theory//g" * &&\
rename 's/battlestar_galactica_//g' * &&\
rename 's/stargate_atlantis_//g' * &&\
rename 's/the_dresden_files_//g' * &&\
rename 's/globe_trekker_//g' * &&\
rename 's/lonely_planet_//g' * &&\
rename 's/pilot_guides_//g' * &&\
rename 's/ultimate_//g' * &&\
rename 's/military_channel_//g' * &&\
rename 's/discovery_channel//g' * &&\
rename 's/history_channel//g' * &&\
rename 's/documentary_//g' * &&\
rename 's/shareproer//g' * &&\
rename 's/discografia//g' * &&\
rename 's/discographia//g' * &&\
rename 's/tvu_org_ru//g' * &&\
rename 's/notv//g' * &&\
rename 's/pdtv//g' * &&\
rename 's/__/_/g' * &&\
# distributor tags
rename 's/alliance//g' * &&\
rename 's/uncensored//g' * &&\
rename 's/diamond//g' * &&\
rename 's/shareprovider_//g' * &&\
rename 's/oslonet//g' * &&\
rename 's/__/_/g' * &&\
# Top level domains
rename 's/\.com//g' * &&\
rename 's/_com//g' * &&\
rename 's/\.net//g' * &&\
rename 's/\.org//g' * &&\
rename 's/__/_/g' * &&\
# misc
rename 's/\&//g' * &&\
rename 's/^_//g' * &&\
rename 's/xx//g' * &&\
rename 's/_x//g' * &&\
rename 's/^x_//g' * &&\
rename 's/__/_/g' * &&\
# map resp. remap identifier
rename 's/cd1/aaaa/g' * &&\
rename 's/cd_1/aaaa/g' * &&\
rename 's/cd2/bbbb/g' * &&\
rename 's/cd_2/bbbb/g' * &&\
rename 's/cd3/cccc/g' * &&\
rename 's/cd_3/cccc/g' * &&\
rename 's/.m4v$/dddd/' * &&\
rename 's/.mp3$/eeee/' * &&\
rename 's/.info$/gggg/' * &&\
rename 's/.jpg$/ffff/' * &&\
rename 's/.png$/hhhh/' * &&\
rename 's/dddd/.m4v/' * &&\
rename 's/cccc/_3/g' * &&\
rename 's/bbbb/_2/g' * &&\
rename 's/aaaa/_1/g' * &&\
rename 's/eeee$/.mp3/' * &&\
rename 's/gggg$/.info/' * &&\
rename 's/ffff$/.jpg/' * &&\
rename 's/hhhh$/.png/' * &&\
#final cleanup
rename 's/__/_/g' * &&\
rename 's/__/_/g' * &&\
rename 's/__/_/g' * &&\
rename 's/^_//g' * &&\
rename 's/_$//g' * &&\
rename 's/_\./\./g' *
Example Usage
Aside from e.g. find . -type d -execdir rename 's/_net//g' {} 2>
/dev/null \; to transform one huge pile of new data in a recursive
manner, I use the script from above by changing into the directory
with the newly dowloaded files and invoke it
1 sa@wks:~$ type fr
2 fr is aliased to `/usr/local/bin/my_file_rename_helper.sh'
3 sa@wks:~$ cd mm/new/files/
4 sa@wks:~/mm/new/files$ ll
5 total 1.8G
6 -rw------- 1 sa sa 350M 2008-10-26 19:32 House - 5x05 - Lucky Thirteen.avi
7 -rw------- 1 sa sa 351M 2008-10-29 09:00 Stargate.Atlantis.5x01.Search.And.Rescue.REPACK.HDTV.XviD-FoV.[tvu.org.ru].avi
8 -rw------- 1 sa sa 351M 2008-10-29 05:35 Stargate.Atlantis.5x02.The.Seed.HDTV.XviD-0TV.[tvu.org.ru].avi
9 -rw------- 1 sa sa 350M 2008-10-29 04:38 Stargate.Atlantis.5x03.Broken.Ties.HDTV.XviD-0TV.[tvu.org.ru].avi
10 -rw------- 1 sa sa 350M 2008-10-29 04:31 Stargate.Atlantis.5x04.The.Daedalus.Variations.HDTV.XviD-0TV.[tvu.org.ru].avi
11 sa@wks:~/mm/new/files$ fr
12 sa@wks:~/mm/new/files$ ll
13 total 1.8G
14 -rw------- 1 sa sa 351M 2008-10-29 09:00 5x01_search_and_rescue.avi
15 -rw------- 1 sa sa 351M 2008-10-29 05:35 5x02_the_seed.avi
16 -rw------- 1 sa sa 350M 2008-10-29 04:38 5x03_broken_ties.avi
17 -rw------- 1 sa sa 350M 2008-10-29 04:31 5x04_the_daedalus_variations.avi
18 -rw------- 1 sa sa 350M 2008-10-26 19:32 5x05_lucky_thirteen.avi
19 sa@wks:~/mm/new/files$
All the just shown code works perfectly fine. However, I hacked it
together on some train ride in a quick and dirty manner — a proof of
concept so to say. I think I will consolidate all that functionality
into one piece of python code some time in the future in order to make
it a decent piece of software and not just an ugly temporary hack ;-]
Note, if the script would be renamed to fr, then we would not even
need the alias in ~/.bashrc as can be seen in line 2. In short, mv
/usr/local/bin/my_file_rename_helper.sh /usr/local/bin/fr would make
the shell alias superfluous. I tend to prefer this in most cases when
there is no clash in command/file names, which I have not with gllol
for example.
|








